Семейство псевдослучайных функций может быть построено из любого псевдослучайного генератора, используя, например, конструкцию «GGM», данную Голдрайхом, Гольдвассером и Микали. Хотя на практике блочные шифры используются большую часть времени, когда требуется псевдослучайная функция, они, как правило, не составляют семейство псевдослучайных функций, потому что блочные шифры, такие как AES, только определены. для ограниченного количества записей и размеров ключей.

В 1984 году Голдрайх, Гольдвассер и Микали формализовали концепцию псевдослучайных функций и предложили реализацию PRF, основанную на псевдослучайном генераторе удвоения длины (PRG). С тех пор псевдослучайные функции оказались чрезвычайно важной абстракцией, которая нашла применение в различных областях, таких как аутентификация сообщений и доказательство теорем.
В этой статье мы расскажем:
-
Что из себя представляют случайные функции (RF)
-
Что из себя представляют псевдослучайные функции (PRF)
-
Кто же такие эти ваши семейства
-
PRF vs. PRG
-
При чём тут блочные шифры
Случайность
Уже из названия становится понятно, что псевдослучайная функция — это нечто «выглядящее» как случайная функция. Ну а что такое случайная функция в нашем случае? Для начала ограничим нашу область рассмотрения функциями отображающими строку из нулей и единиц длиной  в строку из нулей и единиц такой же длины
в строку из нулей и единиц такой же длины  , то есть
, то есть

Этого, вообще говоря, можно и не делать, и рассматривать отображения строк одной длины в строки другой длины, но в этом случае придётся уделять внимание различиям в размерности. Далее введём множество всех функций, выполняющих отображение  и обозначим его
и обозначим его  .
.
Рассмотрим мощность этого множества. Очевидно, что  .
.




Теперь мы можем определить случайную функцию. Случайная функция – это любая случайно выбранная функция из  . Проще говоря, мы берём наши
. Проще говоря, мы берём наши  строк и каждой сопоставляем какую-то из тех же
строк и каждой сопоставляем какую-то из тех же  строк. Причем сопоставление происходит с равномерным распределением, то есть
строк. Причем сопоставление происходит с равномерным распределением, то есть

Где  – функция из
– функция из  , а
, а  – фиксированная точка.
– фиксированная точка.
Псевдослучайность
Интуитивно, псевдослучайность – это что-то выглядящее, как случайность. И формальное определение так и вводится, только похожесть псевдослучайной функции на случайную определяется строго.
Давайте выпишем несколько равенств, верных для случайной функции:

Почти то же самое, но для наших целей вполне сгодится:

Для чётных  можно выписать следующее:
можно выписать следующее:

Где  – число сочетаний из
– число сочетаний из  по
по  (нужно выбрать
(нужно выбрать  позиций из
позиций из  возможных).
возможных).
Подобных равенств можно выписать очень много. Скажем, к примеру, что мы придумали 20 таких равенств. Назовём их тестами и обозначим следующим образом:

Тогда можно определить псевдослучайною функцию, как функцию, которая удовлетворяет тестам с заданной точностью  :
:

Где  – случайная функция, а
– случайная функция, а  – функция, которую мы тестируем.
– функция, которую мы тестируем.
Но у такого определения есть существенный минус. Что если у кул-хацкера, который пытается вытащить полезную информацию из результата работы псевдослучайной функции, есть тест, которого нет у нас? Вероятно, для него эта функция окажется не такой уж и случайной. Поэтому введём несколько иное определение псевдослучайной функции.
Назовём функцию 
 -псевдослучайной, если для любого теста
-псевдослучайной, если для любого теста  с полиномиальной сложностью, выполнение которого занимает времени не более чем
с полиномиальной сложностью, выполнение которого занимает времени не более чем  верно
верно

Семейства
Окей, мы поняли, что такое случайная функция, что такое псевдослучайная функция, но никаких семейств так и не видно. На самом деле они уже здесь, нам достаточно взять некоторое количество псевдослучайных функций, удовлетворяющих нашим условиям, обозвать их  и семейство готово:
и семейство готово:
Семейство псевдослучайных функций – это эффективно вычислимая функция двух переменных  , такая, что
, такая, что  , где каждая из
, где каждая из  является псевдослучайной. Переменная
является псевдослучайной. Переменная  называется ключом функции.
называется ключом функции.
Положим далее  .
.
Стоит отметить, что выбор конкретного  эквивалентен выбору конкретной функции из семейства.
эквивалентен выбору конкретной функции из семейства.
В начале статьи мы обсудили множество всех функций выполняющих отображение  и обозначили его
и обозначили его  . Так вот, получается что семейство
. Так вот, получается что семейство  задаёт распределение над множеством
задаёт распределение над множеством  .
.
Определение, данное выше, можно переформулировать в более привычный вид, в котором оно в основном встречается в статьях и учебниках:
 называется семейством псевдослучайных функций, если для случайного
называется семейством псевдослучайных функций, если для случайного  ни один эффективный алгоритм
ни один эффективный алгоритм  с полиномиальной временной сложностью не сможет отличить
с полиномиальной временной сложностью не сможет отличить  от
от  .
.
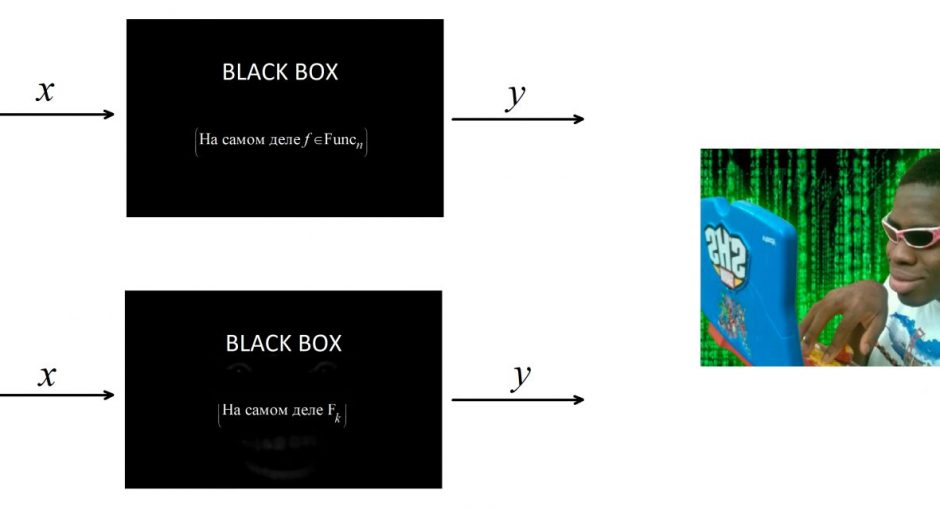
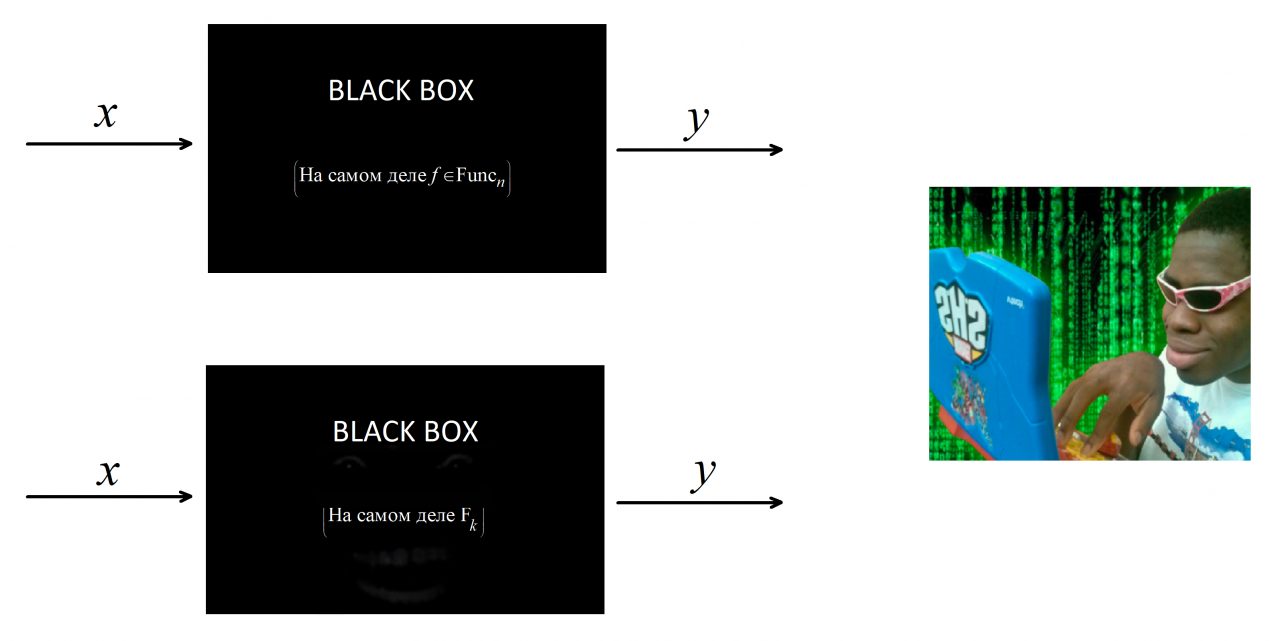
Наглядное пояснение
Вероятно, так будет проще осознать, что же в конечном итоге представляет из себя это семейство. Пусть есть две черных коробки, которые могут принимать на вход битовые строки и в ответ выдавать какие-то другие битовые строки. Примем, что на входе и на выходе коробок строки имеют определённую одинаковую длину. Отмечу, что выход этих коробок определяется только строкой на входе. То есть не может быть такого, что мы подали на вход какой-то коробки  и на выходе получили
и на выходе получили  , а потом, через некоторое время, мы снова подали на вход
, а потом, через некоторое время, мы снова подали на вход  , но на выходе получили
, но на выходе получили  . Пусть также есть злой хацкер, которому позарез нужно понять, какая из этих двух коробок скрывает в себе труЪ-случайную функцию, а какая просто притворяется. Этот хацкер может делать с этими коробками всё, что угодно. То есть подавать строки и считывать. Так вот, если тот, кто придумывал
. Пусть также есть злой хацкер, которому позарез нужно понять, какая из этих двух коробок скрывает в себе труЪ-случайную функцию, а какая просто притворяется. Этот хацкер может делать с этими коробками всё, что угодно. То есть подавать строки и считывать. Так вот, если тот, кто придумывал  , сделал всё правильно, то при случайно выбранном
, сделал всё правильно, то при случайно выбранном  у хацкера ничего не выйдет (за вменяемое время).
у хацкера ничего не выйдет (за вменяемое время).
PRF vs. PRG
PRG – это псевдослучайный генератор. Звучат названия достаточно похоже, но путать их не стоит. Эти два понятия можно связать, получив из PRG – PRF, а из PRF – PRG. Почитать подробно, что такое PRG, можно тут. Если вкратце, то PRG это эффективно вычислимая функция (алгоритм), принимающая на вход случайную битовую строку длины  (seed) и выдающая псевдослучайную битовую строку длины
(seed) и выдающая псевдослучайную битовую строку длины  . Почитать про то, как получить из PRG семейство псевдослучайных функций с доказательством того, что полученная конструкция действительно PRF можно в работе, упомянутой в самом начале статьи. А вот в обратную сторону всё намного проще. Достаточно положить
. Почитать про то, как получить из PRG семейство псевдослучайных функций с доказательством того, что полученная конструкция действительно PRF можно в работе, упомянутой в самом начале статьи. А вот в обратную сторону всё намного проще. Достаточно положить

Где  – операция конкатенации, и мы получим простейший пример получения PRG из PRF. Очевидно, что подобных примеров можно придумать очень много. Отсюда напрашивается логичный вывод, что PRF понятие более мощное, нежели PRG.
– операция конкатенации, и мы получим простейший пример получения PRG из PRF. Очевидно, что подобных примеров можно придумать очень много. Отсюда напрашивается логичный вывод, что PRF понятие более мощное, нежели PRG.
Про блочные шифры
Наделив нашу PRF  парой дополнительных свойств мы получим ещё одну интересную абстракцию, называемою псевдослучайными перестановками. Для того, чтобы стать семейством псевдослучайных перестановок,
парой дополнительных свойств мы получим ещё одну интересную абстракцию, называемою псевдослучайными перестановками. Для того, чтобы стать семейством псевдослучайных перестановок,  должна быть биективной и эффективно вычислимой в обоих направлениях для всех значений
должна быть биективной и эффективно вычислимой в обоих направлениях для всех значений  . То есть задача вычисления
. То есть задача вычисления  должна иметь единственный верный ответ и не должна составлять для нас особого труда.
должна иметь единственный верный ответ и не должна составлять для нас особого труда.
Здесь уже можно догадаться, причём же тут блочные шифры. По сути, псевдослучайная перестановка представляет из себя ядро блочного шифра: мы берём исходное сообщение, разбиваем его на блоки длины  , применяем к каждому из блоков
, применяем к каждому из блоков  , где
, где  известно и отправителю и получателю, и затем отправляем наше сообщение, которое на данном этапе выглядит как набор случайных (псевдослучайных) битов.
известно и отправителю и получателю, и затем отправляем наше сообщение, которое на данном этапе выглядит как набор случайных (псевдослучайных) битов.
В качестве примера блочного шифра, использующего псевдослучайные перестановки, можно привести AES.
Заключение
Случайность имеет множество применений в науке, искусстве, статистике, криптографии, играх, азартных играх и других областях. Например, случайное распределение в рандомизированных контролируемых испытаниях помогает ученым проверять гипотезы, а случайные и псевдослучайные числа также используются в видеоиграх, таких как видеопокер.
Такие приложения имеют разные уровни требований, что приводит к использованию разных методов. Математически существуют различия между рандомизацией, псевдослучайным и квазирандомизационным, а также между генератором случайных чисел и генератором псевдослучайных чисел. Например, криптографические приложения, как правило, предъявляют строгие требования, в то время как другие применения (например, создание «котировок дня») могут использовать более свободный стандарт псевдослучайности.