В первой части мы начали создание парсера для web сайтов. Сегодня мы доведем начатое до конца.

JSON output
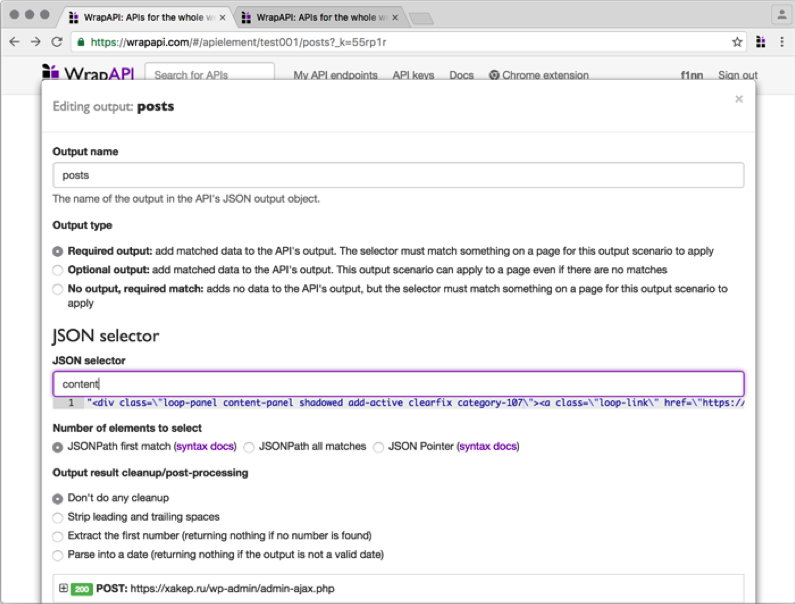
Первым делом нужно вытащить из объекта JSON значение атрибута content. Создавай новый output типа JSON и в появившемся модальном окне указывай имя параметра content. Сразу же под текстовым полем WrapAPI подсветит найденное значение выходной строки. То, что нам нужно. Сохраняем output и идем дальше.
CSS output
Следующий шаг — вытащить нужные нам поля постов из полученной с сервера верстки, а именно title, excerpt, image, date и id.
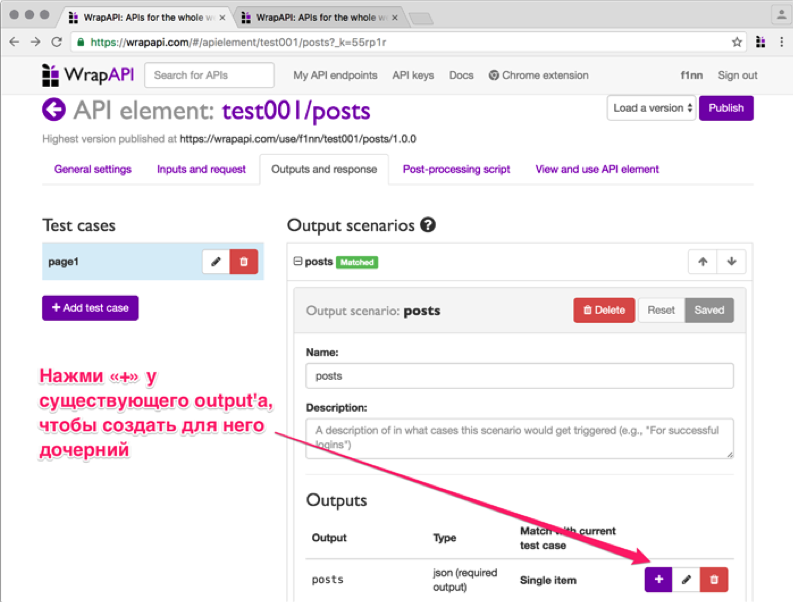
Во WrapAPI можно создавать дочерние аутпуты. Нажав на + около существующего output, ты создашь дочерний output, который будет принимать на выход значение предыдущего. Не перепутай! Если просто выбрать пункт Add new output, то будет создан новый root-селектор, который на вход получит голый ответ сервера.
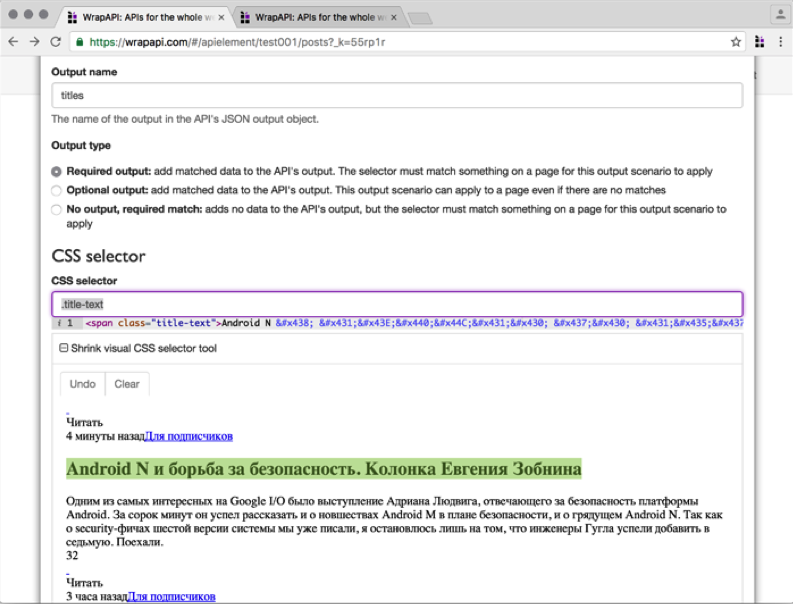
В появившемся окне вводим название класса заголовка .title-text. Внимание: обязательно отметь опцию Select all into an array, иначе будет выбран только первый заголовок, а нам нужно получить все десять по количеству постов в одном ответе сервера.
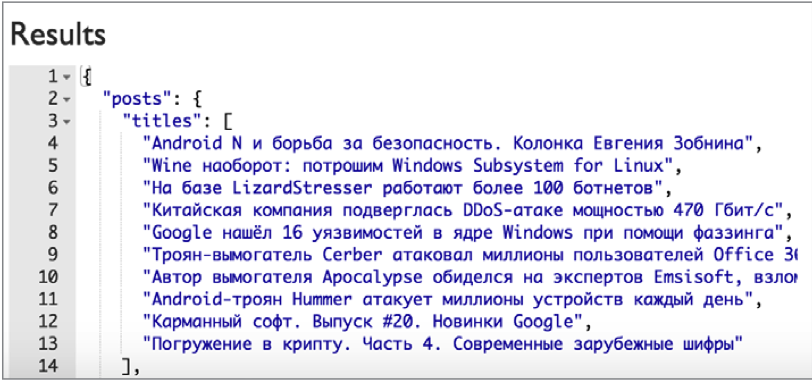
На выходе в ключе titles у нас окажется массив заголовков, которые вернул CSS output. Согласись, уже неплохо, и все это — без единой строки кода!
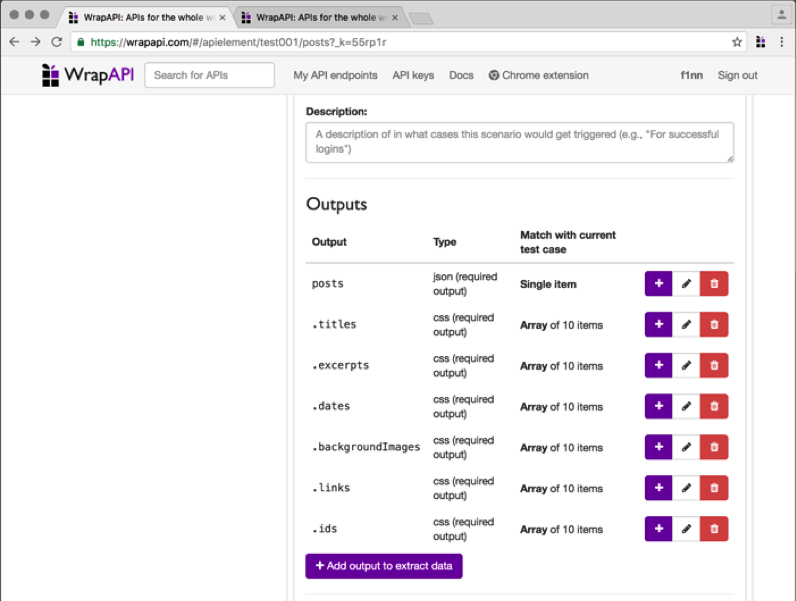
Как ты помнишь, кроме title, для каждого поста нам нужно получить еще excerpt, image, date и id. Тут все не так здорово: WrapAPI имеет два ограничения:
• он не позволяет создавать цепочки из более чем одного уровня вложенности дочерних outputs;
• он не позволяет задавать несколько селекторов для CSS output’a. То есть CSS output может вытащить только title, только date и так далее.
Признаться, мне пришлось немного поломать голову, чтобы обойти эти ограничения. Я сделал много дочерних по отношению к JSON аутпутов CSS — по одному на каждый из параметров. Они выводят мне в итоговый результат несколько массивов: один с заголовками, один с превью статьи, один с датами и так далее.
В итоге у меня получился вот такой массив данных:
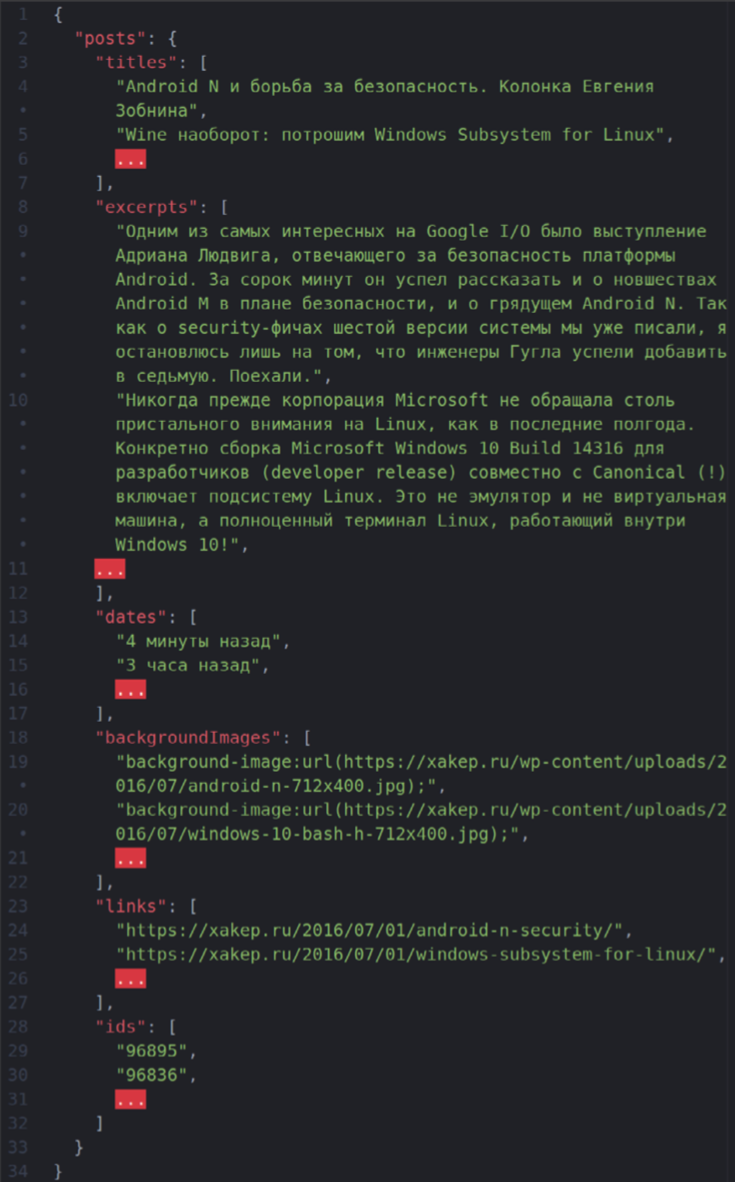
Стоит отметить, что для backgroundImages нужно указать получение не текста HTML-тега, а значения атрибута style, так как URL картинки задан в свойстве inline-CSS, а не в атрибуте src тега img.
ПРИВОДИМ ВСЕ В ПОРЯДОК
Сейчас наш API уже выглядит вполне читаемым, осталось решить две проблемы:
все компоненты поста — заголовок, дата, превью — находятся в разных массивах; в backgroundImages попал кусок CSS, а не чистый URL.
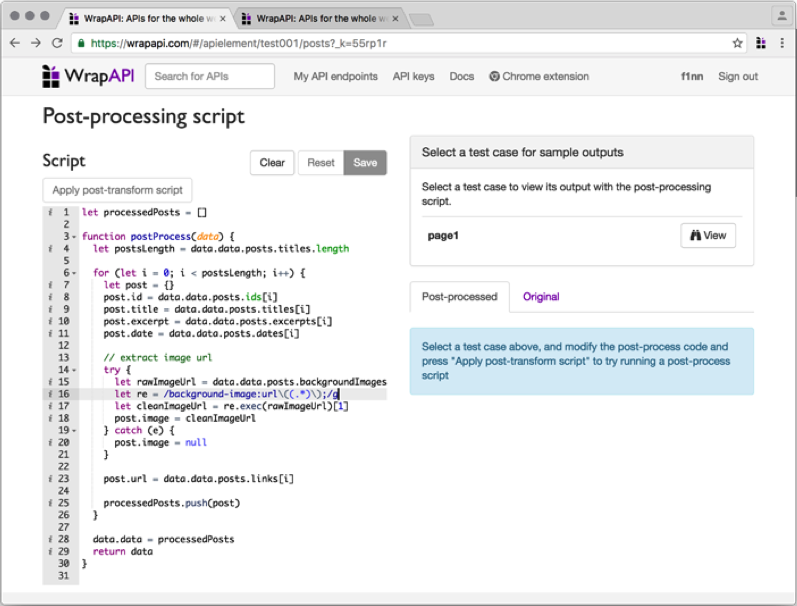
Решить эти проблемы нам поможет следующая вкладка — Post-processing script. Она позволяет написать небольшой синхронный скрипт на JavaScript, который может сделать что-то с нашим контентом перед тем, как он отправится на выход.
Скрипт должен содержать функцию postProcess(), которая принимает один аргумент — текущие результаты парсинга. То, что она вернет, и будет конечным ответом нашего API.
Я набросал небольшой скрипт, который быстро собрал все компоненты в единый массив постов, а также почистил URL картинки. Останавливаться на этом подробнее смысла нет, все, я думаю, и так предельно ясно.
 ТЕСТИРУЕМ РЕЗУЛЬТАТ
ТЕСТИРУЕМ РЕЗУЛЬТАТ
Переходим в очередную вкладку — View and use API element. Здесь нет ничего интересного, кроме стандартных вопросов перед публикацией. Скорее всего, менять ничего не придется, поэтому выбери версию API и публикуй. Мне выдали URL вида https://wrapapi.com/use/f1nn/test001/posts/1.0.0.
Перед тем как пробовать наш запрос, нужно получить API-ключ. Ключи WrapAPI бывают двух типов:
• приватные, для использования на сервере, не имеют ограничений;
• публичные, для использования на клиенте. Они имеют ограничение по домену, с которого происходит запрос.
Для теста получи новый приватный ключ и попробуй сделать запрос к своему API, поставив свой ключ в query-параметр wrapAPIKey.
 У меня вышел вот такой запрос:
У меня вышел вот такой запрос:
https://wrapapi.com/use/f1nn/test001/posts/1.0.0?wrapAPIKey=apiKey
Ответ сервера показан на скриншоте. Победа!
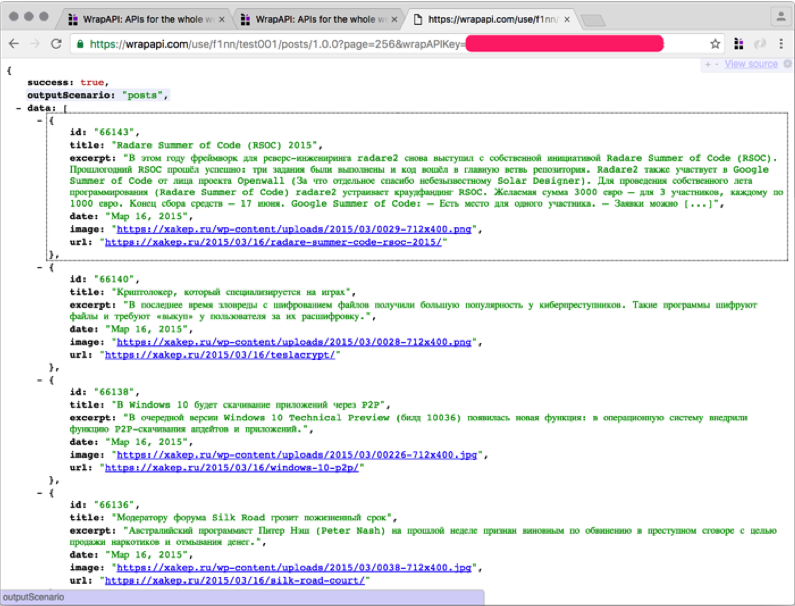
ВЫВОДЫ
Как видишь, WrapAPI — это мощный и очень эффективный способ построения парсеров веб-контента, который помогает обойтись без программирования или почти без него. Поначалу он кажется слишком перегруженным и нелогичным, но со временем ты убедишься, что он содержит ровно столько опций, сколько действительно нужно для эффективного скрэпинга веба. Сервис имеет гибкие параметры конфигурирования запросов, а постпроцессинг полученных ответов позволяет преобразовать практически любой HTTP response в красивый API. Дерзай, строй свои парсеры!


1 comments On Пишем парсер для веб сайта. Продолжение
На этом онлайн портале я нахожусь недолгое время:) Я случайно наткнулся на этот сайт, и нашел здесь большое количество интересной информации…
Я обязательно порекомендую его всем своим знакомым!