Сегодня я расскажу Вам о наиболее распространенных вариантах утечки различной информации в паблик. Уверен, что многие сталкивались с подобного рода проблемами и знают о них не понаслышке, — тема утечки данных не новая, но до сих пор очень актуальная и активно используемая, а методы отточены годами. Но, несмотря на это, думаю, вы сегодня обязательно найдете для себя что-то новое. Я покажу вам основные причины которые приводят к утечке данных и методы их устранения.
Начнем с самого элементарного и поговорим начистоту. Некоторые администраторы оставляют в корневом каталоге либо в папочках типа backup, dump резервные копии базы данных или архивы с исходниками к сайту. Ну или и то и другое.
Разумеется, береженого бог бережет, но все же часто такая практика приводит к тому, что скачать их может любой желающий. Утечки бэкапов вообще очень частое явление, несмотря на всяческие предупреждения со стороны. Самый простой способ заполучить базу данных сайта — это найти ее. По одному запросу в гугле вида «phpMyAdmin SQL Dump» filetype:sql уже около миллиона страниц. И это только те, которые были сделаны менеджером phpMyAdmin и которые проиндексировались! Такой же дорк можно составить к бэкапам в виде архивов, что-то типа inurl:backup filetype:gz. Я надеюсь, ты знаешь, как работать с гуглом. Если не очень, вот тебе подсказка:
• intext — ведет поиск по тексту внутри страницы;
• intitle — ищет в заголовке (title);
• inurl — смотрит в пути к файлу (url);
• filetype — определяет тип файла, который нам нужен.
Ну и с помощью site: выбираем цель, которую будем доркать. В нем можно указать отдельный домен, например site:ru — поиск по всем сайтам с доменом верхнего уровня ru или site:ya.ru — поиск по сайту и его поддоменам. Те же бэкапы можно поискать и таким дорком — inurl:backup
intitle:»index of» intext:»last modified».
Кстати говоря, с точки зрения законодательства эта информация уже является публичной, и, по идее, твои руки будут чисты. Главное — доказать, что информация уже не была приватной (именно доказать), что, в общем-то, легко при наличии ссылки в гугле. Однако, если ты нашел линки вида
/dump/backup_2012.tar.gz и /dump/backup_2013.tar.gz,
которые уже были недоступны, а ты по логике решил проверить такой же файл, но уже с датой 2014, — за тобой могут выехать.
Вот, казалось бы, папка dump закрыта от пользователей и посмотреть содержимое нельзя, бэкап содержит хеш и вообще не брутабельный — My_Super_Mega_Dump-402051f4be0cc3aad33bcf3ac3d6532b-2014-07-03-12-54.sql. Как, черт возьми, эти ссылки попадают в поисковики? Мой ответ — Chrome.
Да-да, он часто сует свой нос (или что там у него) куда его не просят. Хром, как заслуженный шпионский браузер, внимательно следит за ссылками, отправляет их себе, а потом смотрит, если в robots.txt не указано, что это индексировать нельзя, — welcome в выдачу гугла!
Я даже как-то писал статью про уязвимости PayPal, зашел на главную страницу, сохранил (Ctrl + s), изменил пути и сохранил как paypal.html. Некоторое время спустя я начал записывать видео с демонстрацией уязвимости, залил в директорию блога, зашел на эту страничку с помощью хрома, записал. Но вдруг, откуда ни возьмись, ко мне зашел робот гугла и…
На следующий день мой домен был в черных списках как фишинговый. Пришлось потом долго очищать свою карму, хотя, с другой стороны, это довольно интересная защита от настоящих фишинговых атак.
Хочу отметить, что robots.txt против гугла помогает не всегда. Ты же видел ссылки, у которых в выдаче подпись «запрещено в robots.txt»? Обычно туда попадают ссылки, которые были указаны в HTML-теге на какой-нибудь страничке. Быть может, у тебя приватная переписка, где ты кидаешь ссылку товарищу на приватный документ на сайте, индексирование которого запрещено. А тут на тебе — документ в поисковике, правда, он не попадет в кеш, но оно и не надо, кто искал — тот нашел. Ну, хром далеко не единственный в таком роде, возможны и другие «сливальщики» информации, будь то плагины или (а почему бы и нет?) антивирусы и прочее стороннее ПО.
Исправляем: Разумеется, лучше хранить бэкапы на уровень выше, чем директория сайта. А если уж прям так нужно, чтобы резервные копии находились в корне, — лучше доступ запретить по IP или хотя бы надежно запаролить.
Саму идею уже рассказывал мой приятель 090h в статье на Хабре (bit.ly/SI2rXZ), да и много софта проплывало на эту тему. Идея состоит в том, что многие выкладывают на файлообменники свои приватные файлы, будь то сбрученные/взломанные аккаунты, различные конфиги, бэкапы, фотографии, паспорта, сиськи и все такое прочее. Легкость получения этих данных состоит в том, что в ссылке на файл уникальный идентификатор состоит из цифр, поэтому легко предсказать номер следующего залитого файла и, разумеется, предыдущего. Также многие анонимусы выкладывают текстовые дампы на pastebin.com, и существуют даже боты по поиску (специально для тебя я составил список ботов, следящих за утечками: bit.ly/1hSYprS), я даже видел исходнички подобного бота. История та же — данные публичные, и сбрутить идентификатор документа не составляет труда. Еще я заметил, что бывают интересные взломы государственных сайтов (например, как-то проплывали логопасы ФБР), но существуют эти документы в течение
нескольких часов, поэтому такую тему нужно мониторить и сохранять, а только потом модерировать. К этой же теме можно отнести поиск по публичным файлам социальной сети vk.com, заходим на https://vk.com/docs, вводим в поиск паспорт.jpg и любуемся симпатичными (и не очень) фотографиями владельцев сканов.
Эти документы публичные, поэтому доступны всем. Если ты передаешь приватный документ с помощью личного сообщения — он сохраняется как приватный файл. Хотя это ни о чем не говорит, он всего лишь недоступен для поиска, а как получать их, я покажу тебе чуть позже.
Исправляем: Хотя тут нечего исправлять. Выкладывая свои приватные файлы на сайт, ты уже передаешь их третьим лицам, поэтому, если уж надо обменяться или сохранить файлы в каком-то сервисе, хорошо бы их предварительно зашифровать.
Начну с небольшой предыстории. Однажды я решил добавить блог в рейтинг блогеров (прошу прощения за тавтологию). Смысла в этих действиях было немного, хоть раньше это и было популярно, но все же я это сделал. Так как блог проходит модерацию, я иногда смотрел referer’ы (страницы, с которых переходили посетители), чтобы узнать, кто и откуда идет ко мне. Как-то попалась страничка одного из модеров Яндекса (какой-то поддомен, уже не помню), однако зайти туда, как простому смертному, не удалось. Но однажды я увидел, что на мой сайт перешли с одного рейтинга, урл которого имел вид
site/?act=manage&session=8e3cba18a3a6a3aa51e160a3d1e1ebcc
Перейдя на страницу, я попал в админку того самого рейтинга блогеров, поигрался циферками и в результате стал самым крутым блогером по версии этого рейтинга. Правда, всего на один день.
Итак, что за ерунда только что произошла? Начнем с азов. Когда пользователь (посетитель) заходит на сайт, сервер присваивает ему сессию, уникальный ключ для идентификации пользователя. Он служит для того, чтобы различить вновь вошедшего анонимуса от, например, админа сайта. Есть два варианта, почему сессия может «утечь». Первый — это «так надо», то есть разработчики сами написали такой код, в котором они добавляют параметр сессии в ссылках, при подгрузке чего-либо, да и просто так. Вторая — это неправильная настройка. Напомню, что непосредственно в PHP для настройки сессий служат два параметра, это session.use_cookies
и session.use_trans_sid:
• session.use_cookies — если установлена эта опция, то сессия будет сохраняться в пряниках (простите, печеньках), такую настройку имеют большинство сайтов, в куках будут данные о сессии, обычно имя PHPSESSION, sessid или подобное;
• session.use_trans_sid — если у этого параметра стоит единичка, то PHP будет подсовывать переменную сессии куда угодно: в ссылки на сайте, в формы. Такая фича устарела и не должна использоваться.
Самое интересное, что ссылки с сессиями часто попадают в поисковики. Например, не так давно я обнаружил крупнейшую утечку сессий в Facebook, поэтому я тебе, %username%, рекомендую отдельно гуглить куки, отвечающие за авторизацию. В Facebook есть мобильная версия, где я заметил новую куку — m_sess, которая таки отвечала за авторизацию. Введя в гугле site:m.facebook.com inurl:m_sess, я увидел в выдаче нескончаемое количество контента, приватные фотографии, текст переписки рандомных юзеров. И с каждым днем сумма проиндексированных страниц росла. Я написал сообщение в поддержку. В ответ мне сказали указать подробности; разложив все по полочкам, я ждал ответа еще три месяца, после чего мне ответили… что я не первый нашел этот баг (O_o), после чего страницы из выдачи исчезли.
Исходя из своего опыта, могу сказать, что некоторые интернет-магазины страдают такой же болезнью. Это тот случай, когда к тебе на почту приходит ссылка, мол, чувак, вот новости нашего магазина, вот новый товар — перейди по ссылке, и ты сразу будешь авторизован. В URL передается тот самый магический параметр, благодаря которому тебе не нужно каждый раз вводить логин и пароль, но такое удобство также чревато утечками аккаунтов. К слову, передача сессии в URL часто приводит к так называемой «фиксации сессии». Это когда злоумышленник берет свою сессию и сохраняет ее в браузере жертвы (с помощью такой же ссылки или используя другую атаку типа XSS или CRLF). После этих действий злоумышленнику остается только ждать. Когда пользователь авторизуется на сайте, злоумышленник, зайдя на сайт, также будет авторизован, потому что сервер принимает его за жертву. Данная атака никак не связана с утечками, так что подробности ты загуглишь сам).
Исправляем: по фэншую — лучше не передавать сессионные идентификаторы в URL, если уж совсем не терпится — закрываем их в robots.txt.
А теперь отвлечемся от темы сессий (студенты плохо реагируют на слово «сессия»), ведь в адресе могут передаваться и другие данные. Например, кто покупал и получал билет на недавнее мероприятие PHDays IV, заметили, что на email приходит билет, ссылка ведет на адрес http://runet-id.com/ticket/*. В поисковике билетов немного, но есть шанс, что перед каким-то платным мероприятием можно будет зайти на него на халяву.
Еще примеры. Интересную утечку с железнодорожными билетами:
site:booking.uz.gov.ua inurl:result
Правда, эти билеты для украинцев, но я думаю, оттуда также найдутся читатели. А путешественников можно поглядеть с помощью дорка site:checkmytrip.com inurl:N=, я сам
пользовался услугами этого сервиса, а потом нашел так свою фамилию…
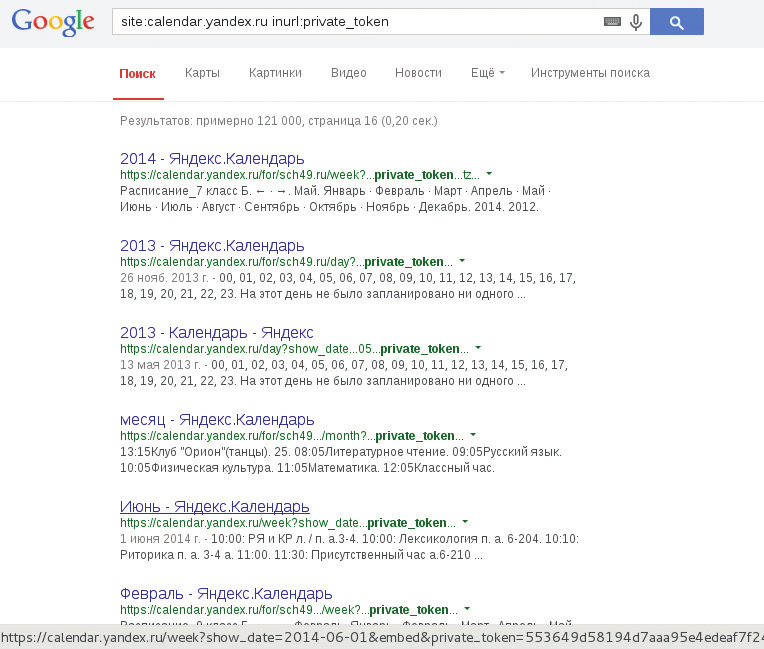
Подобная проблема часто попадается в тикетах поддержки различных сервисов, где войти можно по уникальному идентификатору. Вспоминая наиболее интересные — это поддержка WebMoney и Dr.Web. Там я видел и паспортные данные, и даже логины с паролями на доступ в какой-то партнерский интерфейс. Стоит заметить, что в календаре от Яндекса вовсе отсутствовал robots.txt, а поисковый бот по умолчанию будет индексировать все, что попадается под руку (или что там
у него). В интерфейсе календаря есть экспорт, в URL которого содержится параметр private_token, именно он и проиндексировался, тем самым предоставив доступ к чужим календарям. Ну мало ли, кто там что запланирует в календаре. Отправив этот баг в программу Bug Bounty Яндекса, я получил 10 тысяч деревянных, что вполне неплохо. Поэтому, если участвуешь в охоте на ошибки, проверяй, присутствует ли robots.txt вообще; если нет — глянь, что может проиндексироваться, и будет тебе счастье.
Ах да, чуть не забыл, я же хотел научить тебя, как искать приватные документы в социальной сети vk.com. Итак, начнем. Загрузи и отправь какой-нибудь test.txt в личку другу. Вот теперь открой его. Ссылка будет вида
https://vk.com/doc123456_123123?hash=1f40f66fbe31327d55&dl=009071b58308303170
и документ скачается. Хеш мы такой не подберем, а в гугле индексируются только публичные документы. А теперь посмотри исходник этой странички (<ctrl + s>). На самом деле открывается iframe на URL вида
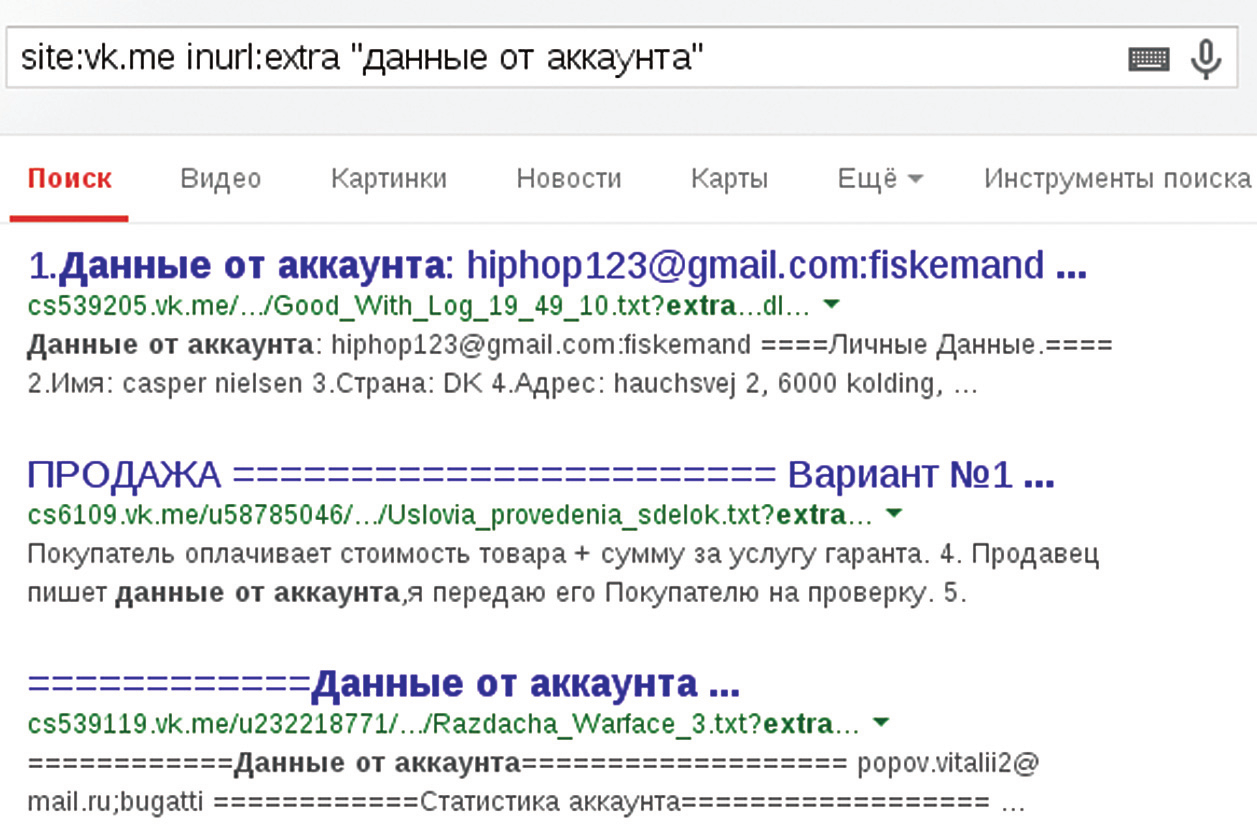
https://ps.vk.me/c539320/u123456/docs/61f4f043b33f/test.txt?extra=HJhTTb-vwqE3dWNgm2zsxjOB3jyz3zRBtV4aJ7hreGtSLP8ke7B6GvnTkdXpWGnWx6kDZ_5ZIIr_ZICERCC lNONO8X7lj5NE&dl=1
А теперь выделим ключевые моменты для нашего дорка: site:vk.me и inurl:extra — поиск по сайту vk.me и его поддоменам с обязательным словом extra в адресе. Тадам! Вот очередная утечка, благодаря которой можно посмотреть пересылаемые файлы. То, что это приватные документы, можно убедиться, сравнив их с найденными в поиске по документам. Еще один интересный момент, что после u идет идентификатор пользователя vk.com, то есть сразу можно узнать хозяина этого файла. Скорее всего, ссылка имеет временный характер, поэтому, открыв ее, вероятно, получишь ошибку 404, так что следует смотреть сохраненную копию — кеш (спасибо гуглу за это). Ну, думаю, разберешься. Утечка произошла потому, что на pp.vk.me отсутствует-таки файл robots.txt. Хотя, может, он и присутствует, но доступ к нему запрещен XD.
Исправляем: Запрещаем индексировать. Проверяем, аутентифицирован ли хозяин этого файла/сообщения/тикета.
Что и требовалось доказать — утечки везде и всюду. Не нужно быть крутым и бородатым хакером, чтобы использовать такого рода ошибки разработчиков и администраторов. Я лично взял себе в привычку: авторизовался на сервере — загуглил куки, открыл файл с подозрительным идентификатором — и его загуглил. Это проще, чем кажется.
Облачные приложения по своей природе используют микросервисы, контейнеризацию, динамическую оркестровку и в значительной степени полагаются…
Чтобы взломать сеть Wi-Fi с помощью Kali Linux, вам нужна беспроводная карта, поддерживающая режим мониторинга…
Работа с консолью считается более эффективной, чем работа с графическим интерфейсом по нескольким причинам.Во-первых, ввод…
Конечно, вы также можете приобрести подписку на соответствующую услугу, но наличие SSH-доступа к компьютеру с…
С тех пор как ChatGPT вышел на арену, возросла потребность в поддержке чата на базе…
Если вы когда-нибудь окажетесь в ситуации, когда вам нужно взглянуть на спектр беспроводной связи, будь…
{kind=link}
{kind=link}