Мы постоянно встречаемся в своей жизни с новыми людьми, и стоит констатировать, что помимо хороших друзей нам попадаются мутные товарищи, а иногда и отъявленные мошенники. Любовь наших сограждан оставить свой след в интернет и старания наших ИТ-компаний по автоматизации всего и вся позволяют нам довольно оперативно собирать интересующую информацию о конкретных персонах по открытым источникам. Чтобы это делать быстро и качественно, нам нужно владеть простой методологией разведывательной работы и знать, где и как пробить человека через интернет.

Как работает разведка?
Доступной моделью работы любой разведывательной службы является так называемый разведывательный цикл. Ниже представлена иллюстрация цикла, взятая с сайта ФБР.
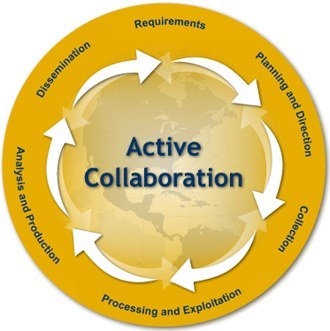
Мы можем творчески перевести и сгруппировать немного по-своему и получить следующие этапы:
- Постановка задачи/формулировка проблемы;
- Планирование;
- Сбор данных;
- Обработка данных;
- Анализ информации;
- Подготовка отчета и презентация результатов.
Возьмем эту модель на вооружение и адаптируем для наших благих целей проверки нечистоплотных товарищей.
[ad name=»Responbl»]
Шаг 1. Постановка задачи
Обычно задача про проверке какого-либо человека ставится примерно так: “Надо собрать всю информацию об этом человеке!” По факту чаще всего нам интересно знать его биографию, психологический портрет, круг знакомств.
Шаг 2. Планирование
Не имея плана поиска и анализа данных, мы будем долго и грустно смотреть в экран и отправлять в поисковики различные запросы, содержащие крупицы известных нам данных о нашей цели. Если нам повезет, то мы сможем что-нибудь выловить, если нет – то зря потратим время в попытках перетрясти весь интернет.
Как спланировать наши действия?
1) Нам нужно собрать все, что известно на текущий момент: имя, фото, тел, сфера деятельности, друзья и т.д. и т.п. Как правило, самой ценной информацией является ник, используемый человеком в интернет (чаще всего его можно получить, зная личный адрес электронной почты).
2) Нам нужно сформулировать рабочие гипотезы для поиска данных на основе имеющейся информации. Например:
- Человек работает в компании, занимающей продажей комбикормов, название которой заканчивается на «ва»: мы видели фотографию с выставки и смогли рассмотреть часть названия компании.
- Возраст от 30 до 40: оценили по голосу или описанию.
- Дружит с таким-то человеком.
- и т.п.
Примечание. Талантливый разведчик должен уметь переключаться между двумя состояниями: безудержный креатив и жуткое занудство. В первом случае накидываем гипотезы для проверки, а во втором тщательно их проверяем: находим информацию и отбраковываем гипотезы в случае выявления несоответствий.
[ad name=»Responbl»]
3) Имея рабочие гипотезы, продумываем какие источники данных нам могут быть полезны в этом легком деле по выводу на чистую воду.
На поверхности лежат следующие источники интересной информации:
- Социальные сети VKontakte, Facebook, Twitter, Instagram и т.п. (масса интересной информации: фото, гео, друзья, интересы, контакты, психологический портрет и т.п.).
- Сайты судов (если знаем фамилию и место регистрации, то сможем узнать не судится ли человек по базе на сайте конкретного суда).
- База недействительных паспортов (http://services.fms.gov.ru/info-service.htm?sid=2000).
- База судебных приставов: не должен ли наш товарищ чего? (http://fssprus.ru/iss/ip/).
- База дипломов (http://frdocheck.obrnadzor.gov.ru).
- Google с Яндексом.
Замечание. Зная ник, можно быстро посмотреть в каких социальных сетях существуют соответствующие страницы. Для этого существуют специальные сервисы для проверки доступности страниц, например, namechk.com Забытые пользователем аккаунты иногда бывают намного интересней текущих.
Мощным источником информации может стать поисковик, но чтобы извлечь максимальную пользу начинающему разведчику необходимо освоить так называемые операторы продвинутого поиска, среди которых одними из самых полезных являются: “”, -, cache, site:, filetype:, но это тема для отдельной статьи.
[ad name=»Responbl»]
Шаг 3. Сбор данных
В рассматриваемом случае сбор данных будет заключаться в формировании запросов к рассмотренным источникам и сохранении результатов для текущего и последующего сопоставления и анализа. Бывает очень полезно в процессе подобного упражнения открыть текстовый редактор и последовательно сохранять в него обнаруженные данные (скриншоты, текст, фото и т.п.).
Шаг 4. Обработка данных
Иногда чтобы получить ценную информацию нужно покопаться в сырых данных. Примерами обработки могут быть:
- Извлечение метаданных из документов (авторство, GPS-координаты).
- Приведение выгрузки данных из социальных сетей к виду, с которым можно работать, например, в том же Excel.
- и т.п.
Шаг 5. Анализ информации
1. Тестируем гипотезы. Собирая по крупицам информацию, мы сразу же проводим ее анализ и тут снова могут быть полезны гипотезы и их тестирование на жизнеспособность. Сопоставляя с ними выявленные факты, косвенные признаки, логические заключения из фактов, можно определить наиболее вероятную гипотезу.
| Факты/Суждения | Гипотеза 1 | Гипотеза 2 | Гипотеза 3 | Гипотеза 4 |
|---|---|---|---|---|
| Факт 1 | + | + | + | + |
| Факт 2 | — | + | + | + |
| Суждение 1 | — | — | + | + |
| Факт 3 | — | — | — | + |
2. Элементарные операции с данными: сортировка, сопоставление элементов и т.п. могут открыть массу интересного. Например, можно выгрузить списки друзей друзей интересующего человека и, сопоставив их, определить сообщества, структуры, к которым может иметь и интересующее нас лицо. В этом нелегком деле нам может помочь Excel с его возможностью условного форматирования в случае совпадения элементов.
3. Анализ фото- и видео-изображений. От опытного глаза начинающего интернет-разведчика не уйдут не только случайно попавшие в кадр: вид из окна, часть названия географического пункта или пикантное отражение в зеркале на заднем плане, но и различные невербальные сигналы, которые позволят судить о человеке:
- складки на лице, открывающие превалирующую эмоцию человека;
- любимые жесты;
- характер взаимоотношений с другими людьми и т.п.
[ad name=»Responbl»]
4. Анализ содержимого текстов интересующего человека или его собеседников. Обратите внимание на то, как человек описывает свое отношение к другим, что его друзья пишут о нем самом. Тут, конечно, стоит не только уметь внимательно читать, но и знать различного рода тонкости, например, то, что можно в соцсети VKontakte искать упоминания о человеке с помощью следующего URL-запроса: vk.com/feed?obj=ID&q=§ion=mentions, где ID – это идентификатор пользователя, который можно узнать, наведя курсор, например, на кнопку «Отправить сообщение»: цифры в ссылке и будут его ID.
5. Анализ лайков. Некоторые ставят лайки всему, что видят, от кого-то лайка никогда не дождешься, но, в основном, люди довольно избирательны в этом деле и вот тут очень интересно посмотреть статистику того, кто или что собирает максимум лайков от нашего человека. Хорошо, что появляются сервисы, позволяющие этот интересный процесс анализа автоматизировать, например, такие как searchlikes.ru
Тема анализа информации очень обширная и интересная, и мы к ней еще не раз вернемся в будущих статьях.
Шаг 6. Подготовка отчета и презентация результатов
Настоящие разведчики много пишут, так как работают на государство. Нам же, так как мы занимаемся подобными вещами исключительно в личных целях и в рамках закона, отчеты строчить не нужно. Тем не менее упражняться в письменном изложении процесса анализа и его результатов очень полезно, так как мы можем тем самым развивать логическое мышление и приобретать навыки анализа текстовой и числовой информации.
[ad name=»Responbl»]
Вместо заключения
Итак, мы рассмотрели процесс сбора и анализа информации о конкретном человеке в интернет, воспользовавшись моделью разведывательного цикла и знанием о том, где в интернет есть интересные данные.


