Hibernate — популярнейший фреймворк для работы с базами данных на Java. В нем реализован свой язык запросов (HQL), но есть лазейка, которая позволяет выйти за его пределы и провести обычную SQL-инъекцию.

В общем смысле object-relational mapping (ORM) — это связывание (отображение, mapping) объектно-ориентированной модели данных с традиционными реляционными базами данных. Звучит такое определение замысловато, так что попробую объяснить его на пальцах.
У нас есть объектно-ориентированный язык вроде Java — в нем все построено на классах и объектах. У объектов есть состояния — это совокупность значений их полей.
С другой стороны, у нас есть обычные реляционные СУБД вроде MySQL, где данные хранятся в виде записей в таблицах и некоторые таблицы связаны между собой. Нередко возникает задача сохранить состояние какого-то объекта в базу данных. Решается она просто: достаточно разобрать объект на простейшие элементы (строки, числа, булевы значения…) и засунуть в таблицу. Восстанавливаются данные обратной операцией.
[ad name=»Responbl»]
Но если сохраняемые объекты сложнее (к примеру, внутри них есть ссылки на другие объекты или многомерные массивы), то распихать все в нужные таблички и с нужными типами данных — это серьезная работа, хоть по большей части и рутинная.
Для экономии времени и усилий придуманы ORM-фреймворки. Они добавляют некую прослойку, и нам остается работать в рамках ООП: создаем, меняем и удаляем объекты и можем быть уверены, что БД будет отражать их
состояние.

Hibernate — это ORM-фреймворк для Java, и он феноменально популярен. При этом Hibernate — громоздкая и сложная для понимания вещь (впрочем, программистам на Java не привыкать). Для нас же интересно, что имеется ти-
повой подход к взлому. Но для его понимания мне придется в двух словах рассказать, как работает Hibernate.
Первым делом формируются сущности, которые будут храниться в базе данных. Это так называемые persistent-классы. Далее необходимо связать эти классы с таблицами в базе данных и определить их отношения («один ко многим», «многие ко многим»). Выглядит это примерно следующим образом (при использовании XML-файла, можно и аннотации юзать).
Как мы видим, мы указываем связь класса (Good — товар) с определенной таблицей (Goods). А далее — имен полей класса с одноименными столбцами таблицы с указанием типов (ID товара, название и его цена).
После этого нужно отредактировать файл hibernate.cfg.xml, в котором хранится информация по подключению. Еще один плюс Hibernate в том, что он сам будет менять SQL-запросы в зависимости от того, какая СУБД используется (а для нас это еще одно из мест, где могут быть креды от СУБД), — код приложения при этом остается неизменным. Далее мы можем сохранять, обновлять или искать объекты простейшими командами:

где session — это объект сессии для работы с Hibernate. Но это простейшие действия. Для чего-то более сложного есть возможность использовать Hibernate Query Language (а можно и нативный SQL). HQL чем-то похож на SQL, и запрос на нем выглядит примерно следующим образом.
![]()
Здесь мы ищем объект, у которого в названии есть строка any_string. Заметь, что здесь мы работаем с сущностями не баз данных (таблицы, столбцы), а классов (имя класса — Good, а не как у таблицы — Goods).
Запросы на HQL могут быть сложнее, но все равно они не уходят дальше типовых операций (select, update, delete и подобные). То есть здесь нет возможности вызывать какие-то процедуры или функции СУБД.
[ad name=»Responbl»]
Важно еще раз подчеркнуть, что, используя Hibernate, мы работаем с объектами и классами, а фреймворк сам смотрит маппинг и отправляет в СУБД SQL-запросы на выборку или изменение данных.
Как и с SQL, при работе с HQL-запросами есть два подхода. Первый — это обычные запросы, когда запрос и пользовательские данные смешиваются.

Второй — это параметризированные запросы, в них данные не смешиваются с командами, так как передаются отдельно.

И хотя второй вариант настолько распространен (в случае как SQL, так и HQL), что даже создается ложное впечатление, будто в приложениях на Java не может быть SQL-инъекций, первый вариант все же встречается.
Что же мы можем сделать, если получится подпихнуть свои данные в запрос? Во-первых, по аналогии с SQL мы можем поползать по данным других объектов. Здесь можно найти примеры, вот один из них.

Предполагается, что есть persistence-классы Book и User. Мы можем вставить нашу строку в like. Так как в HQL запрещен union select, можно вытягивать данные подзапросами. То есть мы можем ползать по всем данным объектов
persistence-классов.
Есть и тулза, которая в этом поможет, — HQLmap. Она позволяет автоматизировать процесс раскрутки таких HQL.
Но все это детские игры. Самое лакомое было презентовано компанией SynAcktiv на недавней конференции. Исследователи обнаружили возможность вывалиться из HQL в SQL и получить полноценную SQL injection, с которой уже понятно, что делать.
Чтобы разобраться, как это происходит, нужно знать, как работает преобразование HQL в SQL. Предположим, у нас есть запрос
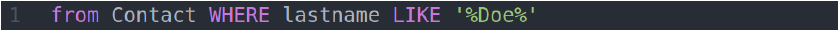
Он транслируется в следующий код на SQL:

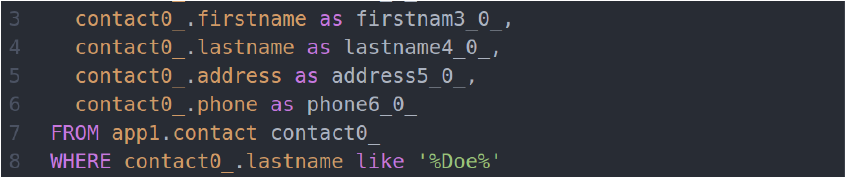
Здесь все понятно и логично. Но между SQL и HQL есть разница в тонкостях синтаксиса. В HQL слеш () не является специальным символом для экранирования других символов в SQL. Вместо этого в HQL для экранирования кавычки используется еще одна одинарная кавычка. Объединив знания об этих фактах, можно сделать такой запрос, который будет валидным HQL-запросом, но после преобразования в SQL вывалится из полученного SQL-запроса.
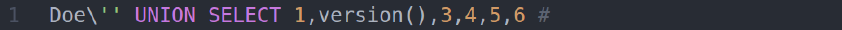
Как видишь, мы добавили слеш и две одинарные кавычки. Но для HQL кавычка экранирует другую кавычку. Выходит, что мы не вываливаемся из HQL-выражения. А потому имеем валидный HQL-запрос.

После конвертации в SQL слеш экранирует первую из двух одинарных кавычек, и мы вываливаемся из SQL-выражения без генерации ошибок парсером (ему могли бы не понравиться две последовательные кавычки). Хвост мы, конечно, отрезаем комментарием (#).
Вот как в итоге будет выглядеть запрос на SQL:
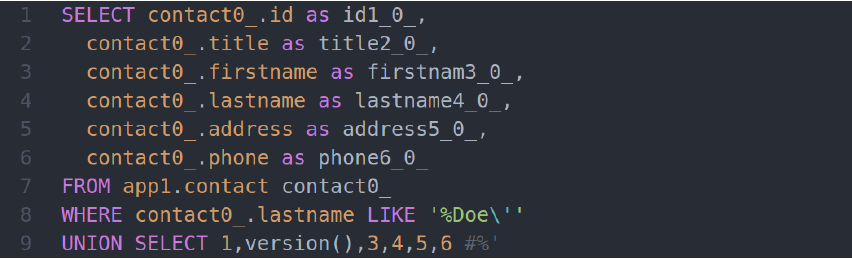
Магия сработала, мы превратили HQL-инъекцию в классическую SQL. Спасибо за внимание и успешных познаний нового!


