Работа в Data Science, как вы, возможно, слышали, престижно и требует денег. В этой статье я познакомлю вас с основами языка R, используемого в «науке о данных». Мы напишем так называемый наивный байесовский классификатор, который будет обнаруживать спам в почте т.е. собственный детектор спама. Разработав программу, вы увидите, насколько скучная и сухая математика может быть достаточно наглядной и полезной. Вы сможете написать и понять детектор спама, даже если вы никогда не встречали ничего подобного.

Но сначала я должен вас предупредить, что для полного понимания вам полезно понять основы статистических методов. Конечно, я постараюсь подать материал так, чтобы проницательный читатель, незнакомый со статистикой, тоже имел возможность вникнуть в тему, но теоретические основы статистики останутся за рамками данной статьи.
Кроме того, я исхожу из того, что, с одной стороны, вы хорошо разбираетесь в теории и практике программирования, знакомы с алгоритмами и структурами данных, но, с другой стороны, вы еще не познакомились с языком R. Я познакомлю вас с ним в томе, который достаточно, чтобы с комфортом писать, запускать и понимать первую программу.
Знакомимся с языком R и готовим рабочее место
Сначала посмотрим, как установить R и как запускать и отлаживать в нем программы, как находить и устанавливать необходимые библиотеки (в мире R они называются пакетами), насколько удобно искать документацию по различным функциям.
DE для R качай с официального сайта. Доступны версии для трех ОС: Linux, Mac и Windows. Установка должна пройти легко, но если что-то пойдет не так, попробуй первым делом заглянуть в FAQ.
Теперь запускаем IDE. Выглядеть она будет примерно так.
Подсветка синтаксиса здесь, конечно, так себе — вернее, ее вообще нет, — так что код можно спокойно писать в каком-нибудь другом редакторе, а IDE использовать только для запуска уже готового кода. Лично я пишу на R в онлайновом редакторе на rextester.com.
Чтобы установить нужный пакет (библиотеку), используй функцию install.packages. В install.packages есть полезная опция — suggests. По умолчанию ей присвоено значение FALSE. Но если перевести ее в TRUE, install.packages подгрузит и установит все вторичные пакеты, на которые полагается тот пакет, который ты ставишь. Рекомендую всегда устанавливать эту опцию в TRUE, особенно когда начинаешь с чистого листа и только-только (пере)установил R.
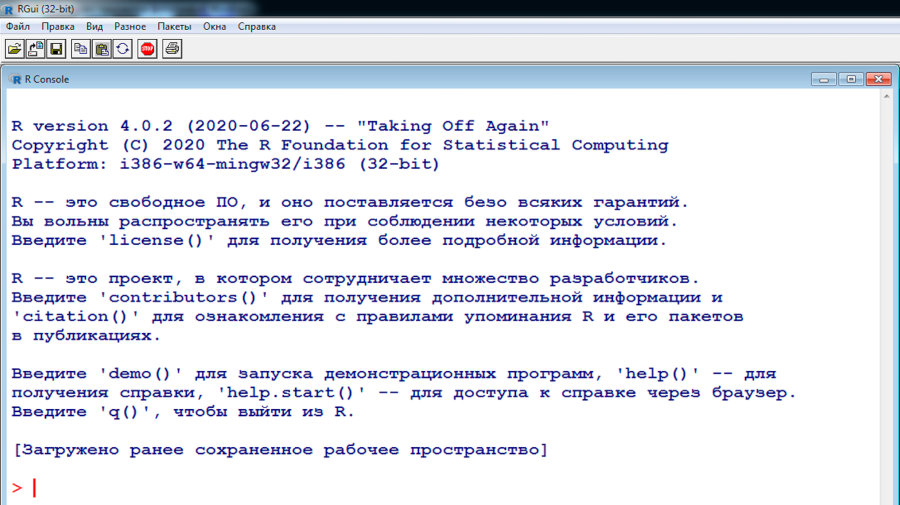
Вот тебе для удобства скрипт, который проверяет, установлены ли нужные тебе пакеты. Если какие-то из них не установлены, скрипт подгружает и устанавливает их. Перепечатай и сохрани скрипт в файл update_packages.r. Сейчас он подгружает только два пакета, которые нам понадобятся, когда будем писать детектор спама. По мере необходимости можешь добавлять и другие пакеты.
Чтобы выполнить скрипт (и этот, и все остальные, которые ты напишешь), сначала переключи рабочую директорию на ту, куда его сохранил. Для этого введи в консоль R функцию setwd (например, setwd("e:/work/r")). Потом выполни команду source вот таким образом: source("install_packages.r"). Она запустит твой скрипт, и ты увидишь, как подгружаются пакеты, которые у тебя еще не установлены.
Чтобы подключить пакет к программе, используй функцию library или require. Например, library('tm').
Чтобы найти документацию к функции, просто введи в консоли ?xxx, где xxx — имя интересующей тебя функции. IDE откроет в браузере страницу с информацией по этой функции.
Готовим данные
Сначала мы подготовим наборы данных для обучения и тестирования будущего детектора спама. Я предлагаю взять их из архива Apache SpamAssassin. По ссылке вы найдете подборку писем, сгруппированных по трем категориям: spam(собственно спам), easy_ham (легитимные письма, которые легко отличить от спама), hard_ham (легитимные письма, которые сложно отличить от спама).
Создай в своей рабочей директории папку data. Перейди в нее и создай в ней еще пять папок:
easy_nonspam_learn,easy_nonspam_verify;spam_learn,spam_verify;hard_nonspam_verify.
По папкам spam_learn и spam_verify распредели по-братски письма из spam. По папкам easy_nonspam_learn, easy_nonspam_verify – из папки ‘easy_ham’. В папку hard_nonspam_verify скопируй все письма из hard_ham.
Как ты уже наверно догадался, письмами из папок _learn мы будем тренировать свой детектор спама отличать спам от не-спама, а письмами из папок _verify – будем проверять, как хорошо он научился это делать.
Но почему тогда мы не создали папку hard_nonspam_learn? Для остроты эксперимента! Мы будем тренировать детектор только теми письмами, которые легко отличить от спама. А в конце посмотрим, сможет ли он узнавать в письмах из категории hard_nonspam правомерную почту без предварительной тренировки.
Как конструируют признаки
Теперь, когда у нас есть исходные данные для обучения и проверки, нам нужно «сконструировать признаки», которые наш детектор спама будет искать в необработанных текстовых файлах с письмами. Умение конструировать признаки — один из основных навыков в Data Science. Ключом к успеху здесь является профессиональная интуиция, которая приходит с годами практики. Компьютеры пока не могут выполнять эту работу автоматически, вместо нас. И, скорее всего, никогда не смогут.
С другой стороны, компьютеры могут облегчить нашу работу по конструированию признаков. В частности, в R есть пакет tm (от слов Text Mining) для анализа текста. С его помощью мы посчитаем, какие слова чаще всего встречаются в спаме, и в не спаме, и будем использовать их частоту в качестве признаков.
Современные детекторы спама делают гораздо больше, чем просто подсчет количества слов, но, как вы скоро увидите, даже наш базовый детектор спама неплохо отделяет спам от не-спама.
В основу нашего детектора положим наивный байесовский классификатор. Логика его работы такая: если видим слово, которое в спаме встречается чаще, чем в не-спаме, то кладем его в копилку спам-признаков. По такому же принципу формируем копилку признаков для не-спама.
Как эти признаки могут помочь нам отличить спам от не- спама? В анализируемом письме ищем оба типа знаков. Если в итоге выясняется, что признаков спама больше, чем признаков отсутствия спама, то письмо является спамом, в противном случае оно правомерное.
При расчете вероятности того, является ли наша электронная почта спамом, мы не учитываем, что некоторые слова могут быть взаимозависимыми. Мы оцениваем каждое слово отдельно от всех остальных слов. На статистическом сленге такой подход называется «статистическая независимость». Когда статистики-математики исходят из такого предположения и не совсем уверены, верно ли оно здесь, они говорят: «Наша модель наивна». Отсюда и название: наивный байесовский классификатор, а не просто байесовский классификатор.
Пишем функцию чтения писем из файлов
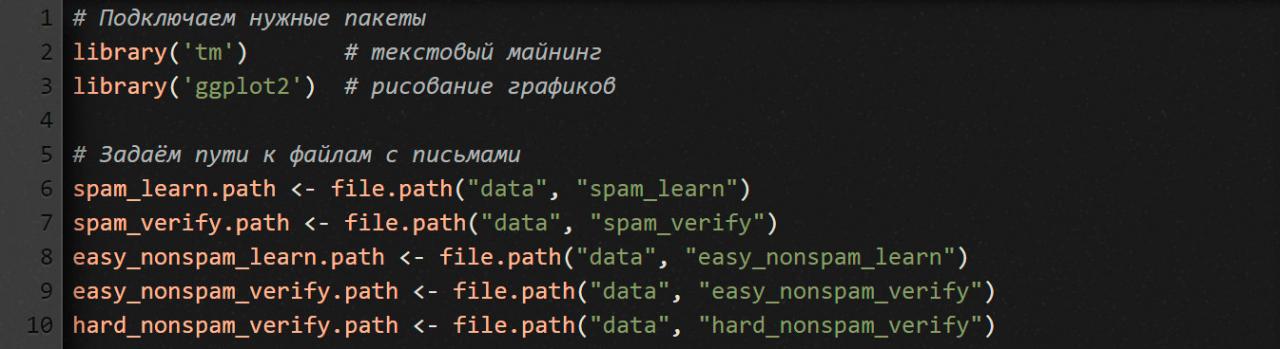
Сначала подгружаем библиотеки, которые нам понадобятся, и прописываем пути к папкам, в которых хранятся файлы с письмами.
Каждый отдельно взятый файл с письмом состоит из двух блоков: заголовок с метаданными и содержание письма. Первый блок отделен от второго пустой строкой (это особенность протокола электронной почты описана в RFC822). Метаданные нам не нужны. Нас интересует только содержимое письма. Поэтому напишем функцию, которая считывает его из файла с письмом.
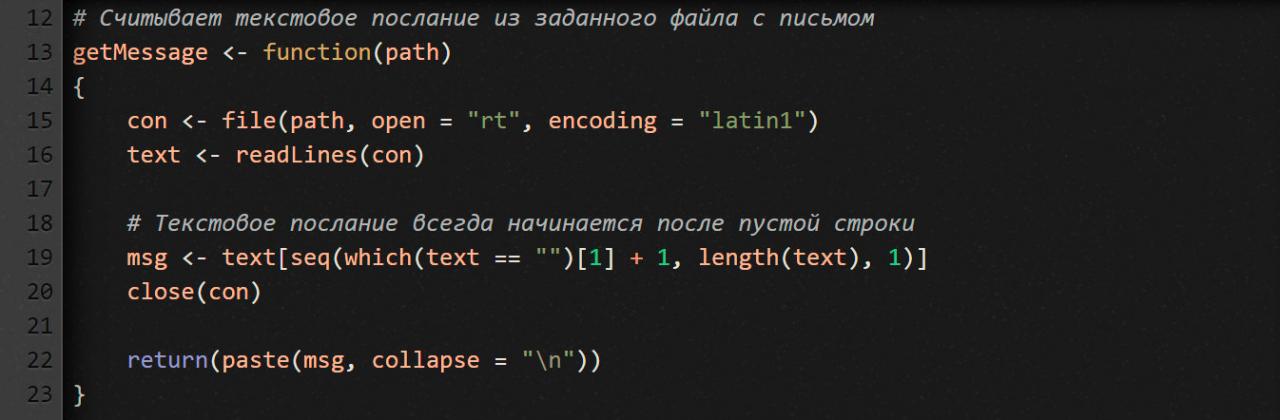
Что мы тут делаем? В языке R файловый ввод/вывод осуществляется точно так же, как и в большинстве других языков программирования. Функция getMessage получает на входе путь к файлу и открывает его в режиме rt (read as text — читать как обычный текст).
Обрати внимание, здесь мы используем кодировку Latin-1. Зачем? Потому что во многих письмах есть символы, которых нет в кодировке ASCII.
Функция readLines считывает текстовый файл построчно. Каждая строка становится отдельным элементом в векторе text.
После того как мы прочитали из файла все строки, ищем первую пустую, а затем извлекаем все строки после нее. Результат помещаем в вектор msg. Как ты, наверно, понял, msg — это и есть содержимое письма, без заголовочных метаданных.
Наконец, сворачиваем весь вектор msg в единый блок текста (см. часть кода с функцией paste). В качестве разделителя строк используем символ \n. Зачем? Так его будет удобнее обрабатывать. И быстрее.
Сейчас создадим вектор, который будет содержать текстовые сообщения из всех спамных писем. Каждый отдельно взятый элемент вектора — это отдельное письмо. Зачем нам такой вектор? Мы будем с его помощью тренировать свой детектор.
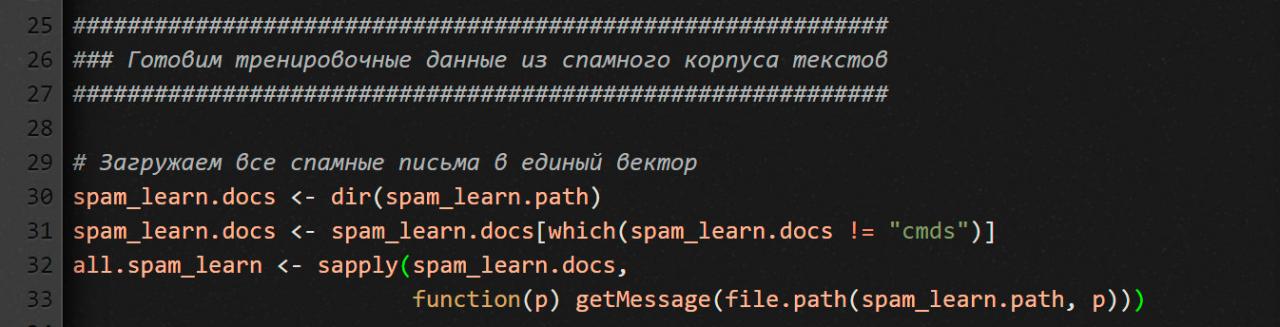
Сначала мы получаем список всех файлов в папке для спама. Но там, кроме писем, есть еще и cmds-файл (служебный файл с длинным списком Unix-команд для перемещения файлов), который нам не нужен. Следовательно, вторая строка предыдущего фрагмента кода удаляет имя этого файла из окончательного списка.
Чтобы создать нужный нам вектор, воспользуемся функцией sapply, которая применит функцию getMessage ко всем именам файлов, которые мы только что получили при помощи dir.
Обрати внимание, здесь мы передаем в sapply безымянную функцию — чтобы объединить имя файла и путь к каталогу, где он лежит. Привыкай, для языка R это весьма распространенная конструкция.
Готовим корпус текстов для спамных писем
Теперь нам надо создать корпус текстов. С его помощью мы сможем манипулировать термами в письмах (в корпусной лингвистике составные части текста, в том числе слова, называют термами). Зачем нам это? Чтобы сконструировать признаки спама для нашего детектора.
Технически это значит, что нам надо создать терм-документную матрицу (TDM), у которой N строк и M столбцов (N – количество уникальных термов, найденных во всех документах; M — количество документов в корпусе текстов). Ячейка [iTerm, jDoc] указывает, сколько раз терм с номером iTerm встречается в письме с номером jDoc.
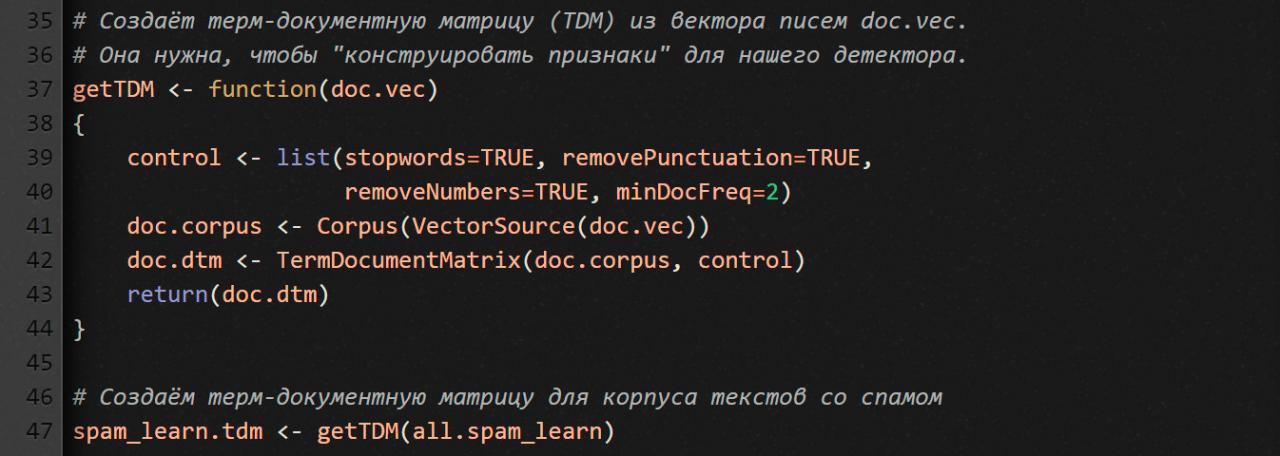
Функция getTDM получает на входе вектор со всеми текстовыми сообщениями из всех спамных писем, а на выходе выдает TDM.
Пакет tm позволяет конструировать корпус текстов несколькими способами, в том числе из вектора писем (смотри функцию VectorSource). Если тебе интересны альтернативные источники, набери в R-консоли ?getSources.
Но прежде чем конструировать корпус, мы должны сказать пакету tm, как надо вычищать и нормализовывать текст. Свои пожелания мы передаем через параметр control, который представляет собой список опций.
Как видите, мы здесь используем четыре опции.
stopwords=TRUE— не принимать во внимание 488 стоп-слов (распространенные слова английского языка). Чтобы посмотреть, какие слова входят в этот список, набери в консолиstopwords().removePunctuation=TRUEиremoveNumbers=TRUE— говорят сами за себя. Мы их используем для уменьшения шума от соответствующих символов. Тем более что многие наши письма напичканы HTML-тегами.minDocFreq=2— строки в нашей TDM нужно создавать только для тех термов, которые встречаются в корпусе текстов больше одного раза.
Готовим почву для конструирования признаков
Напомню, мы хотим натренировать детектор таким образом, чтобы он мог оценивать вероятность того, что анализируемое письмо — это спам. Как мы собираемся это делать? Выискивая в анализируемом письме термы, которые для нас являются признаками спама. И вот что для этого нужно сделать в коде…
Мы будем использовать только что созданный TDM для создания обучающего набора данных из спам-писем. Для этого мы создаем срез данных, который содержит общую частоту всех терминов. Тогда они могут служить признаком того, что проанализированное письмо является спамом.
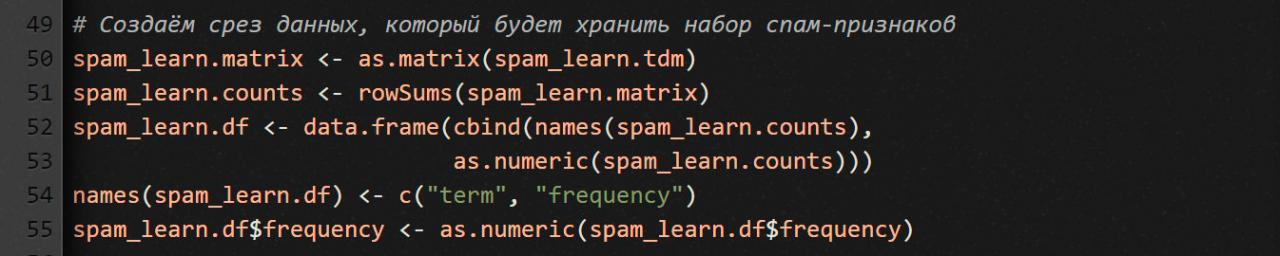
Что мы здесь делаем? Чтобы получить срез данных, мы сначала конвертируем свою TDM в стандартную R-матрицу (функция as.matrix). Затем при помощи rowSums создаем вектор, в котором для каждого терма высчитывается суммарная частота со всех спамных писем.
Дальше объединяем строковый (с термами) и числовой (с частотностью) векторы, используя функцию data.frame.
Наконец, мы немного уточняем наши данные: мы устанавливаем метки для столбцов и преобразуем частоты в числовое представление.
Генерируем тренировочные данные
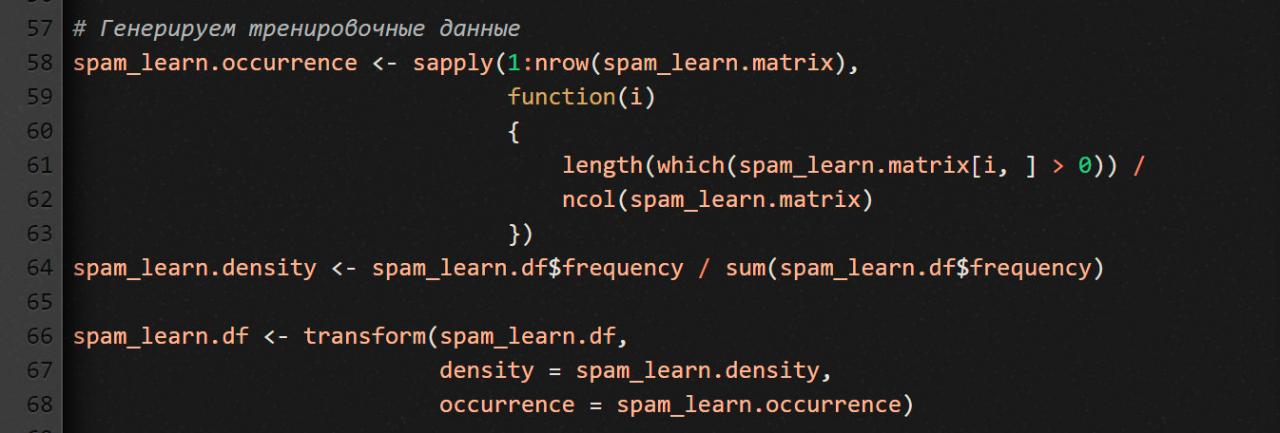
В этом небольшом фрагменте кода мы сначала вычисляем процент документов, в которых он находится (occurrence) для каждого термина. Как мы делаем это? Мы прогоняем каждую строку (т.е. каждый терм) через безымянную функцию (переданную в качестве аргумента в sapply), которая сначала подсчитывает количество ячеек со значением больше нуля, а затем делит полученную сумму на количество столбцов в TDM (т.е. за количество документов в спам-корпусе текстов).
Дальше вычисляем плотность терма (density) по всему корпусу текстов.
Наконец, при помощи функции transform добавляем к своему срезу данных два только что вычисленных вектора: spam_learn.occurrence (процентная часть документов, в которых встречается рассматриваемый терм) и spam_learn.density (плотность терма по всему корпусу текстов).
Всё! Набор тренировочных данных для спамной части нашего детектора готов. Давай проверим их: посмотрим, какие термы из спамного корпуса текстов оказались самыми яркими индикаторами. Для этого отсортируем наш spam_learn.df по столбцу occurrence и посмотрим что получилось. Введи в консоли R:
head(spam_learn.df[with(spam_learn.df, order(-frequency)),])
Результат должен выглядеть как-то так.
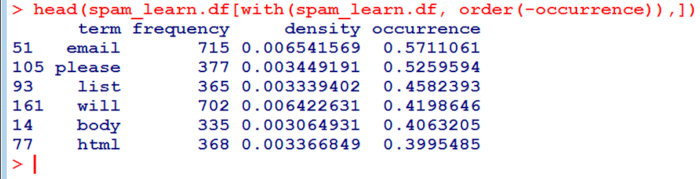
Как видишь, HTML-теги — это наиболее яркие индикаторы спама. На их долю приходится больше 30 % писем из спамных тренировочных данных.
Обрабатываем письма easy_nonspam
С письмами из папки easy_nonspam_learn делаем то же самое, что и со спамом. Код практически такой же.
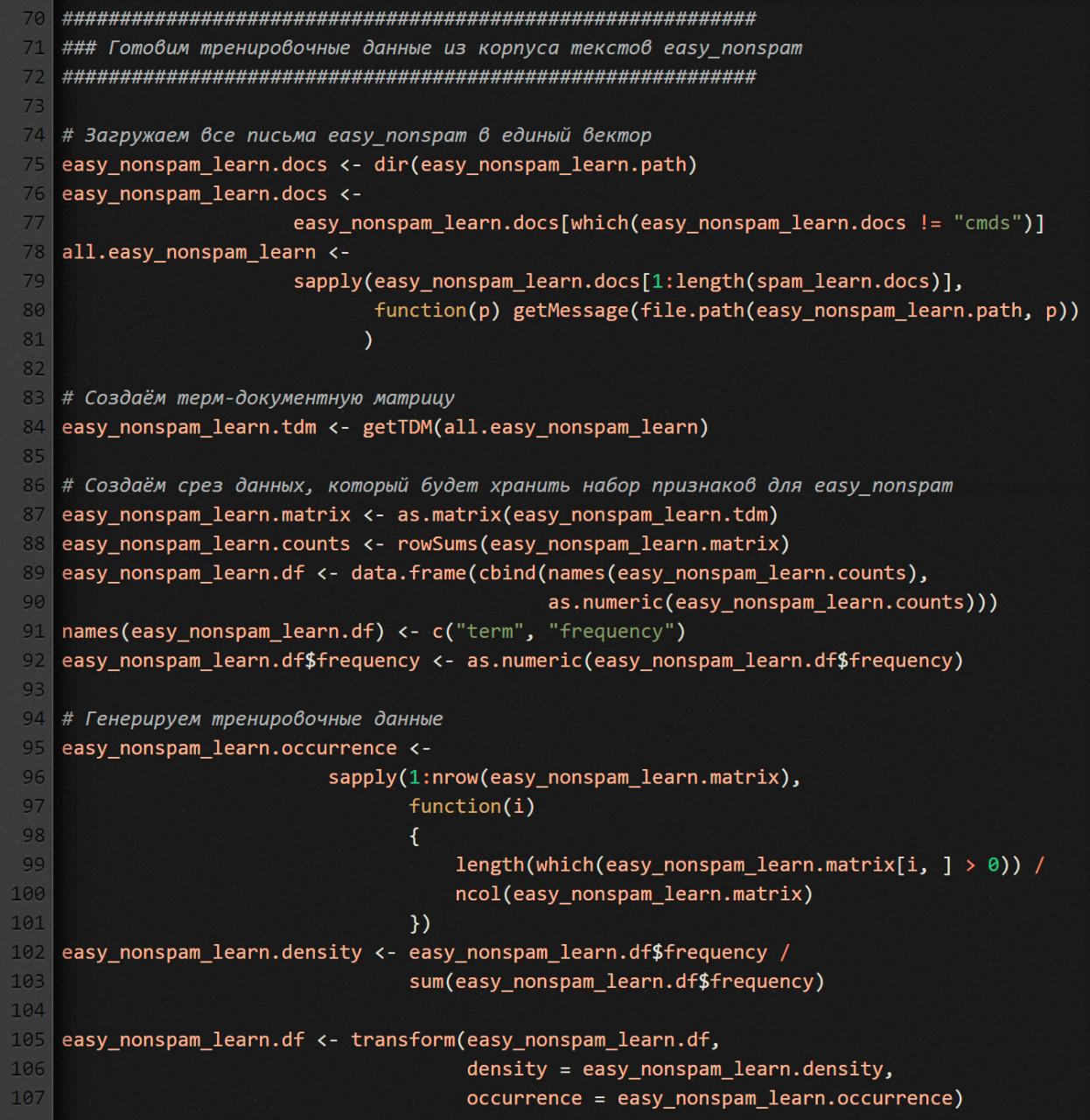
Единственное отличие (смотри 80 строку): мы считываем из easy_nonspam_learn не все письма (их там больше 2000), а столько, сколько прочитали из папки spam_learn (порядка 500). Зачем такая уравниловка? Чтобы детектор работал беспристрастно. А то если его перетренировать на какой-то одной категории писем, то он будет видеть спам там, где его нет, или наоборот.
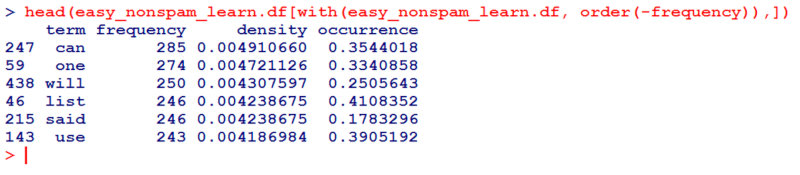
Теперь набор тренировочных данных для не-спамной части нашего детектора тоже готов. Давай посмотрим, что получилось:
head(easy_nonspam_learn.df[with(easy_nonspam_learn.df, order(-frequency)),])
Результат должен выглядеть как-то так.
Пишем классификатор
Следовательно, у нас есть два набора обучающих данных, то есть два сигнальных поля: для спама и для не-спама. Как они помогут нашему детектору отделить пшеницу от плевел? Детектор рассчитает для каждой копилки «наивную байесовскую вероятность» того, что анализируемое письмо относится к ее категории. Вот функция, которая воплощает эту идею.
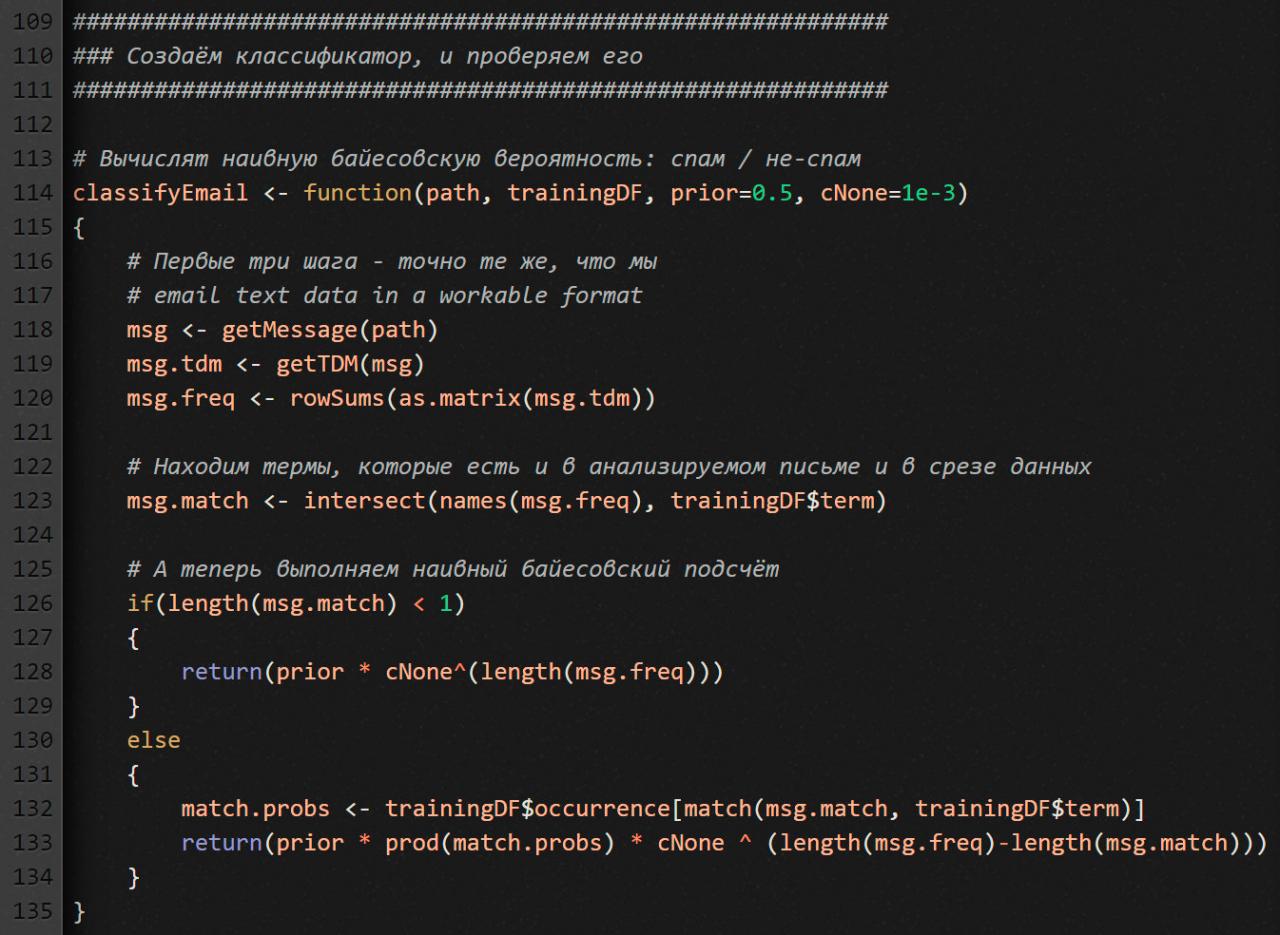
Мы передаем ей четыре параметра:
path— письмо, которое надо проанализировать;trainingDF— срез данных по тому тренировочному набору, с которым мы хотим сравнить анализируемое письмо;prior— наше «наивное предположение» по поводу того, какая часть писем (в процентах) обычно оказывается спамом;cNone— константа вероятности, которую мы присваиваем новым термам — тем, которых нет в тренировочных письмах.
Обратите внимание, как я отношусь к тем термам анализируемого письма, которых не было в обучающих письмах и которые наш детектор поэтому не знает. Вернее, что мне делать с их нулевой частотой. Если оставить их частоту как есть, функция classifyEmail не будет работать правильно. По сути, в нем расчеты основаны на умножении частот. Если хотя бы один из факторов равен нулю — а это будет происходить очень часто — результат неизменно будет нулевым.
Поэтому термам с нулевой частотой я присваиваю небольшую постоянную частоту: 0,1% — то есть частоту, которая явно ниже, намного ниже частот, записанных в наших обучающих данных. Более того, такой способ работы с неизвестными термами — очень распространенный подход в Data Science.
Как работает classifyEmail
Обрати внимание, первые три шага мы здесь делаем точно так же, как при обработке тренировочных данных:
get.msgизвлекает текст из письма;get.tdmпреобразует этот текст в TDM;rowSumsрассчитывает частотность.
Дальше нам надо определить, как термы из анализируемого письма пересекаются с термами из наших тренировочных данных. Для этого задействуем команду intersect. Передаем ей термы, найденные в анализируемом письме, и термы из тренировочных данных.
Завершающий шаг классификации: определить, есть ли в анализируемом письме какие-то термы, которые также есть и в наших тренировочных данных. Если такие есть, используем их, чтобы понять, какова вероятность, что анализируемое письмо относится к категории того среза данных, которые переданы параметром trainingDF.
Как все это выглядит вживую? Допустим, мы пытаемся оценить, спам рассматриваемое письмо или нет. Функция msg.match выдает все термы из анализируемого письма, которые есть в спамном срезе данных (spam_learn.df). Если таких термов нет вообще (length(msg.match) < 1), то функция заменяет нулевые частоты значением cNone.
Проверяем детектор
Тестировать наш детектор, натренированный на письмах spam и easy_nonspam, будем сложными письмами: hard_nonspam.
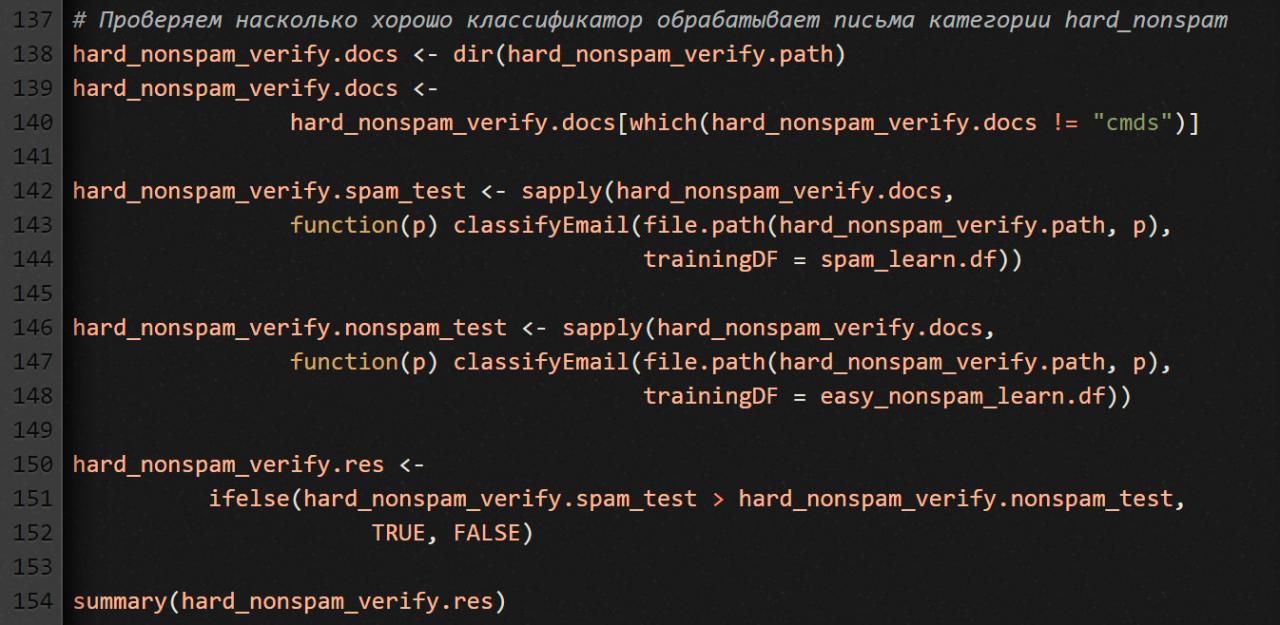
Что мы здесь делаем? Сначала, как и всегда, берем список файлов с письмами. Потом делаем два прогона через классификатор. Первый прогон для проверки принадлежности к спаму, второй — к не-спаму. В итоге у нас получается два вектора: hard_nonspam_verify.spam_test и hard_nonspam_verify.nonspam_test. Мы попарно сравниваем числовые значения из этих векторов и подсчитываем результат: сколько писем больше похоже на спам, а сколько — на не-спам.
Вам наверняка не терпится посмотреть, какой счет получился в итоге, и понять, насколько хорошо детектор спама справился со своей работой. Однако перед тем как показать результат, хочу напомнить тебе две вещи. 1) Нам заведомо известно, что в той выборке писем, которую мы только что тестировали, спама нет. Поэтому в идеале счетчик спама должен остаться нулевым. 2) Мы знаем, что письма этой выборки сложно классифицировать, потому что в них встречаются термы, которые являются яркими индикаторами спамности. Это я к чему? К тому, что результат скорее всего получится не очень вдохновляющим. Так какой же он?

Наш детектор спама сработал с погрешностью в 8%. Для коммерческой программы это, конечно, непозволительно много, но для простенького детектора, который мы с тобой писали в образовательных целях, результат вполне приятный. Особенно если учесть тот факт, что письма из категории hard_nonspam наш детектор здесь видел впервые, ведь они не были включены в тренировочную выборку.
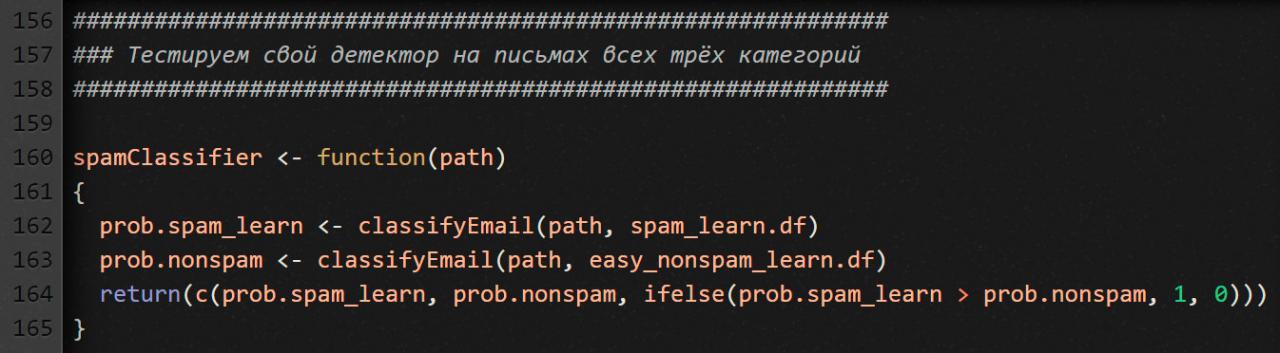
Тестируем детектор
Сначала те три действия, которые выполняли на предыдущем участке кода (для сравнения спама и не-спама), завернем в простенькую функцию spamClassifier. Что она делает? Если письмо больше похоже на спам, возвращает единицу, иначе ноль.
Теперь, чтобы протестировать работу детектора спама, загружаем письма из папок с суффиксом _verify. Ты же помнишь, что изначально мы поделили письма на две части: для тренировки детектора (суффикс _learn) и для его проверки (суффикс _verify)?
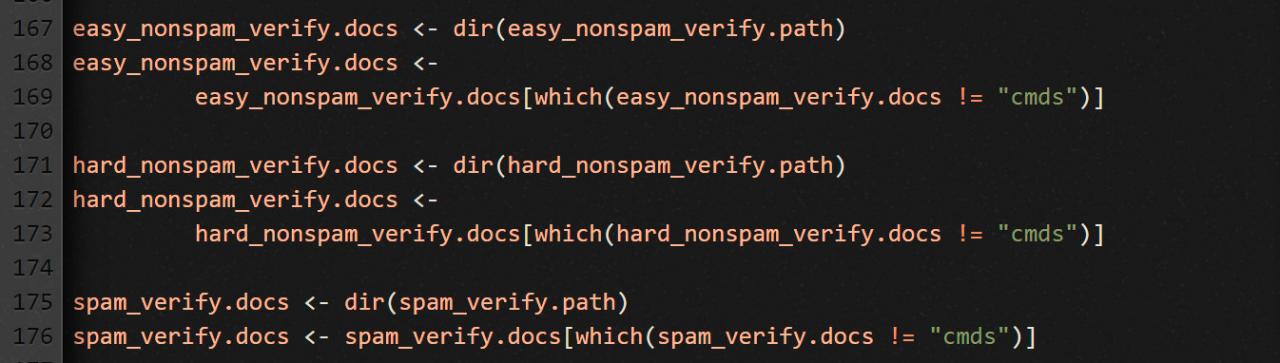
Дальше прогоняем детектор по письмам всех трех категорий. Прогоняем так же, как делали это раньше. Единственное отличие: мы для простоты используем функцию spamClassifier, а не classifyEmail.
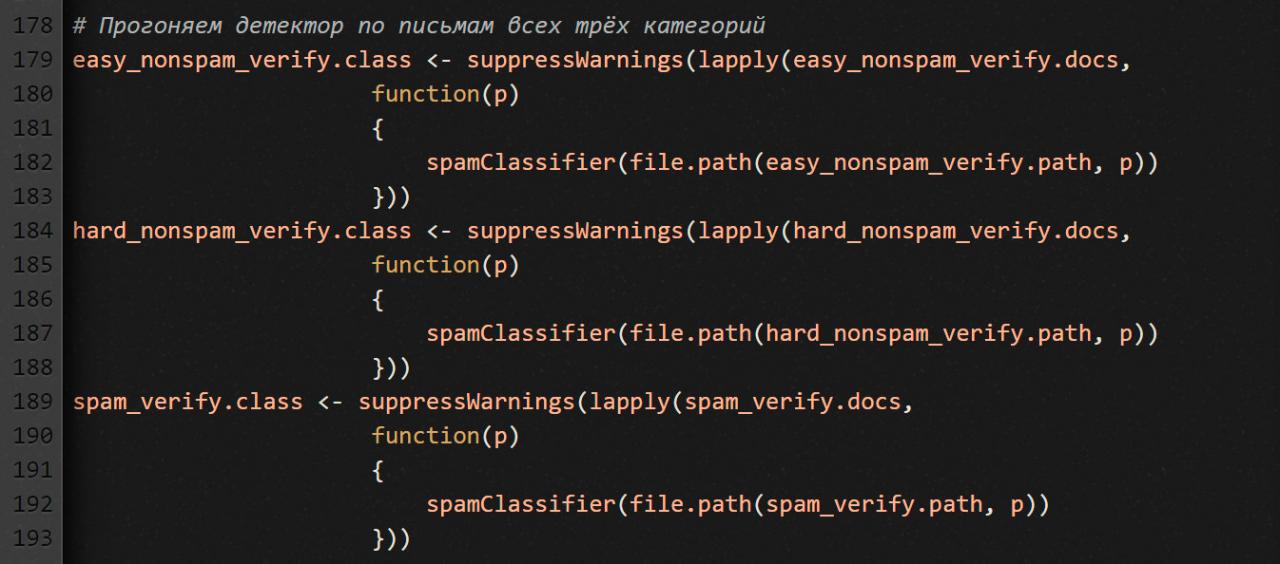
Затем готовим итоговый срез данных, по которому будет видно, как детектор отработал. Мы это уже делали чуть выше.
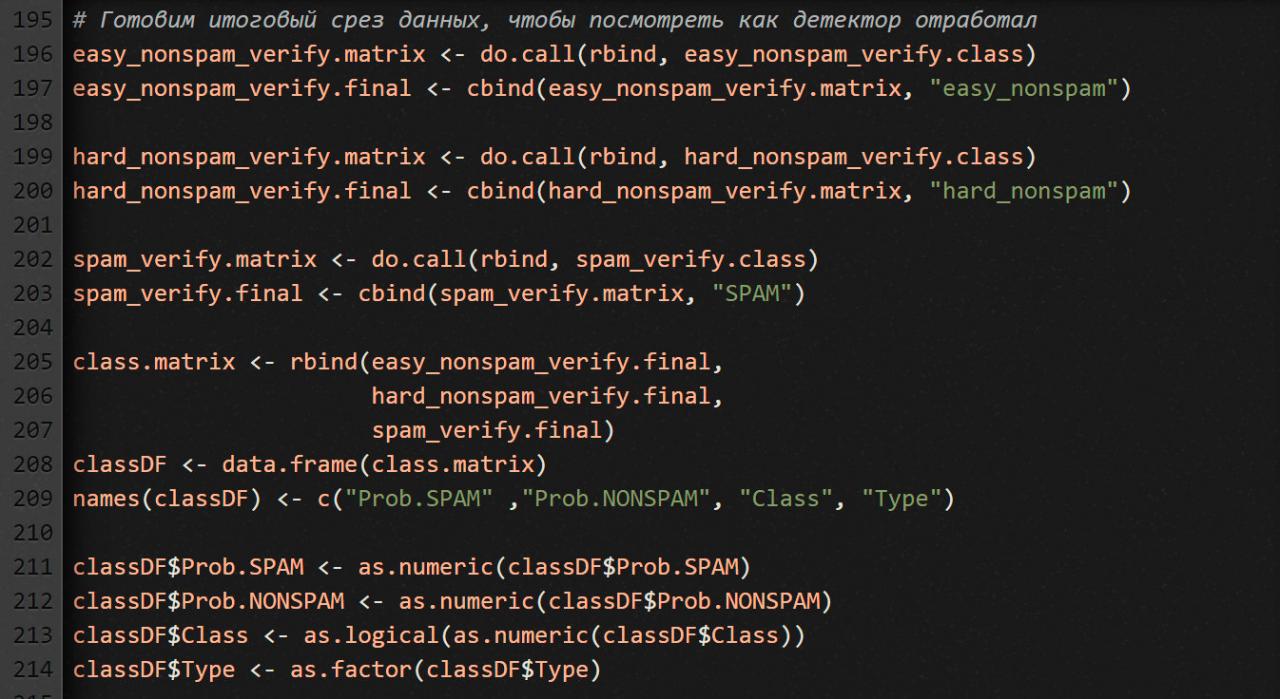
Посмотри, что получилось в итоге: head(classDF).
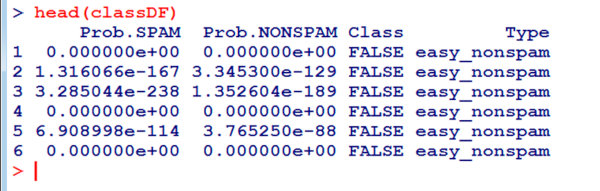
Судя по первым шести строчкам таблицы, детектор спама справляется со своей работой хорошо, но для более объективной картины давай подсчитаем ложноположительные и ложноотрицательные срабатывания — суммарно по всем письмам.
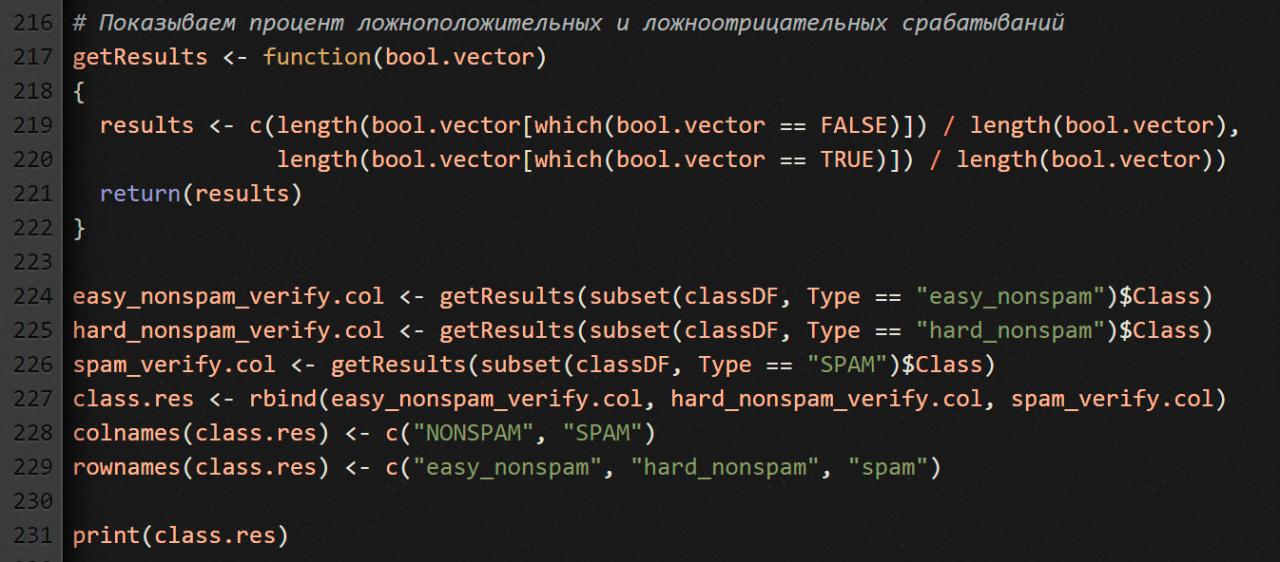
Что мы здесь делаем? Создаем матрицу из трех строк и двух столбцов. Строки — это фактическая категория письма (spam, easy_nonspam, hard_nonspam), а столбцы — категория, которую определил наш детектор спама. В идеале, у нас должно получиться [1, 1, 0] в первом столбце и [0, 0, 1] во втором. А вот как у нас получилось на самом деле.
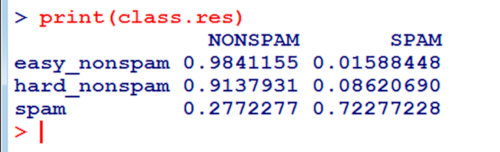
Из таблицы видно, что наш классификатор работает хоть и не идеально, но вполне хорошо.
Рисуем результат на графике
Что мы здесь делаем? Отражаем на графике, как сильно (в процентах) письмо похоже на спам (ось OX) и на не-спам (ось OY). Причем выводим данные в логарифмическом масштабе. Зачем такое ухищрение? Потому что разброс значений, которые мы наносим на график, очень большой. Поэтому без логарифмического преобразования результат получился бы менее наглядным.
График, сохраненный в формате PDF, ты найдешь в своей рабочей папке, в подкаталоге images.
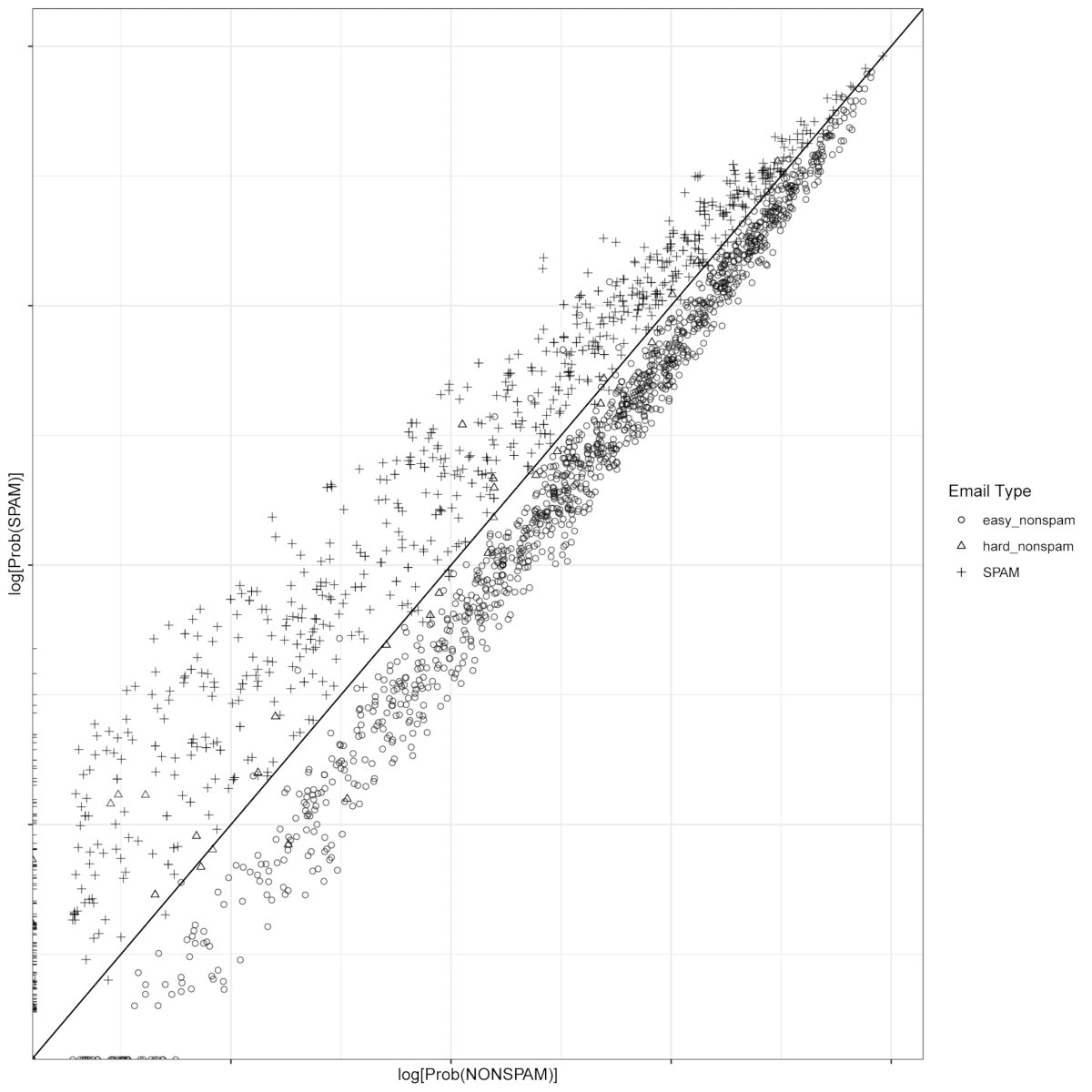
В идеале, весь спам должен оказаться выше диагональной линии, а не-спам — ниже. Как видишь из рисунка, наш результат хоть и выглядит весьма неплохо, но все-таки не идеален.
Анализируя график, мы можем извлечь некоторое интуитивное представление о слабых местах своего детектора. Мы видим, что некоторые письма прижаты к оси OX. У них значение Prob(SPAM) равняется нулю. Другие прижаты к OY — у них значение Prob(SPAM) равняется нулю. А некоторые письма вообще прижаты к точке ноль.

Все эти наблюдения показывают, что мы подготовили не очень хороший набор обучающих данных для предотвращения спама. Поскольку, глядя на результат обработки проверочных писем, мы видим, что существует гораздо больше термов, которые было бы неплохо использовать в качестве индикаторов отсутствия спама, чем набор, который мы фактически используем.
Это непонятно. Наконец, мы разработали упрощенный детектор спама. Конечно, его можно развивать и улучшать. Это то, что я предлагаю вам сделать в качестве домашнего задания. Если решитесь, обязательно поделитесь своими успехами в этой сфере в комментариях к статье.