Охотники на онлайновых мошенников вряд ли станут героями боевика. Ни тебе сложных многоходовок, ни погонь и перестрелок. Но кого это волнует, когда на кону сотни миллиардов долларов? Гигантские деньги защищают от преступников при помощи математических моделей, которые выявляют любое отклонение от нормы.

В 2011 году компания PricewaterhouseCoopers провела крупное исследование онлайнового мошенничества. Собранные данные свидетельствуют, что в течение двенадцати месяцев, предшествующих исследованию, жертвами мошенников стали 37% российских компаний, а 7% компаний признались, что теряют таким образом более 100 миллионов долларов в год. С тех пор вряд ли что-то изменилось к лучшему.
В других странах дела идут не веселее. По оценкам экспертов, каждый год в карманы онлайновых мошенников утекают десятки, а то и сотни миллиардов долларов. Точные масштабы бедствия не знает никто, потому что компании страшно не любят рассказывать о том, сколько денег они теряют из-за мошенников. Их можно понять. Лишние подробности только распугают клиентов.
Откуда берутся такие чудовищные суммы? Все просто. Большие российские банки, такие как «Сбербанк» или «Альфа-банк», обрабатывают более миллиона транзакций в сутки. Visa обрабатывала 150 миллионов транзакций в сутки еще четыре года назад. Вообразим, что они теряют по десять долларов на одной транзакции из тысячи. Это значит, что убытки вырастают на миллион долларов каждые сто миллионов транзакций.
Проверить все эти сделки вручную заведомо невозможно. Тут нужна автоматика. Платежные системы и банки много лет используют экспертные системы, которые, следуя подобранному заранее набору правил, выявляют наиболее подозрительные транзакции. Правила принято держать в секрете, но догадаться о содержании некоторых из них нетрудно. Например, туристы знают, что внезапная попытка снять со счета серьезную сумму или сделать крупную покупку в другой стране нередко приводит к блокировке карты, тот же результат дает и приобретение иностранной SIM-карты. Это результаты срабатывания именно таких правил.
Ключевое слово тут — «внезапная». Самый верный признак мошенничества — это аномальное поведение. Именно его выявляют наборы правил. Впрочем, чтобы искать отклонения от нормы, существует масса других путей, и борцы с онлайновым мошенничеством знают их все. В последнее время в моду вошли всевозможные статистические методы, машинное обучение и нейронные сети. В некоторых случаях алгоритмы учатся отличать мошенников по образцам (так называемое обучение с учителем).
Тут действует тот же принцип, что у почтового антиспама, который начинает работать лучше, если показать ему, как выглядит нежелательное письмо. В других случаях ставку делают на поиск странностей или аномалий. Этот подход ценен тем, что его не обманет даже совершенно новый метод мошенничества. Кроме того, он застрахован от ошибок, возникающих в результате обучения на неточных данных.
Новые методы дают более точный результат, чем традиционные наборы правил. Несколько лет назад платежная система Visa усовершенствовала свою систему выявления мошеннических транзакций, которая в прошлом проверяла около четырех десятков особенностей каждой сделки при помощи набора правил. Теперь она в реальном времени анализирует порядка пятисот особенностей, начиная со статистики по конкретному пользователю (например, среднее количество транзакций, которые он совершает в течение суток) и заканчивая номером банкомата. Вскоре Visa отчиталась о двух миллиардах долларов, которые удалось сэкономить благодаря новой системе.
ОПАСНЫЕ СВЯЗИ В МАРКОВСКИХ СЕТЯХ
Значительная доля преступлений такого рода происходит на онлайновых аукционах. Оно и понятно: обмануть простого пользователя куда проще, чем крупный банк или платежную систему. Отзывы покупателей и всевозможные репутационные системы проблему не решают. Наоборот, иногда они даже помогают мошеннику. Накрутить репутацию в онлайновом аукционе куда проще, чем втереться в доверие к живому человеку, а результат один.
Несколько лет назад специалисты компании Symantec и исследователи из университета Карнеги — Меллона обнаружили, что преступники, промышляющие на крупнейшем онлайновом аукционе eBay, выработали стратегию, которая позволяет им набирать хорошие оценки, обманывать покупателей и не бояться неизбежного бана.
Мошенники с самого начала исходят из того, что им придется часто менять учетные записи, с которых совершаются сделки. Чтобы у потенциальных жертв не возникало сомнений, перед использованием свежий аккаунт должен получить хорошую репутацию. Секрет успеха в том, чтобы поставить генерацию мошеннических аккаунтов с хорошей репутацией на поток.
Для этого существуют сети аккаунтов-пособников. Когда возникнет необходимость, они быстро создадут репутацию кому угодно. При этом «пособники» ведут себя максимально естественно, регулярно взаимодействуют с честными продавцами и никогда не нарушают закон. Они могут действовать годами, не привлекая внимания администрации сервиса.
Исследователи из университета Карнеги — Меллона предположили, что анализ связей между пользователями онлайнового аукциона позволит автоматически выявлять аккаунты-мошенники и аккаунты-пособники. Действительно, пособники гораздо чаще взаимодействуют с мошенниками, чем обычный пользователь. Мошенники же, наоборот, никогда не сталкиваются с другими мошенниками — только с пособниками и честными пользователями.
Исследователи представили аукцион в виде марковской сети — ненаправленного графа, вершины которого могут находиться в одном из нескольких состояний. В нашем случае вершинам соответствуют учетные записи. Они могут быть мошенниками, пособниками или честными пользователями — это, если использовать термины марковской сети, их состояния. Если аккаунты провернули хотя бы одну сделку, соответствующие им вершины свяжет дуга.
Состояние каждой вершины в марковской сети зависит от ее текущего состояния и состояний ее соседей. Как именно она зависит, определяет так называемая матрица распространения. В ней прописаны наиболее вероятные следующие состояния для всех сочетаний текущего состояния и состояния соседней вершины. Правдоподобные вероятности исследователи подобрали вручную.
Чтобы определить наиболее вероятный статус каждой вершины, использовался алгоритм распространения доверия (belief propagation). Вначале каждая вершина подсчитывает свое состояние по матрице распространения. Затем вершины сообщают друг другу об изменившемся состоянии. Получив новые данные о соседях, они уточняют свое состояние. Это запускает следующий этап вычислений, за которым идет новая цепочка сообщений. Так продолжается до тех пор, пока система не достигнет равновесия.
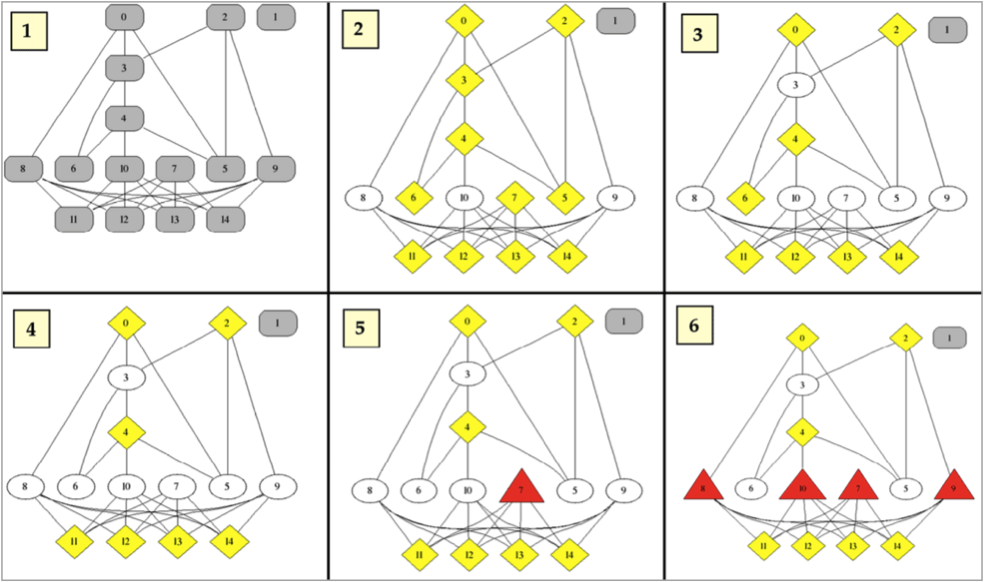
Чтобы проверить эффективность этого метода, исследователи напустили на eBay самодельного робота, который собирал информацию о пользователях и сделках между ними. На основании полученного набора данных они построили граф, состоящий из 66 130 вершин и 795 320 дуг. Десять вершин в этом графе принадлежали уже пойманным мошенникам, о которых сообщали в но- востях. Алгоритм верно определил каждого из них и пометил вероятных сообщников. Есть и другой признак того, что идея верна: репутация учетных записей, которые алгоритм заподозрил в мошенничестве, оказалась в несколько раз хуже, чем у остальных.
Интересно, что для того, чтобы все сработало, алгоритму не обязательно знать заранее, кто пособник, а кто мошенник. Не нужна даже репутация пользователей. Анализу подлежат лишь связи между ними. Все определяет топология графа.
НЕПРАВИЛЬНАЯ ДРУЖБА РУССКИХ РОБОТОВ
В 1881 году американский математик Саймон Ньюком заметил нечто очень странное: по какой-то причине первые страницы в книгах с логарифмическими таблицами всегда истрепаны сильнее, чем последние. И дело не в том, что их никто не дочитывает до конца. Логарифмические таблицы — не обычная книга, которую положено читать по порядку. Это инструмент, значительно ускоряющий умножение и деление больших чисел.
В логарифмические таблицы сводят заранее подсчитанные логарифмы множества чисел. Чтобы перемножить два числа, достаточно отыскать в таблице соответствующие им логарифмы, сложить их, а затем определить по той же таблице, какому результату соответствует сумма. Это гораздо проще и быстрее, чем умножение столбиком, которому учат в школе.
В начале логарифмической таблицы перечислены логарифмы чисел с единицей в старшем разряде, затем идут логарифмы чисел, начинающихся с двойки, и так далее до девяти. Если в начале книга истрепана сильнее, чем в конце, значит, множители, которые начинаются с единицы, нужны людям чаще, чем числа, начинающиеся с цифры два, не говоря уж о девяти.
Ньюком предположил, что чем меньше значение старшего разряда числа, тем чаще оно встре- чается. Согласно формуле, которую вывел ученый, вероятность столкнуться с числом с единицей в начале составляет около 30%. Вероятность снижается с каждой цифрой, пока не достигает 4,6% — это значение соответствует девятке.
Здравый смысл протестует против этой идеи, но с фактами не поспоришь. В 1938 году физик Фрэнк
Бенфорд, независимо наткнувшийся на ту же закономерность, протестировал справедливость своих
выводов на десятках тысяч измерений. Он подсчитал вероятность, с которой разные цифры встречаются в старшем разряде десятков физических констант.
Результаты совпали с предсказаниями формулы. Площади бассейнов рек? Молекулярный вес со- тен химических веществ? Численность населения случайно отобранных населенных пунктов? Курсы акций на бирже? Бенфорд проверял один набор данных за другим, но не мог найти ошибки. Распределение цифр в старшем разряде подчинялось закону, который сегодня носит его имя, — закону Бенфорда.
В начале семидесятых экономист Хэл Вэриан предложил использовать закон Бенфорда для того, чтобы отличать фальсифицированные данные от подлинных. Значения, взятые с потолка, могут выглядеть очень правдоподобно, но они не выдерживают проверки законом Бенфорда. К концу двадцатого века этот метод взяла на вооружение судебная бухгалтерия. Там проверяют, укладываются ли цифры в финансовой отчетности в нужное распределение. Если закон Бенфорда не соблюден, значит, финансовые показатели кто-то подправил.
Закон Бенфорда с легкостью отыскивает следы человеческого вмешательства в естественный порядок. Нужно ли объяснять, насколько это ценное качество для поиска аномалий в данных? Алгоритм, построенный таким образом, прост и эффективен. Правда, он не годится для анализа данных, которые заведомо неестественны. Это ограничение, но у кого их нет?
Красивый пример использования закона Бенфорда для выявления обмана дает недавняя работа Дженнифер Голбек, известной специалистки в области анализа социальных сетей. Она показала, что с его помощью можно выводить на чистую воду ботов — поддельные учетные записи в Facebook или Twitter.
Голбек начала с изучения наборов данных о подмножествах пользователей пяти крупных социальных сетей: Facebook, Twitter, Google+, Pinterest и LiveJournal. В большинстве случаев данные о пользователях извлекались при помощи программного интерфейса соответствующей соцсети. Исключение составляли Google+ и LiveJournal. Информация об их пользователях была позаимствована в Stanford Network Analysis Project.
Для начала исследовательница проверила количество связей между аккаунтами в каждой соцсети. Как и ожидалось, эти значения совпали с показателями, которые предсказаны законом Бенфорда. Исключение составляет Pinterest: при создании аккаунта сервис добавляет пять связей автоматически, и это портит всю статистику.
Затем Голбек занялась анализом отдельных учетных записей. Она отобрала те из них, которые насчитывают по меньшей мере сто социальных связей. Оказалось, что распределение первых значащих цифр количества «друзей» у аккаунтов, к которым ведут эти связи, почти всегда укладывается в закон Бенфорда. Например, в наборе данных Twitter существенное отклонение наблюдалось лишь в 1% случаев.
И что же это за процент? Голбек проверила 170 аккаунтов Twitter, не подчиняющихся закону Бенфорда, и обнаружила, что лишь два из них не вызывают подозрений. Подавляющее большинство остальных оказались русскими ботами. Эти аккаунты очень похожи друг на друга: фотография пользователя явно позаимствована из фотобанка, сами твиты — бессмысленные обрывки книжных цитат, друзья — другие боты. Они маскируются под обычных людей, но закон Бенфорда легко выявляет их искусственность.
В одной небольшой статье невозможно перечислить (и тем более разъяснить) все методы выявления аномалий, полезные при охоте на онлайновых мошенников. Но такой цели и не стоит — это не «Антифрод для чайников» (такая книжка, к слову, существует). Если же ты хочешь погрузиться в тему глубже, то лучшим способом будет чтение академических публикаций. Scholar.google.com поможет их найти, а дальше — сам.
1 comments On Как работают антифрод системы.
Pingback: Удаленный взлом банков через ошибки конфигурации СУБД. - Cryptoworld ()