Не так давно мы уже расказывали о бесплатных инструментах для проведения ддос атак. Сегодня мы познакомимся с еще одним методом — Hash Collision DoS. Сразу скажу, что сама тема эта достаточно обширная и захватывающая множество различных аспектов, так что начнем мы с общей теории на пальцах.
Итак, hash — это результат работы некой хеш-функции (она же функция свертки), которая есть не что иное, как «преобразование по детерминированному алгоритму входного массива данных произвольной длины в выходную битовую строку фиксированной длины» (Wiki). То есть даем на вход, например, строку любой длины, а получаем на выходе — определенной (в соответствии с разрядностью). При этом для одной и той же строки на входе мы получаем одинаковый итог. Эта штука нам всем достаточно знакома: это и MD5, и SHA-1, и различные контрольные суммы (CRC).
Коллизиями же называется ситуация, когда различные входные данные имеют одинаковое хеш-значение после работы функции. Причем важно понимать, что коллизии свойственны всем хеш-функциям, так как количество итоговых значений по определению меньше (оно «ограничено» разрядностью) «бесконечного» числа входных значений.
Другой вопрос — как получать такие входные значения, которые приводили бы к коллизиям. Для криптостойких хеш-функций (таких как MD5, SHA-1) в теории нам поможет только прямой перебор возможных входных значений. Но такие функции очень медленны. Некриптостойкие хеш-функции часто позволяют рассчитывать входные значения, порождающие коллизии (подробнее — через несколько абзацев).
Теоретически именно возможность преднамеренной генерации коллизий и выступает основанием для выполнения атаки «отказ в обслуживании» (DDoS). Фактические методы же будут отличаться, и в качестве основы мы возьмем веб-технологии.
Большинство современных языков программирования (PHP, Python, ASP.NET, JAVA ), как ни странно, достаточно часто используют «внутри себя» именно некриптостойкие хеш-функции. Причина этого, конечно, в очень высокой скорости последних. Одно из типовых мест применения — ассоциативные массивы, они же хеш-таблицы. Да-да, те самые — хранение данных в формате «ключ — значение». И насколько я знаю, как раз от ключа и высчитывается хеш, который впоследствии будет индексом.
Но самое важное заключается в том, что при добавлении нового, поиске и удалении элемента из хеш-таблицы без коллизий каждое из действий происходит достаточно быстро (считается как O(1)). А вот при присутствии коллизий происходит целый ряд дополнительных операций: построчные сравнения всех ключевых значений в коллизии, перестройка таблиц. Производительность значительно-значительно снижается (O(n)).
И если мы теперь вспомним, что мы можем рассчитать произвольное количество ключей (n), каждое из которых будет приводить к коллизии, то теоретически добавление n элементов (ключ — значение) потребует затрат O(n^2), что может привести нас к долгожданному DoS’у.
Практически же для организации повышенной нагрузки на систему нам требуется возможность создать ассоциативный массив, у которого количество ключей с одинаковыми хешами будет измеряться сотнями тысяч (а то и больше). Представь себе нагрузку на проц, когда ему в такой гигантский список требуется вставить еще и еще одно значение и каждый раз проводить построчное сравнение ключей… Жесть-жесть. Но возникает два вопроса: как же добыть столь большое количество коллидирующих ключей? И как нам заставить атакуемую систему создавать такого размера ассоциативные массивы?
[ad name=»Responbl»]
Как было уже сказано, по первому вопросу мы их можем рассчитать. Большинство языков используют одну из вариаций одной и той же хеш-функции. Для PHP5 это DJBX33A (от Daniel J. Bernstein, X33 — умножить на 33, A — addition, то есть прибавить).
Далее представлен упрощенный ее код:
static inline ulong zend_inline_hash_func(const char *arKey, uint nKeyLength)
{
register ulong hash = 5381;
for (uint i = 0; i < nKeyLength; ++i) {
hash = hash * 33 + arKey[i];
}
return hash;
}
Как видишь, она очень простая. Берем значение хеша, умножаем его на 33 и прибавляем значение символа ключа. И это повторяется для каждого символа ключа.
В Java используется почти аналогичная штука. Разница лишь в начальном значении хеша, равном 0, и в том, что умножение происходит на 31 вместо 33. Или еще один вариант — в ASP.NET и PHP4 — DJBX33X. Это все та же функция, только вместо сложения со значением символа ключа используется функция XOR (отсюда и X на конце).
При этом у хеш-функции DJBX33A есть одно свойство, которое происходит из ее алгоритма и очень нам помогает. Если после хеш-функции строка1 и строка2 имеют один хеш (коллизия), то и результат хеш-функции, где эти строки являются подстроками, но находятся на одинаковых позициях, будет коллидировать. То есть:
hash(Строка1)=hash(Строка2) hash(xxxСтрока1zzz)=hash(xxxСтрока2zzz)
Например, из строк Ez и FY, которые имеют один хеш, мы можем получить EzEz, EzFY, FYEz, FYFY, чьи хеши также являются коллидирующими.
Таким образом, как ты видишь, мы можем быстро и легко рассчитать любое количество значений с одним значением хеш-функции DJBX33A. Подробнее про генерацию можно прочитать здесь.
Стоит отметить, что для DJBX33X (то есть с XOR’ом) данный принцип не работает, что и логично, но для него действует другой подход, который также позволяет нагенерить множество коллизий, хотя и требует больших затрат из-за брута в небольшом количестве. Кстати, практических реализаций тулз DoS’илок под данный алгоритм я не нашел.
С этим, надеюсь, все стало ясно. Теперь второй вопрос — про то, как заставить приложения создавать такие большие ассоциативные массивы.
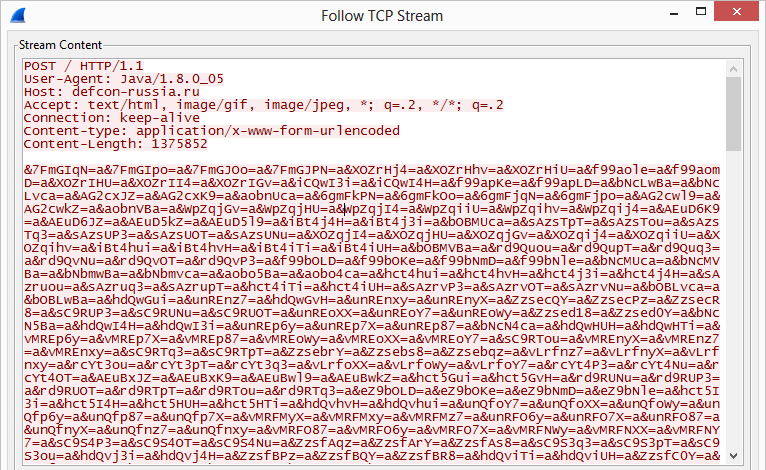
На самом деле все просто: надо найти такое место в приложении, где бы оно автоматически генерило такие массивы на наши входные данные. Самый универсальный способ — это отправка POST-запроса на веб-сервер. Большинство «языков» автоматически складывают в ассоциативный массив все входные параметры из запроса. Да-да, как раз переменная $_POST в PHP и дает к нему доступ. Кстати, хотелось бы подчеркнуть, что в общем случае нам все равно, используется ли сама эта переменная (для доступа к POST-параметрам) в скрипте/приложении (исключение вроде как составляет ASP.NET), так как важно то, что веб-сервер передал параметры в обработчик конкретного языка и там они автоматически добавились в ассоциативный массив.
Теперь немного цифр, чтобы подтвердить тебе, что атака очень сурова. Они от 2011 года, но суть сильно не поменялась. На процессоре Intel i7 в PHP5 500 Кб коллизий займут проц на 60 с, на Tomcat’е 2 Мб — 40 мин, для Python’а 1 Мб — 7 мин.

Конечно, здесь важно отметить, что почти все веб-технологии имеют ограничения на исполнение скрипта или запроса, на размер запроса, что несколько затрудняет атаку. Но примерно можно сказать, что поток запросов к серверу с заполнением канала до 1 Мбит/с позволит подвесить почти любой сервер. Согласись — очень мощно и при этом просто!
Вообще, уязвимости, связанные с коллизиями в хеш-функциях, и их эксплуатация всплывали с начала 2000-х для различных языков, но по вебу это сильно «ударило» как раз в 2011 году, после публикации практического ресерча от компании n.runs. Вендоры уже повыпускали различные патчи, хотя надо сказать, что «пробиваемость» атаки до сих пор высока.
Мне бы хотелось как раз обратить внимание на то, как вендоры пытались защититься и почему этого иногда недостаточно. Фактически есть два основных подхода. Первый — внедрить защиту на уровне языка. «Защита» заключается в изменении функции хеширования, точнее, в нее добавляется рандомная составляющая, не зная которую мы просто не можем создавать такие ключи, чтобы порождали коллизии. Но на это пошли не все вендоры. Так, насколько мне известно, Oracle забила на исправление в Java 1.6 и внедрила рандомизацию только с середины 7-й ветки. Microsoft внедрила исправление в ASP.NET c версии 4.5. Второй же подход (который также использовался в качестве workaround’а) был в ограничении количества параметров в запросе. В ASP.NET это 1000, в Tomcat — 10 000. Да, с такими значениями каши уже не сваришь, но достаточна ли такая защита? Мне, конечно, кажется, что нет, — у нас остается возможность подпихнуть в какое-то другое место наши данные с коллизиями, которые также будут автоматически обработаны системой. Один из ярких примеров такого места — различные XML-парсеры. В Xerces-парсере под Java ассоциативные массивы (HashMap) по полной используются при парсинге. И при этом парсер должен сначала все обработать (то есть запихнуть структуру в память), а потом уже производить различную бизнес-логику. Таким образом, мы можем сгенерить обычный запрос XML, содержащий коллизии, и отправить его на сервер. Так как параметр будет фактически один, то и защита на подсчет количества параметров будет пройдена.
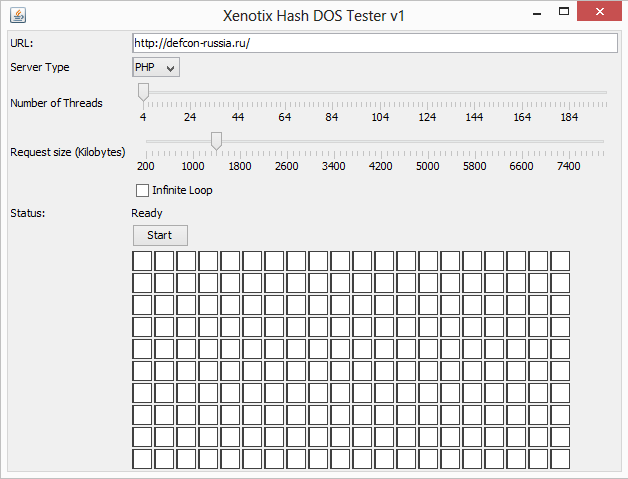
Но вернемся к простой POST-версии. Если ты хочешь потестить свой сайт или чей-то еще, то естьминималистичная тулза для этого или модуль Metasploit — auxiliary/dos/http/hashcollision_dos. Ну а на случай, если после моего объяснения остались вопросы или просто любишь кошечек, то вот версия в картинках.