Библиотечный код может составлять львиную долю программы. Конечно, ничего интересного в этом коде нет. Поэтому его анализ можно смело опустить. Нет необходимости тратить на идентификацию функций наше драгоценное время. Что, если дизассемблер неправильно прочитал имена функций? Что, многотонный список надо самому изучать? У хакеров есть проверенные методы решения подобных задач — о них мы сегодня и поговорим и о способах как идентифицировать библиотечные функции.

При чтении текста программы, написанной на языке высокого уровня, только в исключительных случаях мы проверяем реализацию стандартных библиотечных функций, таких как printf. И почему? Его назначение хорошо известно, и если есть какие-то неясности, вы всегда можете посмотреть описание …
Анализ дизассемблерного листинга — дело другое. Имена функций отсутствуют, за редким исключением, и невозможно «с первого взгляда» определить, является ли это printf или что-то еще. Вы должны покопаться в алгоритме … Легко сказать — углубитесь! Тот же printf представляет собой сложный интерпретатор спецификационных строк — сразу не разобраться! Но есть и более чудовищные функции. Самое обидное, что алгоритм их работы не имеет ничего общего с анализом исследуемой программы. Тот же новый может выделять память из кучи Windows, а также реализовывать собственный менеджер. Что это значит для нас? Достаточно знать, что это именно новая, то есть функция выделения памяти, а не свободная или, например, открытая.
Доля библиотечных функций в программе составляет в среднем от пятидесяти до девяноста процентов. Он особенно высок для программ, написанных в средах визуальной разработки, использующих автоматическую генерацию кода (например, Microsoft Visual Studio, Delphi). Кроме того, библиотечные функции иногда намного сложнее и запутаннее, чем сам рутинный программный код. Обидно, что большая часть усилий по анализу тратится зря …Как бы оптимизировать это?
При идентификации библиотечных функций на помощь вновь приходит IDA
Уникальная способность IDA различать стандартные библиотечные функции множества компиляторов выгодно отличает ее от большинства других дизассемблеров, этого делать не умеющих. К сожалению, IDA (как и все, созданное человеком) далека от идеала: каким бы обширным ни был список поддерживаемых библиотек, конкретные версии конкретных поставщиков или моделей памяти могут отсутствовать. И даже из тех библиотек, что ей известны, распознаются не все функции (о причинах будет рассказано чуть позже).
Впрочем, неидентифицированная функция — это полбеды, неправильно распознанная функция — много хуже, ибо это приводит к ошибкам (иногда трудноуловимым) в анализе исследуемой программы или ставит исследователя в глухой тупик. Например, вызывается fopen, и возвращенный ею результат спустя некоторое время передается free — с одной стороны: почему бы и нет? Ведь fopen возвращает указатель на структуру FILE, а free ее удаляет. А если free никакой не free, а, скажем, fseek? Пропустив операцию позиционирования, мы не сможем правильно восстановить структуру файла, с которым работает программа.
Опознание функций
Распознать ошибки IDA будет легче, если представлять, как именно она выполняет распознавание. Многие почему‑то считают, что здесь задействован тривиальный подсчет CRC (контрольной суммы). Что ж, подсчет CRC — заманчивый алгоритм, но, увы, для решения данной задачи он непригоден. Основной камень преткновения — наличие непостоянных фрагментов, а именно перемещаемых элементов. И хотя при подсчете CRC перемещаемые элементы можно просто игнорировать (не забывая проделывать ту же операцию и в идентифицируемой функции), разработчик IDA пошел другим, более запутанным и витиеватым, но и более производительным путем.
Ключевая идея состоит в том, что нет необходимости тратить время на вычисление CRC. Для предварительной идентификации функции подходит одиночное посимвольное сравнение за вычетом перемещаемых элементов (они игнорируются и не участвуют в сравнении). Точнее, не сравнение, а поиск заданной последовательности байтов в справочной базе данных, организованной в виде двоичного дерева. Известно, что время двоичного поиска пропорционально логарифму количества записей в базе данных. Здравый смысл подсказывает, что длина модели (другими словами, сигнатура, то есть сравниваемая последовательность) должна быть достаточной для однозначной идентификации функции. Однако разработчик IDA по причинам, неизвестным авторам, решил придерживаться первых тридцати двух байтов, что (особенно если вычесть пролог, который практически одинаков для всех функций) довольно мал.
И это правильно! Многие функции попадают на один и тот же лист дерева, возникает коллизия — неоднозначность идентификации функций. Чтобы разрешить ситуацию, CRC16 подсчитывается от тридцать второго байта до первого сдвинутого элемента для всех функций «коллизии» и сравнивается с CRC16 опорных функций. В большинстве случаев это работает, но если первый движущийся элемент находится слишком близко к тридцатисекундному байту, последовательность контрольных сумм слишком коротка или даже равна нулю (это может быть тридцать второй байт движущегося элемента, почему бы и нет?) … в случае повторного столкновения мы находим в функциях байт, в котором все они различаются и напоминают нам о своем смещении в базе.
Все это (да простит авторов разработчик IDA!) напоминает следующий анекдот. Поймали туземцы немца, американца и украинца и говорят им: мол, или откупайтесь чем‑нибудь, или съедим. На откуп предлагается: миллион долларов (только не спрашивайте, зачем туземцам миллион долларов, — может, костер жечь), сто щелбанов или съесть мешок соли. Ну, американец достает сотовый, звонит кому‑то… Приплывает катер с миллионом долларов, и американца благополучно отпускают. Немец в это время героически съедает мешок соли, и его полумертвого спускают на воду. Украинец же ел соль, ел‑ел, две трети съел, не выдержал и говорит: а, ладно, черти, бейте щелбаны. Бьет вождь его, и только девяносто ударов отщелкал, тот не выдержал и говорит: да нате миллион, подавитесь!
Так и с IDA, посимвольное сравнение не до конца, а только тридцати двух байтов, подсчет CRC не для всей функции, а сколько случай на душу положит, наконец, последний ключевой байт — и тот‑то «ключевой», да не совсем. Дело в том, что многие функции совпадают байт в байт, но совершенно различны по названию и назначению. Не веришь? Тогда как тебе понравится следующее:
read: write:
sub rsp, 28h sub rsp, 28hcall _read call _writeadd rsp, 28h add rsp, 28hretn retnТут без анализа перемещаемых элементов никак не обойтись! Причем это не какой‑то специально надуманный пример — подобных функций очень много. В частности, библиотеки от Embarcadero (в прошлом от Borland) ими так и кишат. Поэтому в былые времена IDA часто «спотыкалась» и впадала в грубые ошибки. Тем не менее сейчас IDA заметно возмужала и уже не страдает детскими болячками. Для примера скормим компилятору C++Builder такую функцию:
void demo(){printf("DERIVEDn");}Последняя версия IDA сейчас 7.4, между тем я использую IDA 7.2, и она чаще всего успешно идентифицирует почти любые функции. В нашем случае результат выглядит следующим образом:
text:0000000140001000 void demo(void) proc near.text:0000000140001000 sub rsp, 28h.text:0000000140001004 lea rcx, _Format ; "DERIVED\n".text:000000014000100B call printf.text:0000000140001010 add rsp, 28h.text:0000000140001014 retn.text:0000000140001014 void demo(void) endpТо есть дизассемблер правильно идентифицировал имя функции. Но так бывает далеко не всегда и не со всеми библиотечными функциями. А когда проблемы возникают с ними, кодокопателю анализировать становится сложновато. Бывает, сидишь, тупо уставившись в листинг дизассемблера, и никак не можешь понять: что же этот фрагмент делает? И только потом обнаруживаешь — одна или несколько функций опознаны неправильно!
Для уменьшения количества ошибок IDA пытается по стартовому коду распознать компилятор, подгружая только библиотеку его сигнатур. Из этого следует, что «ослепить» IDA очень просто — достаточно слегка видоизменить стартовый код. Поскольку он, по обыкновению, поставляется вместе с компилятором в исходных текстах, сделать это будет нетрудно. Впрочем, хватит и изменения одного байта в начале startup-функции. И все, хакер склеит ласты!
К счастью, в IDA предусмотрена возможность ручной загрузки базы сигнатур (FILELoad fileFLIRT signature file), но попробуй‑ка вручную определить, сигнатуры какой именно версии библиотеки требуется загружать! Наугад — слишком долго… Хорошо, если удастся визуально опознать компилятор. Опытным исследователям это обычно удается, так как каждый из них (компилятор, а не исследователь) имеет свой уникальный «почерк». К тому же существует принципиальная возможность использования библиотек из поставки одного компилятора в программе, скомпилированной другим компилятором. Словом, будь готов к тому, что в один прекрасный момент ты можешь столкнуться с необходимостью самостоятельно идентифицировать библиотечные функции. Решение этой задачи состоит из трех этапов. Первое — определение самого факта «библиотечности» функции, второе — определение происхождения библиотеки и третье — идентификация функции по этой библиотеке.
Учитывая, что линкер обычно располагает функции в порядке перечисления obj-модулей и библиотек, а большинство программистов указывают сначала собственные obj-модули, а библиотеки — потом (кстати, так же поступают и компиляторы, самостоятельно вызывающие линкер после окончания работы), можно заключить: идентифицированые библиотечные функции размещаются в конце программы, а собственно ее код — в начале. Конечно, из этого правила есть исключения, но все же срабатывает оно достаточно часто.
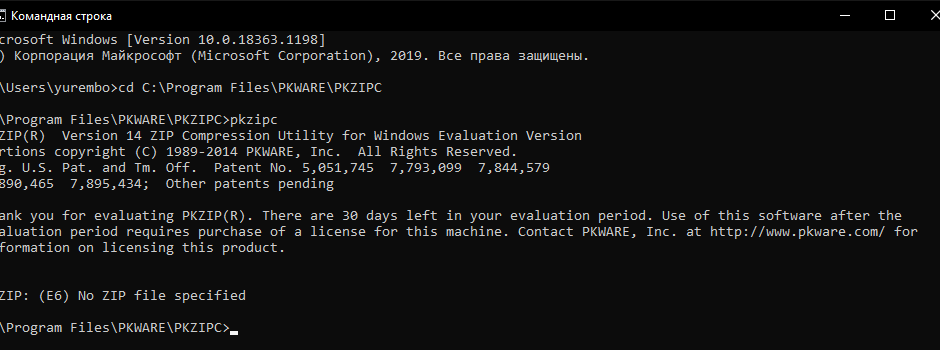
Рассмотрим, к примеру, структуру консольной версии общеизвестной программы pkzip.exe последней на данный момент 14-й версии. Она существенно легче, чем ее оконная версия. Ее вывод в консоли имеет следующий вид.

Консольный вывод приложения pkzipc.exe
Во время загрузки приложения в IDA та делает предположение, что это ROM для SNES. Забавно, но выберем AMD64, если, конечно, установлена 64-разрядная версия утилиты.

Загрузка pkzipc.exe в IDA
На диаграмме, построенной IDA Pro 7.2, видно, что все библиотечные функции находятся в сегменте кода среди обычных функций до начала сегмента данных.
![]()
Диаграмма для pkzipc.exe
Самое интересное: startup-функция в подавляющем большинстве случаев расположена в самом начале региона библиотечных функций или находится в непосредственной близости от него. Найти же саму startup не проблема — она совпадает с точкой входа в файл!
Таким образом, мы можем с большой уверенностью сказать, что все функции, расположенные «ниже» загрузки (то есть по более высоким адресам), являются идентифицироваными библиотечными функциями. Вы видите, распознала ли их IDA или переложила эту заботу на вас? Возможны два варианта: никакая функция не распознается вообще или не распознается только часть функций.
Если не распознана ни одна функция, скорее всего, IDA не сумела опознать компилятор или использовались неизвестные ей версии библиотек. Для примера подсунем IDA другой популярный архиватор — peazip., который, как известно, написан на объектном паскале.
![]()
Диаграмма для peazip.exe
На диаграмме видно, что IDA не опознала ни одной библиотечной функции! Вот так новость! Смотрим, какой компилятор определен дизассемблером: «Plan FLIRT signature: SEH for vc64 7-14». Картина проясняется: IDA неправильно определила компилятор! Но что она скажет, если мы предложим ей pkzipw. (for Windows)?
![]()
Диаграмма для pkzipw.exe
Гораздо лучше! Мы знаем, что препарируемое приложение написано на C++ и откомпилировано в Visual Studio. Поэтому IDA выдает сносные результаты. Между тем техника распознавания компиляторов — разговор особый, а вот распознание версий библиотек — это то, чем мы сейчас и займемся.
Определение библиотек и их версий
Прежде всего, многие из них содержат копирайты с указанием имени производителя и версии библиотеки, просто поищи текстовые строки в бинарном файле. Если их нет, не беда — ищем любые другие текстовые строки (как правило, сообщения об ошибках) и простым контекстным поиском пытаемся найти их во всех библиотеках, до которых удастся дотянуться (хакер должен иметь широкий набор компиляторов и библиотек на своем жестком диске или SSD-накопителе — это уж кому как больше нравится).
Возможные варианты: другой строки текста нет; строки существуют, но они не уникальны — их можно найти во многих библиотеках; наконец, нужного фрагмента нигде не было. В первых двух случаях необходимо выбрать из одной (нескольких) библиотечных функций характеристическую последовательность байтов, не содержащую перемещаемых элементов, и снова попытаться найти ее во всех доступных библиотеках. Если это не поможет, то, к сожалению, у вас нет библиотеки, которую вы ищете, и ситуация зашла в тупик.
Тупик, да не совсем! Конечно, больше нельзя будет автоматически восстанавливать имена функций, но все же есть надежда, что назначение функций будет быстро выяснено. Имена функций Windows API, которые вызываются из библиотек, позволяют идентифицировать хотя бы категорию библиотеки (например, работа с файлами, памятью, графикой). Как обычно, математические функции содержат множество инструкций сопроцессора.
Дизассемблирование очень похоже на разгадывание кроссворда (хотя не факт, что хакеры любят разгадывать кроссворды) — неизвестные слова угадываются за счет известных. Применительно к данному случаю в некоторых контекстах название функции вытекает из ее использования. Например, запрашиваем у пользователя пароль, передаем его функции X вместе с эталонным паролем, если результат завершения нулевой — пишем «пароль ОК», и, соответственно, наоборот. Не подсказывает ли твоя интуиция, что функция X не что иное, как strcmp? Конечно, это простейший случай, но, столкнувшись с незнакомой подпрограммой, никогда не спеши впадать в отчаяние и приходить в ужас от ее «монструозности». Просмотри все вхождения, обращая внимания, кто вызывает ее, когда и сколько раз.
Статистический анализ проливает свет на очень многое (функции, как и буквы алфавита, встречаются каждая со своей частотой), а контекстная зависимость дает пищу для размышлений. Так, функция чтения из файла не может предшествовать функции открытия!
Другие зацепки: аргументы и константы. Ну, с аргументами все более или менее ясно. Если функция получает строку, то это, очевидно, функция из библиотеки работы со строками, а если вещественное значение — возможно, функция математической библиотеки. Количество и тип аргументов (если их учитывать) весьма сужают круг возможных кандидатов. С константами же еще проще — очень многие функции принимают в качестве аргумента флаг, допускающий ограниченное количество значений. За исключением битовых флагов, которые все похожи друг на друга, довольно часто встречаются уникальные значения, пускай не однозначно идентифицирующие функцию, но все равно сужающие круг «подозреваемых». Да и сами функции могут содержать характерные константы. Скажем, встретив стандартный полином для подсчета CRC, можно быть уверенным, что «подследственная» вычисляет контрольную сумму…
Мне могут возразить: мол, все это частности. Возможно. Но, идентифицировав часть функций, назначения остальных можно вычислить «от противного». И уж по крайней мере понять, что это за библиотека такая и где ее искать.
Заключение
Идентификация алгоритмов (то есть назначения функции) становится намного проще, если знать сами эти алгоритмы. В частности, код, выполняющий LZ-сжатие (декомпрессию), настолько типичен, что его можно распознать с первого взгляда. Достаточно знать этот механизм упаковки. Напротив, если вы об этом не подозреваете, проанализировать программу будет непросто! Зачем изобретать велосипед, если можно взять уже готовое? Хотя есть мнение, что хакер — это прежде всего хакер, а затем программист (а почему он должен уметь программировать?). В жизни все наоборот — программист, который не умеет программировать, будет жить — он там много библиотек, подключите — и все заработает! С другой стороны, хакеру необходимо знать основы, без них далеко не уплывешь (конечно, серийный номер программы можно сломать без сложных математических расчетов).
Очевидно, библиотеки были созданы для этой цели, чтобы избавить разработчиков от необходимости копаться в этих областях, без которых они чувствуют себя хорошо. Увы, у исследователей программы нет простых средств, им приходится думать руками и головой, и даже … пятая точка опоры, спинной мозг, — единственный способ демонтировать серьезные программы. . Иногда готовое решение приходит в поезде или во сне …
Идентификация библиотечных функций — самая сложная часть декомпозиции, и возможность идентифицировать их имена по сигнатурам — это здорово.