Nmap — культовый сканер, без которого не может обойтись практически ни один хакер, поэтому тема расширения его возможностей, я думаю, интересует многих. Использовать в паре с Nmap другие инструменты — обычная практика. В статье речь пойдет о том, как легко автоматизировать работу Nmap со своими любимыми инструментами. Удобнее же «нажать одну кнопку» и получить результат, чем постоянно проделывать одну и ту же последовательность действий. Использование скриптов в Nmap может помочь хакерам более автоматизированно взламывать системы, а сисадминам проверять системы на наличие дефолтных дыр и своевременно их устранять.

Пару слов про Nmap
Мы уверены, что большинство читателей нашего сайта знают, что такое Nmap, и наверняка не раз использовали его для исследования сети и сбора информaции. Для тех же, кто подзабыл или не знает, на всякий случай напомню:
- Nmap — кросс-платформенный инструмент для сканирования сети, проверки ее безопасности, определения версий ОС и различных сервисов и многого другого. Это очень гибкая и легко расширяемая утилита, а делает ее такой скриптовый движок NSE;
- NSE (Nmap Scripting Engine) — компонент Nmap, обладающий мощными возможностями, что позволяет пользователям писать скрипты для автоматизации широкого круга сетевых задач: более гибкого взаимодействия с имеющимися возможностями Nmap, обнаружения и эксплуатации уязвимостей и прочего. В основе NSE — интерпретатор языка Lua;
- Lua — скриптовый язык, похожий на JavaScript.
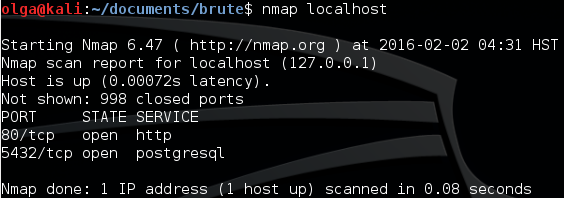
Рис. 1. Вывод таблицы Nmap
Постановка задачи
Как уже было сказано, сегодня мы будем заниматься расширением функционала Nmap за счет написания собственных скриптов. Любой взлом/пентест обычно начинается с разведки и сбора данных. Одним из первых проверяется наличие на исследуемом хосте открытых портов и идентификация работающих сервисов. Лучшего инструмента для сбoра такой информации, чем Nmap, пожалуй, нет. Следующим шагом после сканирования обычно бывает либо поиск сплоита под найденный уязвимый сервис, либо подбор пары логин:пароль с помощью метода грубой силы.
Допустим, ты активно используешь брутфорсер THC-Hydra для подбора паролей нескольких сервисов (например, HTTP-Basic, SSH, MySQL). В таком случае приходится натравливать гидру на каждый сервис отдельно, нужно запоминать особенности сервисов и необходимые для запуска гидры флаги. А если появится необходимость брутить намного больше, чем пять сервисов?.. Почему бы не автоматизировать это?
Поэтому давай напишем простенький скрипт, который будет автоматизировать процесс запуска Hydra для подбора логинов/паролей к одному сервису (например, PostgreSQL). Для этого нам понадобятся следующие инструменты:
- Nmap;
- THC-Hydra;
- любой текстовый редактор.
Если у тебя еще не установлен Nmap и/или Hydra, немедленно исправь это:
$ sudo apt-get install nmap hydra
О’кeй, начнем. Скрипты для Nmap представляют собой обычные текстовые файлы с расширением *.nse. Поэтому открывай свой любимый текстовый редактор и создавай новый файл. Я буду использовать Vim:
$ vim hydra.nse
Перед тем как перейти к написанию, надо сказать, что все скрипты имеют определенную структуру. Помимо самого кода, автоматизирующего те или иные действия, в нем присутcтвует описание скрипта (для чего предназначен и как использовать), информация об авторе, лицензии, зависимость от других скриптов, категории, к которым относится скрипт, и так далее. Давай подробней рассмотрим каждую из этих частей.
Описание скрипта (description)
Данный раздел содержит описание скрипта, комментарии автора, пример отображения результата выполнения скрипта на экран, дополнительные возможности.
[ad name=»Responbl»]
Для нашего скрипта, подбирающего логины/пароли к PostgeSQL, описание будет выглядеть следующим образом:
description = [[ Brute force all services running on a target host. The results are returned in a table with each path, detected method, login and/or password. ]] --- -- @usage -- nmap --script hydra [--script-args "lpath=<file_logins>, ppath=<file_passwords>"] <target_ip> -- -- @output -- PORT STATE SERVICE -- 80/tcp open http -- | hydra: -- | path method login password -- | 127.0.0.1/private/index.html Digest log pass -- |_ 127.0.0.1/simple/index.txt Basic user qwerty -- -- @args hydra.lpath: the path to the file with logins. For example, -- nmap --script hydra --script-args="lpath=/home/my_logins.txt" <target_ip> -- @args hydra.ppath: the path to the file with passwords. For example, -- nmap --script hydra --script-args="ppath=/home/my_pass.txt" <target_ip>
Здесь
-- — комментарий; --[[ ]] — многострочный комментарий; @usage, @output, @args — пример вызова скрипта, вывода результата на экран, необходимые аргументы при вызове.
Выше в @usage мы видим формат запуска скрипта. В данном случае указано только имя скрипта (hydra). Это становится возможным, если скрипт положить в директорию /<path to nmap>/nmap/scripts/, в противном случае придется указывать абсолютный или относительный путь до него. В последующем сделаем возможным задание аргументов при запуске скрипта. Аргументы задаются с помощью флага --script-args "<some arguments>". В нашем случае мы будем задавать путь до файла с логинами (lpath) и до файла с паролями (ppath). Аргументы необязательны: по умолчанию будем искать файлы с именами login.txt и password.txt в текущей директории.
Категории, в которых находится скрипт (categories)
При написании NSE-скрипта можно указать его категорию (или несколько категорий). Это бывает полезно, когда пользователь Nmap хочет использовать не конкретный скрипт, а набор скриптов, находящихся в одной категории. Примеры некоторых категорий:
- auth — категория, в которой скрипты определяют аутентификационные данные целевого хоста;
- brute — категория, скрипты которой помогают определить логины и пароли для различных сервисов;
- default — категория, которая содержит основные скрипты. Есть некоторые критерии, определяющие принадлежность скрипта к данной категории: скорость сканирования, полезность, надежность, конфиденциальность, наглядный вывод;
- malware — категория, помогающая определять вредоносные программы.
Например, если необходимо запустить все скрипты из категории auth, то команда будет выглядеть следующим образом:
$ nmap --script=auth example.com
В таком случае скрипты этой категории будут по очереди запускаться для указанного хоста. Наш скрипт относится к категории brute. Добавим следующую строку в файл:
categories = {"brute"}
Каждый скрипт содержит информацию об его авторе. В моем случае:
author = "Olga Barinova"
Информация об использующейся лицензии (license)
Nmap приветствует все разработки пользователей и призывает делиться ими, в том числе NSE-скриптами. При указании лицензии ты подтверждаешь право делиться скриптом с сообществом. Стандартная лицензия Nmap выглядит следующим образом:
license = "Same as Nmap--See http://nmap.org/book/man-legal.html"
Добавим также и эту строку в наш скрипт.
Зависимости от других скриптов (dependencies)
Эта область содержит названия NSE-скриптов, которые должны быть выполнены перед началом работы данного скрипта для получения необходимой информации. Например,
dependencies = {"smb-brute"}.
В нашем случае такая возможность не понадобится, поэтому добавлять dependencies мы не будем.
Хост и порт (host & port)
Nmap должен знать, для каких сервисов и на каких портах запускать скрипт. Для этого есть специальные правила:
prerule()— скрипт выполняется один раз перед сканированием любого хоста, используется для некоторых операций с сетью;hostrule(host)— скрипт выполняется для каждого хоста из таблицы, которую принимает в качестве аргумента;portrule(host, port)— скрипт выполняется для каждого хоста и для каждого порта из таблиц, которые принимает в качестве аргументов;postrule()— скрипт выполняется один раз после сканирования любого хоста. В основном используется для обработки полученных результатов, подведения статистики и подобного.
Для формирования таких правил есть библиотеки. В нашем скрипте необходимо только указать номер порта (5432) и имя сервиса (postgresql), и тогда он будет работать лишь для данного порта и сервиса. Существует довольно популярная библиотека shortport, встроенная в NSE, в которую включены различные методы. Мы будем использовать метод
port_or_service (ports, services, protos, states)
где ports — номера портов, services — имена сервисов, protos — имена протоколов (например, udp), states — состояния.
[ad name=»Responbl»]
Этот метод возвращает true в том случае, если в данный момент анализируется сервис, находящийся на одном из портов из списка ports или соответствующий какому-нибудь сервису из списка services, кроме того, проверяется протокол и состояние на соответствие, иначе возвращается false.
Чтобы наш скрипт работал с PostgreSQL, нужно добавить номер порта и название сервиса:
portrule = shortport.port_or_service({5432}, {"postgresql"})
Подключение библиотек
Отвлечемся на секунду от структуры скрипта и рассмотрим, как происходит подключение внешних библиотек, к функциональности которых нам потребуется обращаться.
Как и в любом языке, для того чтобы использовать переменные, нужно их сначала объявить и проинициализировать. В Lua все просто: все переменные объявляются через local:
local <имя_переменной>
Но прежде всего нам необходимо подключить библиотеки. В Lua такая возможность реализуется с помощью ключевого слова require. Добавим в самое начало нашего скрипта:
local nmap = require "nmap" local shortport = require "shortport" local stdnse = require "stdnse" local string = require "string" local table = require "table" local tab = require "tab"
Таким образом мы подключили следующие библиотеки:
nmap— библиотека NSE, содержит внешние функции и структуры данных Nmap;shortport— библиотека NSE, содержит функции для указания сервисов, портов и так далее, для которых будет запускаться скрипт;stdnse— библиотека NSE, содержит стандартные NSE-функции;string— библиотека Lua, содержит функции для работы со строками;table— библиотека Lua для создания и модификации таблиц (ассоциативных массивов);tab— библиотека NSE для работы с таблицей Nmap для вывода результата.
Nmap Libs
Подробнее про библиотеки можно почитать тут в разделе Libraries.
Обращаясь к этим глобальным переменным, мы будем иметь доступ к функциональности библиотек.
Инструкции скрипта (action)
Вот мы и добрались до самого главного. В блоке action описываются действия, которые необходимо выполнить. Как ты помнишь, мы хотим запустить гидру, посмотреть на результат ее выполнения, вытащить нужную информацию из результата, обработать ее и вывести в таблицу Nmap.
Структура action-блока выглядит следующим образом:
action = function (host, port)
<тело блока: все инструкции, которые будут выполнены скриптом>
end
Прежде всего объявим все необходимые переменные внутри action-блока:
local str -- будем формировать строку для запуска гидры local s -- вспомогательная переменная для хранения результата работы гидры local login = '' -- сюда запишем найденный логин local pass = '' -- сюда запишем найденный пароль local task = '' -- будет содержать количество потоков для работы гидры local serv = port.service -- в переменной serv будем хранить название сервиса, которое обрабатывает скрипт во время его работы (в нашем случае будет значение postgresql)
Названия некоторых сервисов не совпадают для Nmap и для гидры, как, например, в нашей ситуации. Nmap хранит значение postgresql, а Hydra как один из флагов принимает значение postgres. Поэтому нам придется корректировать это значение, используя условие:
if <условное выражение> then if (serv == "postgresql") then
<тело> serv = "postgres"
<...> task = "-t 4"
end end
Заодно мы указали количество потоков для распараллеливания для этого сервиса (переменная task).
Теперь создадим таблицу, в которую будем складывать результаты брутфорса (логины и пароли), и добавим в нее значения первой строки (названия столбцов):
local restab = tab.new(4) -- c четырьмя столбцами: path, method, login, password tab.addrow(restab, "path", "method", "login", "password")
В первой строке таблицы мы указали имена столбцов. На следующем шаге проверим, открыт ли порт, и сформируем строку с нужными флагами для запуска гидры:
if (port.state == "open") then
str = "hydra -L login.txt -P password.txt " .. task .. " -e ns -s " .. port.number .. " " .. host.ip .. " " .. serv
… … … -- сюда необходимо добавить команды, которые будут описаны ниже
end
Флаги при запуске гидры:
-L (-l) <файл_с_логинами> (<один_логин>) -P (-p) <файл_с_паролями> (<один_пароль>) -t <количество_потоков> (по дефолту 16) -e ns — дополнительная проверка: n — проверка на пустой пароль, s — в качестве пароля проверяется логин -s <номер_порта>
В конце сформированной строки указывается IP (или диапазон) и название сервиса.
Флаги Hydra
Подробнее о флагах и использовании THC-Hydra можно почитать здесь.
Также стоит заметить, что .. (двоеточие) используется в Lua для конкатенации строк. Далее нужно выполнить команду, сформированную в str. Для этого будем использовать io.popen(str). Команда запускает программу str в отдельном процессе и возвращает обработчик файла (handler), который мы можем использовать для чтения данных из этой программы или для записи данных в нее.
local handler = io.popen(str)
s = handler:read('*a') -- '*a' означает считывание всех данных
handler:close()
В переменной s лежит результат работы гидры (показан на рис. 2).
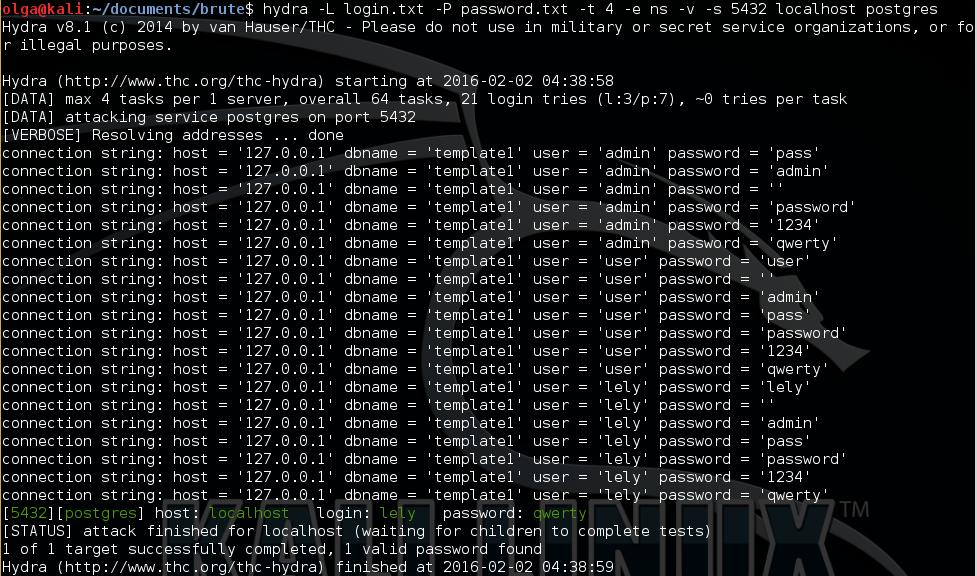
Рис. 2. Вывод результата работы Hydra на экран
Мы хотим понять, получилось ли сбрутить какую-нибудь пару login:password, для этого нам поможет regex. В библиотеке string есть метод match, который сравнит нашу строку и регулярное выражение и в переменные loginи password положит соответствующие значения, если они есть.
local login, pass = string.match(s, 'login:%s([^%s]*)%s+password:%s([^%s]*)')
Значения, попадающие в ([^%s]*), присваиваются переменным в порядке их следования (%s — пробел). Добавим найденные логин и пароль в таблицу, предварительно проверив на их наличие:
if (login) and (pass) then
tab.addrow(restab, host.ip .. "/", serv, login, pass)
end
На этом заканчиваем обработку сервиса и закрываем цикл ( if (port.state == "open") then … end ). Наконец, проверяем таблицу. Если в нее были добавлены новые строки, кроме первой с заголовками, выводим значения в таблицу Nmap.
if ( #restab > 1 ) then
local result = { tab.dump(restab) }
return stdnse.format_output(true, result)
end
Если объект представляет собой таблицу, то Lua использует операцию # взятия длины таблицы. Другие варианты использования # можно найти в документации. Сейчас нам осталось только закрыть action-блок (поставить недостающий end).
Lua Docs
Желающие поближе познакомиться с Lua могут пройти по этой ссылке.
Сохраняем скрипт в директорию /<path to nmap>/nmap/scripts/. Теперь его можно запустить и посмотреть на результат. Но перед этим установим, настроим и добавим пользователя PostgreSQL.
Настройка PostgreSQL
- Установка и запуск. PostgreSQL должен быть в репозиториях (если нет — качаем и устанавливаем по инструкциям):
$ sudo apt-get install postgresql- Проверим состояние сервиса:
$ sudo service postgresql status - Если сервис не запущен:
$ sudo service postgresql start
- Добавим Linux-пользователя. Пусть у нас будет postgresql:qwerty. Последовательность действий:
$ sudo su$ adduser postgresql(попросит ввод пароля, вводим qwerty)$ exit
- Далее подключимся к базе данных и добавим пользователя postgresql:
$ su - postgres $ psql template1 template1=# CREATE USER postgresql WITH PASSWORD ‘qwerty’; template1=# CREATE DATABASE test_db; template1=# GRANT ALL PRIVILEGES ON DATABASE test_db to postgresql; template1=# q
Теперь сервис запущен и настроен и мы добавили юзера с логином и паролем.
Запуск скрипта
Для начала добавим в файл login.txt наш логин postgresql и в файл password.txt — пароль qwerty:
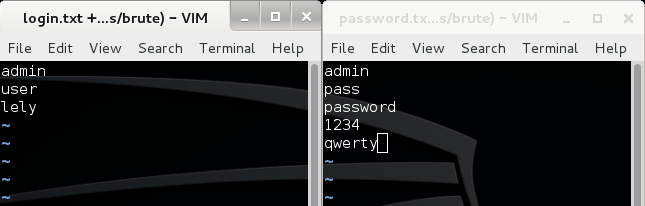
Рис. 3. Пример содержимого файлов с логинами и паролями
Теперь запустим скрипт:
$ nmap --script hydra localhost
В результате его работы мы получаем таблицу, представленную на рис. 4.
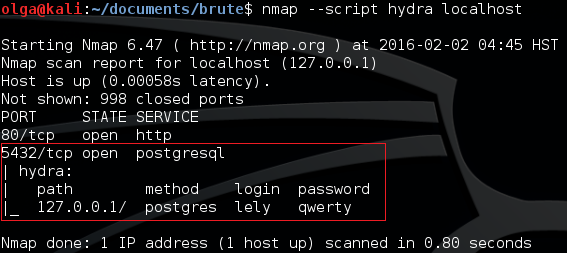
Рис. 4. Найденные логин и пароль внутри таблицы Nmap
Аргументы
В начале статьи я писала о том, что при данной реализации файл с логинами и файл с паролями должны лежать в текущей директории с именами login.txt и password.txt соответственно. Такой вариант может не всех устраивать, поэтому давай добавим скрипту входные параметры lpath (путь до файла с логинами) и ppath (путь до файла с паролями). То есть запуск скрипта будет выглядеть следующим образом:
$ nmap --script hydra --script-args "lpath=<path_to_file_with_logins>, ppath=<path_to_file_with_passwords>" localhost
Для этого понадобятся некоторые модификации. В начале action-блока, после объявления переменных зарегистрируем аргументы lpath и ppath следующим образом:
nmap.registry.args = {
lpath = "login.txt",
ppath = "password.txt"
}
local path_login = nmap.registry.args.lpath
local path_passwd = nmap.registry.args.ppath
При регистрации мы указали дефолтные значения. Кроме этого, строка для запуска гидры станет выглядеть следующим образом (вместо захардкоженных значений теперь используются переменные path_login иpath_password):
str = "hydra -L " .. path_login .." -P " .. path_password .. task .. " -e ns -s " .. port.number .. " " .. host.ip .. " " .. serv
Все готово, можно попробовать воспользоваться аргументами.
Расширение
Какую цель я ставила перед собой? Автоматизация работы Nmap и Hydra. Чем больше сервисов возможно брутить одним скриптом, тем лучше. Давай сделаем это. Теперь уже это очень просто. Добавим в portrule другие порты и сервисы:
portrule = shortport.port_or_service({5432, 3306, 21, 22}, {"postgresql", "mysql", "ftp", "ssh"})С такими изменениями скрипт будет прекрасно работать и для добавленных сервисов. Можно добавлять и другие сервисы, но для некоторых нужно немного дописывать скрипт. Эти изменения обычно незначительные и очевидные (например, уменьшить/увеличить количество потоков для распараллеливания).
Hydra.nse
С полной версией скрипта, поддерживающей расширенный список сервисов, ты можешь ознакомиться в моем репозитории на GitHub.
Отладка скриптов
После написания скрипта при его запуске могут возникнуть ошибки (например, синтаксиса или неправильного использования). В таких случаях Nmap предупреждает о невозможности выполнения скрипта и советует использовать флаг -d (см. рис. 5). Соответственно, запуск будет выглядеть примерно следующим образом:
$ nmap --script hydra localhost -dПри таком вызове Nmap сообщит о совершенных ошибках. Если же проблема не в синтаксисе, а в логике скрипта, то здесь поможет отладочный вывод (print).
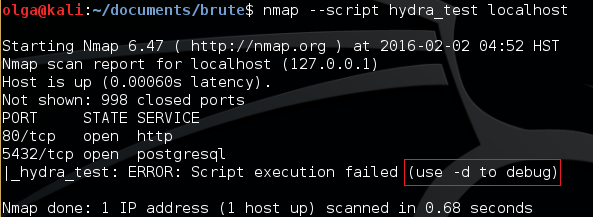
Рис. 5. Пример вывода ошибки
Заключение
NSE — отличный способ расширения возможностей Nmap. Надеюсь, кого-нибудь вдохновит моя статья и ты захочешь написать скрипт для своего любимого инструмента. В этом случае призываю делиться своими разработками.


2 comments On Практика использования сканера уязвимостей NMAP
Pingback: FAQ по SQL инъециям и веб уязвимостям. - Cryptoworld ()
Pingback: Сетевые утилиты для андроид. - Cryptoworld ()