Kubernetes — отличная платформа для оркестровки контейнеров и всего остального. В последнее время Kubernetes прошел большой путь как с точки зрения функциональности, так и с точки зрения безопасности и отказоустойчивости. Архитектура Kubernetes позволяет легко пережить различные типы сбоев и всегда оставаться на плаву.
Сегодня мы сломаем кластер, удалим сертификаты, повторно подключим узлы вживую, и все это, если возможно, без простоев для уже работающих служб.
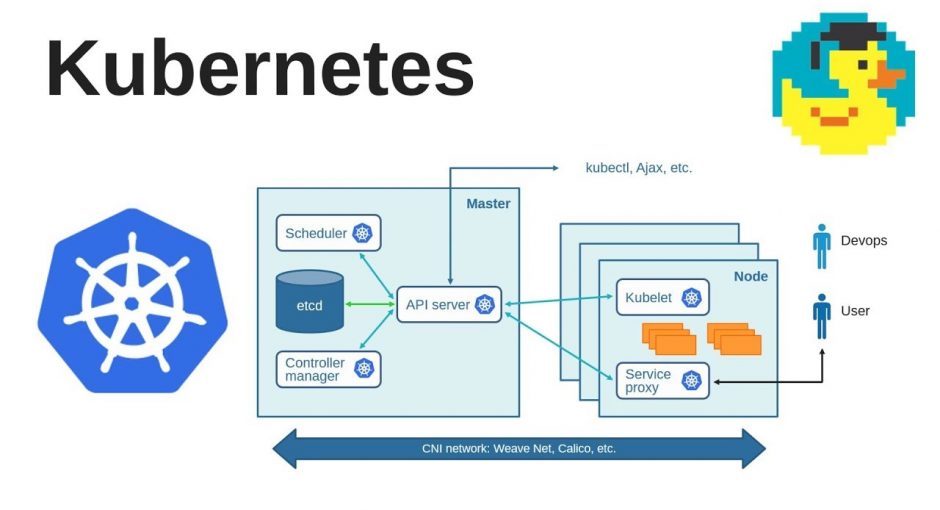
Итак приступим. Основной control-plane Kubernetes состоит всего из нескольких компонентов:
-
etcd — используется в качестве базы данных
-
kube-apiserver — API и сердце нашего кластера
-
kube-controller-manager — производит операции над Kubernetes-ресурсами
-
kube-scheduler — основной шедуллер
-
kubelet’ы — которые непосредственно и запускают контейнеры на хостах
Каждый из этих компонентов защищён набором TLS-сертификатов, клиентских и серверных, которые используются для аутентификации и авторизации компонентов между собой. Они не хранятся где-либо в базе данных Kubernetes, за исключением определенных случаев, а представлены в виде обычных файлов:
/etc/kubernetes/pki/ ├── apiserver.crt ├── apiserver-etcd-client.crt ├── apiserver-etcd-client.key ├── apiserver.key ├── apiserver-kubelet-client.crt ├── apiserver-kubelet-client.key ├── ca.crt ├── ca.key ├── CTNCA.pem ├── etcd │ ├── ca.crt │ ├── ca.key │ ├── healthcheck-client.crt │ ├── healthcheck-client.key │ ├── peer.crt │ ├── peer.key │ ├── server.crt │ └── server.key ├── front-proxy-ca.crt ├── front-proxy-ca.key ├── front-proxy-client.crt ├── front-proxy-client.key ├── sa.key └── sa.pub
Сами компоненты описаны и запускаются на мастерах как static pods из директории /etc/kubernetes/manifests/
Мы не будем здесь вдаваться в подробности, это тема для отдельной статьи. В данном случае нас в первую очередь интересует, как из всего этого сделать рабочий кластер. Но давайте сначала немного абстрагируемся и представим, что у нас есть упомянутые выше компоненты Kubernetes, которые каким-то образом взаимодействуют друг с другом.
Основная схема выглядит примерно так:
")
(стрелочки указывают на связи клиент —> сервер)
Для связи им нужны сертификаты TLS, которые, в принципе, можно вывести на отдельный уровень абстракции и полностью доверять вашему инструменту распространения, будь то kubeadm, kubespray или что-то еще. В этой статье мы рассмотрим kubeadm, потому что это наиболее распространенный инструмент развертывания Kubernetes, который часто используется как часть других решений.
Допустим, у нас уже есть задеплоенный кластер. Начнём с самого интересного:
rm -rf /etc/kubernetes/На мастерах данная директория содержит:
-
Набор сертификатов и CA для etcd (в
/etc/kubernetes/pki/etcd) -
Набор сертификатов и CA для Kubernetes (в
/etc/kubernetes/pki) -
Kubeconfig для cluster-admin, kube-controller-manager, kube-scheduler и kubelet (каждый из них также имеет закодированный в base64 CA-сертификат для нашего кластера
/etc/kubernetes/*.conf) -
Набор статик-манифестов для etcd, kube-apiserver, kube-scheduler и kube-controller-manager (в
/etc/kubernetes/manifests)
Предположим, что мы потеряли всё и сразу
Чиним control-plane
Чтобы не было недоразумений, давайте также убедимся что все наши control-plane поды также остановлены:
crictl rm `crictl ps -aq`Примечание: kubeadm по умолчанию не перезаписывает уже существующие сертификаты и кубеконфиги, для того чтобы их перевыпустить их необходимо сначала удалить вручную.
Давайте начнём с восстановления etcd, так как если у нас был кворум (3 и более мастер-нод) etcd-кластер не запустится без присутствия большинства из них.
kubeadm init phase certs etcd-caКоманда выше сгенерит новый CA для нашего etcd-кластера. Так как все остальные сертификаты должны быть им подписаны, скопируем его вместе с приватным ключом на остальные мастер-ноды:
/etc/kubernetes/pki/etcd/ca.{key,crt}Теперь перегенерим остальные etcd-сертификаты и static-манифесты для него на всех control-plane нодах:
kubeadm init phase certs etcd-healthcheck-client
kubeadm init phase certs etcd-peer
kubeadm init phase certs etcd-server
kubeadm init phase etcd localНа этом этапе у нас уже должен подняться работоспособный etcd-кластер:
# crictl ps
CONTAINER ID IMAGE CREATED STATE NAME ATTEMPT POD ID
ac82b4ed5d83a 0369cf4303ffd 2 seconds ago Running etcd 0 bc8b4d568751bТеперь давайте проделаем тоже самое, но для для Kubernetes, на одной из master-нод выполним:
kubeadm init phase certs all
kubeadm init phase kubeconfig all
kubeadm init phase control-plane all
cp -f /etc/kubernetes/admin.conf ~/.kube/configВышеописанные команды сгенерируют все SSL-сертификаты для нашего Kubernetes-кластера, а также статик под манифесты и кубеконфиги для сервисов Kubernetes.
Если вы используете kubeadm для джойна кубелетов, вам также потребуется обновить конфиг cluster-info в kube-public неймспейсе т.к. он до сих пор содержит хэш вашего старого CA.
kubeadm init phase bootstrap-tokenТак как все сертификаты на других инстансах также должны быть подписаны одним CA, скопируем его на остальные control-plane ноды, и повторим вышеописанные команды на каждой из них.
/etc/kubernetes/pki/{ca,front-proxy-ca}.{key,crt}
/etc/kubernetes/pki/sa.{key,pub}Кстати, в качестве альтернативы ручного копирования сертификатов теперь вы можете использовать интерфейс Kubernetes, например следующая команда:
kubeadm init phase upload-certs --upload-certsЗашифрует и загрузит сертификаты в Kubernetes на 2 часа, таким образом вы сможете сделать реджойн мастеров следующим образом:
kubeadm join phase control-plane-prepare all kubernetes-apiserver:6443 --control-plane --token cs0etm.ua7fbmwuf1jz946l --discovery-token-ca-cert-hash sha256:555f6ececd4721fed0269d27a5c7f1c6d7ef4614157a18e56ed9a1fd031a3ab8 --certificate-key 385655ee0ab98d2441ba8038b4e8d03184df1806733eac131511891d1096be73
kubeadm join phase control-plane-join allСтоит заметить, что в API Kubernetes есть ещё один конфиг, который хранит CA сертификат для front-proxy client, он используется для аутентификации запросов от apiserver в вебхуках и прочих aggregation layer сервисах. К счастью kube-apiserver обновляет его автоматически.
Однако возможно вы захотите почистить его от старых сертификатов вручную:
kubectl get cm -n kube-system extension-apiserver-authentication -o yamlВ любом случае на данном этапе мы уже имеем полностью рабочий control-plane.
Чиним воркеры
Эта команда выведет список всех нод кластера, хотя сейчас все они будут в статусе NotReady:
kubectl get nodeЭто потому что они по прежнему используют старые сертификаты и с ожидают запросов apiserver, подписаных старым CA. Для того чтобы это исправить мы воспользуемся kubeadm, и сделаем реджойн нод в кластер.
Когда как мастера имеют доступ к CA и могут быть присоеденены локально:
systemctl stop kubelet
rm -rf /var/lib/kubelet/pki/ /etc/kubernetes/kubelet.conf
kubeadm init phase kubeconfig kubelet
kubeadm init phase kubelet-startТо для джойна воркеров мы сгенерируем новый токен:
kubeadm token create --print-join-commandи на каждом из них выполним:
systemctl stop kubelet
rm -rf /var/lib/kubelet/pki/ /etc/kubernetes/pki/ /etc/kubernetes/kubelet.conf
kubeadm join phase kubelet-start kubernetes-apiserver:6443 --token cs0etm.ua7fbmwuf1jz946l --discovery-token-ca-cert-hash sha256:555f6ececd4721fed0269d27a5c7f1c6d7ef4614157a18e56ed9a1fd031a3ab8Внимание, удалять директорию
/etc/kubernetes/pki/на мастерах не нужно, так как она уже содержит все необходимые сертификаты.
Вышеупомянутая процедура повторно подключит все ваши кублеты к кластеру, не затрагивая уже запущенные на них контейнеры. Однако, если у вас много узлов в кластере и вы делаете это одновременно, у вас может возникнуть ситуация, когда Controller-Manager начинает воссоздавать контейнеры с узлами NotReady и пытается запустить их на активных узлах кластера. .
Чтобы это предотвратить мы можем временно остановить controller-manager, на мастерах:
rm /etc/kubernetes/manifests/kube-controller-manager.yaml
crictl rmp `crictl ps --name kube-controller-manager -q`Последняя команда нужна просто для того, чтобы удостовериться что под с controller-manager действительно не запущен. Как только все ноды кластера будут присоединены мы можем сгенерировать static-manifest для controller-manager обратно.
Для этого на всех мастерах выполняем:
kubeadm init phase control-plane controller-managerУчтите что делать это нужно на этапе когда вы уже сгенерировали join token, в противном случае операция подключения зависнет на попытке прочитать токен из cluster-info.
В случае если kubelet настроен на получение сертификата подписанного вашим CA (опция serverTLSBootstrap: true), вам также потребуется заново подтвердить csr от ваших kubelet’ов:
kubectl get csr
kubectl certificate approve <csr>Чиним ServiceAccounts
Есть ещё один момент. Так как мы потеряли /etc/kubernetes/pki/sa.key — это тот самый ключ которым были подписаны jwt-токены для всех наших ServiceAccounts, то мы должны пересоздать токены для каждого из них.
Сделать это можно достаточно просто, удалив поле token изо всех секреты типа kubernetes.io/service-account-token:
kubectl get secret --all-namespaces | awk '/kubernetes.io\/service-account-token/ { print "kubectl patch secret -n " $1 " " $2 " -p {\\\"data\\\":{\\\"token\\\":null}}"}' | sh -xПосле чего kube-controller-manager автоматически сгенерирует новые токены, подписаные новым ключом.
К сожалению далеко не все микросервисы умеют на лету перечитывать токен и скорее всего вам потребуется вручную перезапустить контейнеры, где они используются:
kubectl get pod --field-selector 'spec.serviceAccountName!=default' --no-headers --all-namespaces | awk '{print "kubectl delete pod -n " $1 " " $2 " --wait=false --grace-period=0"}'Например, эта команда сгенерирует список команд для удаления всех модулей с использованием нестандартного serviceAccount. Я рекомендую начать с пространства имен kube system. Там установлены kube-proxy и подключаемый модуль CNI, которые жизненно важны для настройки взаимодействия ваших микросервисов.
На этом восстановление кластера можно считать завершенным. Спасибо за внимание! В следующей статье мы более подробно рассмотрим резервное копирование и восстановление кластера etcd.



