Kotlin — один из самых грамотно спроектированных, понятных и логичных языков за последние годы. С Kotlin вы можете начать разработку приложений для Android, не изучая язык, но маловероятно, что вы добьетесь мастерства только на практике. Эта статья представляет собой набор советов, которые помогут вам лучше понять язык и функции программы.

Null или не null? Kotlin
Null safety — одна из ключевых особенностей Kotlin. Язык гарантирует, что программист не может вызвать методы объекта, имеющего значение NULL, или передать этот объект в качестве аргумента другим методам по ошибке. На практике это означает, что система типов Kotlin разделена на две ветви, одна из которых содержит типы, допускающие значение NULL (со знаком вопроса в конце), а другая — типы, которые могут иметь только смысл значения.
Ты можешь написать такой код:
var string: String? = null
Но не такой:
var string: String = null
Не nullable-тип String просто не может содержать значение null.
Язык имеет ряд операторов для удобной и надежной работы с nullable-типами:
// Присвоить переменной length значение одноименного свойства string1 либо null
val length = string1?.length
// Выполнить код в блоке, только если string1 не null
string1?.let {
System.out.println(string1)
}
// Заверить компилятор, что в данный момент значение string1 не может быть null
string1!!.length
// Объявить переменную не nullable-типа и заверить компилятор,
// что она будет проинициализирована позже, до первого использования
lateinit var recyclerView: RecyclerViewВ целом удобная и понятная система. Но есть оператор, который может сделать код еще компактнее и красивее. Оператор Elvis оценивает выражение слева и, если его результат равен нулю, оценивает выражение справа. Это особенно полезно по двум причинам. Во-первых, его можно использовать для присвоения переменной значения по умолчанию:
val name: String = person.name ?: "unknown"Во-вторых, чтобы вернуть управление из функции, если значение определенной переменной равно null:
fun addPerson(person: Person) {
val name = person.name ?: return
}
Но есть и подводные камни. Допустим, у нас есть следующий код:
data?.let { updateData(data) } ?: run { showLoadingSpinner() }
Может показаться, что этот код делает то же самое, что и такой код:
if (data != null) {
updateData(data)
} else {
showLoadingSpinner()
}
Еще одна вещь, которую следует помнить о null safety, — это автоматическое выведение типов. Компилятор (и плагин среды разработки) Kotlin достаточно умен, чтобы понять тип переменной даже в самых сложных случаях. Но иногда он дает сбои.
Такое может быть при параллельной обработке данных. Возьмем следующий пример:
class Player(var tune: Tune? = null) {
fun play() {
if (tune != null) {
tune.play()
}
}
}
Среда разработки сообщает вам, что отображение типа не выводится, потому что это изменяемое свойство. Компилятор не может быть уверен, что между проверкой Tune на ноль и вызовом Play () другой поток не установит tune = null.
Чтобы это исправить, достаточно сделать так:
class Player(var tune: Tune? = null) {
fun play() {
tune?.play()
}
}Или так:
class Player(var tune: Tune? = null) {
fun play() {
tune?.let {
val success = it.play()
}
}
}Сбои могут возникать и при взаимодействии с кодом на Java. В Java понятия null safety нет, поэтому компилятор не может знать тип переменой наверняка. Kotlin решает эту проблему двумя способами:
- Компилятор Kotlin поддерживает практически все разновидности nullable-аннотаций, поэтому, если код аннотирован с помощью @NotNull и ему подобных аннотаций, компилятор будет считать, что аннотированная переменная не может быть null.
-
Для взаимодействия с Java (и другими языками для JVM) в Kotlin есть специальные типы с восклицательным знаком на конце (например, String!, Integer!). Это так называемые platform types, и при работе с ними Kotlin использует ту же логику, что и Java. Однако ее можно изменить, если указать тип напрямую:
val docBuilderFactory: DocumentBuilderFactory = DocumentBuilderFactory.newInstance()
Далее DocumentBuilderFactory будет считаться не nullable-переменной.
Типы Unit, Nothing, Any в Kotlin
Система типов Kotlin несколько отличается от системы типов Java и может вызвать у незнающего человека много вопросов. Наиболее проблемными обычно оказываются типы Unit и Nothing.
-
Unit — эквивалент типа void в Java. Другими словами, он нужен для того, чтобы показать, что функция ничего не возвращает. Unit наследуется от типа Any, а при работе с Java-кодом автоматически транслируется в void.
-
Nothing — субкласс любого класса (именно так), не позволяющий создать объект своего типа (конструктор приватный). Используется для представления результата исполнения функции, которая никогда не завершается (например, потому что она выбрасывает исключение). Пример:
public inline fun TODO(): Nothing = throw NotImplementedError() fun determineWinner(): Player = TODO() -
Any— родитель всех остальных классов. Аналог Object в Java.
Корутины и kotlin
Еще одна важная особенность Kotlin — корутины. Корутины позволяют писать неблокирующий параллельный код в последовательном стиле без обратных вызовов и фьючерсов. Сложно понять корутины с первого взгляда, а если использовать официальную терминологию, то еще сложнее. Поэтому первое, о чем мы поговорим, — это то, как работают корутины.
Как это работает в Android
Сами разработчики Kotlin называют легковесныет потоки корутинами. Это определение достаточно точное, но оно не поможет вам понять сопрограммы и правильно их использовать. Мы пойдем немного иначе и начнем с примера:
checkNetworkConnection(context) {
fetchData(url) {
updateUi(it)
}
}
Это довольно типичный код проверки интернет-соединения (в фоновом потоке). Затем, если результат положительный, он запускает функцию получения данных из сети (снова в фоновом потоке), а после получения отображает эти данные на экране (на этот раз в основном потоке приложения).
Чтобы выполнить все эти функции последовательно и не блокировать основной поток выполнения, используются лямбды. И хотя весь код выглядит не так страшно, в реальном проекте все эти обратные вызовы в конечном итоге приведут к беспорядку, называемому callback hell.
Корутины позволяют справиться с проблемой красиво и без лишнего кода:
CoroutineScope(Dispatchers.Main).launch {
val isConnected = checkNetworkConnection(context)
if (isConnected) {
val data = fetchData(url)
updateUi(data)
}
}
...
suspend fun checkNetworkConnection(context: Context) = withContext(Dispatchers.IO) {
...
}
suspend fun fetchData(url: Url) = withContext(Dispatchers.IO) {
...
}
Код стал последовательным, но остался неблокируемым. Пока мы ждем завершения работы checkNetworkConnection() и fetchData(), которые выполняются внутри так называемых suspend-функций в фоновом потоке, основной поток приложения может спокойно продолжать выполнение. В случае с Android это значит, что интерфейс приложения останется плавным.
Как такое возможно? Это очень просто — компилятор Kotlin по сути превращает второй пример кода в первый со всеми его обратными вызовами! Более конкретно, каждая функция приостановки становится объектом класса Continuation, который реализует конечный автомат, который приостанавливает выполнение кода и сохраняет состояние при вызове других функций приостановки. Но первого объяснения будет достаточно, чтобы понять сопрограммы. Только подумайте об этом примере.
Пулы потоков
Вторая характеристика корутин, о которой следует помнить, заключается в том, что корутины не привязаны к потокам Java и могут переключаться между ними. В приведенном выше примере для переключения между потоками используется функция withContext, которая принимает в качестве аргумента контекст корутины, который может передать диспетчеру. Диспетчер определяет пул потоков, в котором корутина продолжает свою работу.
Существует два стандартных пула потоков: связанные с вводом-выводом (Dispatchers.IO) и связанные сЦП (Dispa tchers.Default), а также основной поток приложения (Dispatchers.Main). Первый пул используется для блокировки таких операций, как получение данных из сети, чтение / запись на диск и т. Д. Это большой пул потоков с всегда свободными потоками, готовыми к выполнению отложенных операций. Второй пул предназначен для вычислений и состоит из небольшого количества потоков, равного количеству ядер процессора.
Это разделение не случайно. Выбор правильного пула потоков может серьезно повлиять на производительность приложения.
Также стоит упомянуть, что при переключении между потоками корутины всегда ставятся в очередь на выполнение. Это означает, что код будет запущен только после того, как предыдущий код завершит работу в этой очереди. Например, следующий код сначала отобразит 2, а затем 1:
override fun onCreate(savedInstanceState: Bundle?) {
CoroutineScope(Dispatchers.Main).launch {
System.out.println("1")
}
System.out.println("2")
}Причина в том, что код, который печатает 1, будет поставлен в очередь сразу после текущего блока кода, который заканчивается вызовом println («2»).
Этого можно избежать, используя Dispatchers.Main.immediate вместо Dispatchers.Main. Однако разработчики Kotlin категорически не советуют этого: могут возникать незначительные ошибки.
Вычисления в основном потоке
Описанную особенность, связанную с очередями потоков, можно использовать для создания весьма интересных эффектов. Лукас Лехнер (Lukas Lechner) в своей статье показал, как использовать корутины для выполнения тяжеловесных вычислений в основном потоке приложения.
Возьмем следующий код вычисления факториала, работающий в фоновом потоке:
private suspend fun calculateFactorialOnDefaultDispatcher(number: Int): BigInteger =
withContext(Dispatchers.Default) {
var factorial = BigInteger.ONE
for (i in 1..number) {
factorial = factorial.multiply(BigInteger.valueOf(i.toLong()))
}
factorial
}
Если вынести код этого метода из блока withContext() и вызвать его из основного потока приложения, то он закономерно подвесит интерфейс на несколько секунд. Но! Если при этом добавить в код вызов функции yield(), интерфейс никак не пострадает и останется плавным:
private suspend fun calculateFactorialInMainThreadUsingYield(number: Int): BigInteger {
var factorial = BigInteger.ONE
for (i in 1..number) {
yield()
factorial = factorial.multiply(BigInteger.valueOf(i.toLong()))
}
return factorial
}
Как это возможно? Все дело в том, как Android вызывает код отрисовки интерфейса в основном потоке приложения. Каждые 16 миллисекунд (при частоте обновления экрана в 60 герц) фреймворк Android добавляет новый Runnable (блок кода) с кодом обновления интерфейса в очередь исполнения основного потока приложения. Если основной поток не занят в это время другой работой, он исполнит этот код. В противном случае продолжится исполнение текущего кода, а операция обновления будет пропущена. Так получается пропуск кадра, а пропуск нескольких кадров подряд выглядит как фриз интерфейса.
Именно это должно было произойти при запуске предыдущего кода. Но не произошло благодаря вызову функции yield(). Она приостанавливает исполнение текущей корутины до получения следующего элемента (в данном случае числа). Приостановка корутины приводит к перемещению кода обработки следующего элемента в очереди исполнения. В итоге весь код вычисления факториала разбивается на множество маленьких блоков, которые помещаются в очередь исполнения вперемешку с кодом обновления экрана. Поток успевает выполнить несколько шагов вычисления факториала, затем код обновления UI, затем еще несколько шагов факториала и так далее.
Это канонический пример того, что называют словом concurrency в противовес параллельному вычислению. Мы по максимуму загружаем основной поток работой, при этом позволяя ему быстро переключаться между задачами. Факториал при таком подходе вычисляется примерно в два раза медленнее, зато интерфейс остается плавным даже без использования фоновых потоков.
Structured concurrency
Третья особенность корутин — то, что называется structured concurrency (об этом хорошо написал Роман Елизаров из команды Kotlin).
В коде в начале этого раздела корутина запускается с помощью функции CoroutineScope.launch. Это один из разработчиков корутин, которые генерируют новые корутины.
Кроме самой корутины, этот билдер также создает так называемый coroutine scope, представляющий собой своего рода область действия этой и всех порожденных ей корутин. Смысл существования областей действия в том, чтобы не дать корутинам утечь.
Чтобы продемонстрировать возможность такой утечки, возьмите следующий код. Он создает две корутины, используя билдер async. Эти сопрограммы одновременно выполняют фоновую загрузку двух изображений, а затем результаты их работы используются в родительской сопрограмме:
suspend fun loadAndCombine(name1: String, name2: String): Image {
val deferred1 = async { loadImage(name1) }
val deferred2 = async { loadImage(name2) }
return combineImages(deferred1.await(), deferred2.await())
}Красиво и удобно, но есть проблема. Если при загрузке изображения возникает исключение и одна из корутин завершает свою работу, вторая корутина продолжит работу, хотя она больше не нужна.
Structured concurrency решает эту проблему:
suspend fun loadAndCombine(name1: String, name2: String): Image =
coroutineScope {
val deferred1 = async { loadImage(name1) }
val deferred2 = async { loadImage(name2) }
combineImages(deferred1.await(), deferred2.await())
}Теперь обе корутины находятся в одной области видимости, и если одна из запущенных внутри корутин выдает исключение, все другие корутины в этой области будут автоматически завершены.
Теперь обе корутины находятся в одной области, и если одна из запущенных корутин запускает исключение, все остальные корутины в этой области будут автоматически закрыты.
Идея structured concurrency заключается в том, что разработчик создает новые «области» для всех связанных блоков кода. В Android это может быть модель просмотра, вариант использования, код запуска сети и т. Д. Вы можете создать CoroutineScope как свойство класса и использовать его во всем классе:
val scope = CoroutineScope(Dispatchers.Main)Как правильно завершать корутины
Есть три основных способа завершения корутин. Первый — через завершение coroutine scope, которому принадлежат корутины:
val job1 = scope.launch { … }
val job2 = scope.launch { … }
scope.cancel()Второй — прямое завершение отдельно взятых корутин:
val job1 = scope.launch { … }
val job2 = scope.launch { … }
job1.cancel()
job2.cancel()Третий — завершение всех корутин, принадлежащих одному scope:
val job1 = scope.launch { … }
val job2 = scope.launch { … }
scope.coroutineContext.cancelChildren()Вроде бы все просто. Но есть несколько неочевидных моментов:
- Завершение корутины должно быть кооперативным. Сам по себе метод
cancel()не завершает корутину, а лишь посылает ей сигнал завершения. Корутина должна сама проверить, пришел ли он, используя свойствоJob.isActiveи методensureActive(). Если сигнал завершения получен, первое будет содержать false, второй выброситCancellationException. - Все стандартные suspend-функции пакета
kotlinx.coroutines(withContext(),delay()и так далее) умеют реагировать на сигнал завершения, поэтому при их использовании программисту необязательно делать это самостоятельно. - При завершении корутины ее родитель получает исключение
CancellationException. - Завершенный CoroutineScope больше нельзя использовать для запуска корутин.
Каналы, потоки и чистые функции
Kotlin не только упрощает написание многопоточного кода, но и делает его более надежным. Его разработчики учли ошибки Java и сделали все, чтобы избежать проблем с разделением данных и блокировкой, которые присущи классическому подходу к написанию многопоточных приложений.
Во-первых, Kotlin и его стандартная библиотека четко различают модифицируемые и немодифицируемые данные, а компилятор и среда разработки всегда указывают, что переменная может стать неизменной. Все это приводит к написанию кода в функциональном стиле, когда каждая функция выполняет только одну задачу, не изменяет входные данные и не изменяет поля класса. Хороший многопоточный код Kotlin — это конвейер с источником данных в начале, функциями обработки в середине и потребителем в конце.
Однако у этого подхода есть проблема: он подходит только для задач, где каждый элемент конвейера возвращает всю коллекцию данных целиком, а сама коллекция не очень большая. Но что, если наш поток зависает в фоновом режиме на время жизни приложения и время от времени получает от сервера данные, которые каким-то образом нужно обрабатывать в других потоках?
Классическим решением этой проблемы в стиле Java было бы создание специального объекта, к которому все потоки могут обращаться для записи или чтения данных. И все это принесет с собой те же проблемы с блокировкой, решив проблемы синхронизации потоков.
Kotlin предлагает другой путь: стиль программирования CSP, аналогичный используемому в языке Go. Идея проста: мы не передаем данные между потоками, но канал связи и поток записывают данные в него, в то время как другие читают их.
Выглядеть все это может примерно так:
val channel = Channel<Int>()
launch {
for (x in 1..5) channel.send(x * x)
channel.close()
}
for (y in channel) println(y)
println("Done!")Этот код создает канал, а затем запускает корутину, которая записывает пять цифр в строку для этого канала, а затем закрывает ее. Другая корутина считывает данные из трубки и отображает их. Предоставленный здесь канал не имеет буфера (есть также буферы), что означает, что корутина записи будет приостановлена при попытке записать второе значение в канале. И сразу после этого будет запущена корутина, которая считывает данные.
Каналы — эффективное средство синхронизации и передачи данных. Разработчики Kotlin приложили немало усилий, чтобы сделать их неблокирующими и высокопроизводительными. Но каналы подходят не для всех ситуаций. Они хорошо работают, когда корутина, дающая данные, живет своей собственной жизнью, а сами данные могут появляться без спроса. Но если все, что вам нужно сделать, это начать сбор ограниченного количества данных, которые могут поступать по частям, тогда вам следует обратить внимание на flow.
Flow
Допустим, у нас есть несколько фрагментов данных, которые можно вводить через определенные промежутки времени. Чтобы получить эти данные, обработать их и отправить дальше, мы можем написать функцию, которая создает поток (по сути, «поток данных»):
fun doSomething(): Flow<Int> = flow {
for (i in 1..5) {
delay(100)
emit(i)
}
}В этом случае функция «выпускает» пять объектов Int в поток данных с интервалом в 100 миллисекунд. Обратите внимание, что flow— это suspend-функция, которая может запускать другие suspend-функции (в данном случае delay ()). Но сама функция doSomething () не приостановлена. Это важно.
Теперь нам нужно эти данные собрать. Мы можем сделать это с помощью такого кода:
val something = doSomething()
scope.launch {
something.collect { value -> System.out.println(value) }
}Здесь мы вызываем функцию doSomething() вне корутины, но функцию collect() — внутри корутины. Все дело в том, что при вызове doSomething() ничего не происходит, функция сразу возвращает управление. И только после вызова collect() начинает работать определенный внутри функции код. Другими словами, вызов collect() запускает код функции doSomething() в рамках текущей корутины, а после получения последнего элемента возвращает управление.
Создать поток данных можно и другими способами, например с помощью метода asFlow():
listOf(1,2,3).asFlow()
(1..3).asFlow()Завершают поток данных несколькими способами — от вызова collect() до методов типа first(), fold(), toList(), знакомых тебе по работе с коллекциями.
Поток данных можно трансформировать, чтобы получить новый поток данных с помощью методов map(), filter(), take(). Можно объединить несколько потоков в один с помощью методов zip(), merge() и combine() и поменять контекст исполнения (например, диспетчер) с помощью flowOn():
resultsScope.launch {
searchSources
.filter { it.isEnabled }
.map { it.search(searchVariants) }
.merge()
.flowOn(Dispatchers.Default)
.collect {
resultsUi.showResults(it.name, it.results, it.type)
}
}Это код функции поиска из реального приложения. Она берет несколько источников данных для поиска (searchSources — это список объектов), отфильтровывает отключенные источники, а затем запускает на каждом из них функцию поиска (search()), которая возвращает Flow. Далее несколько потоков данных объединяются с помощью merge(). В конце потоки запускаются, а их результаты отображаются на экране. Благодаря использованию функции flowOn() вся обработка потоков данных происходит в фоне, но результаты будут показаны в UI-потоке приложения.
StateFlow
Наконец, давайте поговорим о корутинах в StateFlow, совершенно новом механизме для хранения состояний на основе потока.
StateFlow позволяет различным компонентам приложения изменять состояние и реагировать на изменения в этом состоянии. На Android StateFlow можно использовать как более продвинутый аналог LiveData.Об этом есть хорошая понятная статья «StateFlow, End of LiveData?». Приведу здесь выжимку кода.
Напишем следующий код ViewModel:
@ExperimentalCoroutinesApi
class MainViewModel : ViewModel() {
private val _countState = MutableStateFlow(0)
val countState: StateFlow<Int> = _countState
fun incrementCount() {
_countState.value++
}
fun decrementCount() {
_countState.value--
}
}Теперь давайте создадим действие, используя эту модель. Действие будет состоять из TextView с числом и двумя кнопками для увеличения и уменьшения этого числа:
class MainActivity : AppCompatActivity() {
private val viewModel by lazy {
ViewModelProvider(this)[MainViewModel::class.java]
}
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
initCountObserver()
initView()
}
}
private fun initCountObserver() {
lifecycleScope.launch {
viewModel.countState.collect { value ->
textview_count.text = "$value"
}
}
}
private fun initView() {
button_plus.setOnClickListener(::incrementCounter)
button_minus.setOnClickListener(::decrementCounter)
}
private fun incrementCounter(view: View) {
viewModel.incrementCount()
}
private fun decrementCounter(view: View) {
viewModel.decrementCount()
}Это все. Нажатие кнопки с номером изменения изменит состояние ViewModel, что, в свою очередь, приведет к автоматическому изменению TextView. И все это работает с жизненным циклом бизнеса с помощью lifecycleScope.
Функции
Функции в Kotlin более мощные, чем в Java (особенно когда мы говорим о Java 7 и ниже).Так же функции могут быть объявлены вне классов, вложены друг в друга, иметь предопределенные значения аргументов и принимать другие функции в качестве аргументов. Данные функции можно объявлять с помощью ключевого слова inline, поэтому для повышения производительности тело функции будет встроенным, а не вызовом. Также функции могут быть функциями фрейма и расширения. Мы сосредоточимся на последних двух типах функций, как на наиболее интересных и недопонятых.
Функции-расширения
Функции расширения — это методы, которые вы можете добавить к любому классу, независимо от того, есть ли у вас доступ к его исходному коду или нет. Например:
fun String.isDigit() : Boolean {
...
}
val sting = "12345"
val result = string.isDigit()Функции-расширения улучшают читаемость кода. Строка string.isDigit() выглядит явно лучше, чем isDigit(string), и тем более лучше, чем StringUtils.isDigit(string). Они позволяют сделать класс легче и удобнее для чтения и понимания. Если, например, какой-то набор приватных методов класса нужен только одному публичному методу, их вместе с публичным методом можно вынести в расширения. Они облегчают написание кода, так как IDE будет автоматически подсказывать, какие методы и функции-расширения есть у класса.
Однако при неправильном использовании функции- расширения могут вызвать множество проблем. Большинство этих проблем возникает, когда разработчики пытаются использовать функции расширения в своих классах вместо создания стандартных методов.
Есть два случая, когда это будет оправданно.
- **Inline-функции++. Существует известная рекомендация, что функции высшего порядка стоит помечать с помощью ключевого слова
inline. Тогда компилятор включит их код прямо на место вызова, вместо того чтобы совершать настоящий вызов. В Kotlin сделать инлайновыми методы класса нельзя, но можно функции-расширения. - Объект со значением null. В отличие от классических методов, функции-расширения можно создать даже для nullable-типов. Например:
fun CharSequence?.isNullOrBlank(): Boolean {
...
}
val string : String? = "abc"
val result = string.isNullOrBlank()Интересно, что функциями-расширениями в Kotlin также могут быть лямбды, они называются лямбдами с ресивером. Например, следующая функция принимает в качестве аргумента лямбду:
fun doSomething(lambda: () -> Unit) {А такая — лямбду с ресивером:
fun doSomething(lambda: String.() -> Unit) {
...
}Вторая лямбда будет выполнена в контексте объекта указанного класса. Например:
fun buildString(actions: StringBuilder.() -> Unit): String {
val builder = StringBuilder()
builder.actions()
return builder.toString()
}
val str = buildString {
append("Hello")
append(" ")
append("world")
}Лямбды с ресивером активно используются в стандартной библиотеке Kotlin. Например, функция-расширение apply использует лямбду с ресивером, чтобы запустить код лямбды в контексте объекта, для которого была вызвана функция apply:
button.apply{
text = "Press me"
textSize = 17f
}Еще более интересный пример — функция use, которую можно вызвать для объектов, реализующих интерфейс Closable, чтобы автоматически вызвать метод close() после выполнения кода лямбды:
fun main () {
val file = File("file.txt")
file.printWriter().use {
it.println("Hello World")
}
}В данном случае close() будет вызван сразу после записи строки Hello world в файл.
Инфиксные функции
Наверное, самый удачный пример применения инфиксных функций был приведен в статье Kotlin: When if-else is too mainstream. Это краткая заметка о том, как создать более удобный аналог оператора if-else:
val condition = true
val output = condition then { 1 + 1 } elze { 2 + 2 }Функции then и elze в данном примере инфиксные. По сути, это обычные функции-расширения, которые можно вызвать, используя пробел вместо точки:
infix fun <T>Boolean.then(action : () -> T): T? {
return if (this)
action.invoke()
else null
}
infix fun <T>T?.elze(action: () -> T): T {
return if (this == null)
action.invoke()
else this
}Вызов объектов
Kotlin позволяет вызывать объект как функцию. Все, что нужно, — добавить в код его класса метод invoke().
class Manager {
operator fun invoke(value:String) {
prinln(value)
}
}
val manager = Manager()
manager("Hello, world!")Возврат двух значений из функции
К сожалению (или к счастью), функции в Kotlin не могут возвращать два значения. Однако здесь есть парные и тройные классы, чтобы упаковать несколько значений в один класс. Например, мы можем написать такую функцию:
fun getFeedEntries() : Pair<List<FeedEntry>, String> {
return emptyList to 100
}А затем вызвать ее и получить два значения:
val pair = getFeedEntries()
val list = pair.first
val status = pair.secondЧтобы убрать лишний код, можно использовать оператор деструкции:
val (list, status) = getFeedEntries()Аспектно ориентированное программирование
Парадигма аспектно-ориентированного программирования (АОП) позволяет помещать код в отдельные модули, что проблематично для разделения с другими подходами к программированию: ведение журнала, обработка исключений, кэширование и контроль доступа. Вся эта функциональность называется сквозной.
Стандартные фреймворки аспектно ориентированного программирования, такие как AspectJ, позволяют вынести такую функциональность в отдельные модули, используя аннотации:
@CachedBy(key = Customer::getId)
fun getAddress(
customer: Customer
): String {
return customer.address
}В этом примере customer.address будет закеширован автоматически благодаря аннотации @CachedBy.
Единственная проблема с этой аннотацией заключается в том, что она не так очевидна и проста в использовании, как обычная функция. К счастью, Kotlin позволяет получить некоторые преимущества АОП без использования специальных фреймворков и аннотаций:
fun getAddress(
customer: Customer
): String = cachedBy(customer.id) {
customer.address
}Классы
Как и функции, классы в Kotlin имеют более широкие возможности в сравнении с аналогами из Java. Классы можно вызывать на манер обычных функций, их можно делать инлайновыми, чтобы компилятор развернул их на месте использования. Здесь есть data-классы для хранения данных (для них будут автоматически созданы методы toString(), hashCode() и copy()), также изолированные (sealed) классы, которые идеально подходят для хранения состояния.
Изолированные классы
Sealed-класс в Kotlin — своего рода enum на стероидах. Он может иметь ограниченное количество потомков, все из которых должны быть объявлены в том же файле. Взглянем на следующий пример:
sealed class NetworkResult
data class Success(val result: String): NetworkResult()
data class Failure(val error: Error): NetworkResult()
viewModel.data.observe(this,
Observe<NetworkResult> { data ->
data ?: return@Observer
when (data) {
is Success -> showResult(data.result)
is Failure -> showError(data.error)
}
})Здесь объявляются sealed-класс NetworkResult и два его потомка: Success и Failure. Затем они используются для проверки результата операции и принятия мер на основе этого результата. Мы можем быть уверены, что данные не могут быть ничем иным, кроме Success и Failure, они даже не могут быть NetworkResult, поскольку сам sealed-класс всегда является абстрактным.
Sealed-классы идеальны для хранения состояний. Они также подходят для реализации самих конвейеров обработки информации (Railway Oriented Programming), о которых мы говорили в разделе о сопрограммах:
tokenize(command.toLowerCase())
.andThen(::findCommand)
.andThen { cmd -> checkPrivileges(loggedInUser, cmd) }
.andThen { execute(user = loggedInUser, command = cmd, timestamp = LocalDateTime.now()) }
.mapBoth(
{ output -> printToConsole("returned: $output") },
{ error -> printToConsole("failed to execute, reason: ${error.reason}") }
)Это пример с GitHub-страницы kotlin-result, крошечной библиотеки, реализующей тип Result на базе sealed-классов.В этом примере каждая последующая команда возвращает значение sealed-класса Result (ошибка или значение), но ошибки обрабатываются только на последнем этапе выполнения. Если в одной из первых команд произошла ошибка, она просто будет перенаправлена в конец, иначе результат будет обработан.
Делегирование
Один из ключевых постулатов современного ООП-программирования гласит: предпочитайте делегирование наследованию. Это значит, что вместо наследования от какого-либо класса лучше включить инстанс этого класса в другой класс и вызывать его методы при вызове одноименных методов этого класса:
class Class1() {
fun method1() { ... }
fun method1() { ... }
}
class Class2(firstClass: Class1) {
private val class1 = firstClass
fun method1() { firstClass.method1() }
fun method2() { firstClass.method2() }
}Зачем это нужно? Для того, чтобы избежать проблем, когда методы класса-родителя вызывают друг друга. Если method1() вызывает method2(), то, переопределив второй метод, мы сломаем работу первого. Делегирование решает эту проблему, так как Class1 и Class2 остаются не связанными друг с другом.
С другой стороны, делегирование усложняет код, и поэтому в Kotlin есть специальное ключевое слово by, сильно упрощающее жизнь разработчика. Благодаря ему реализовать второй класс можно с помощью всего одной строки:
class Class2(firstClass: Class1) : Class1 by firstClassЭто действительно все. Компилятор Kotlin автоматически преобразует эту строку в аналог реализации Class2 из первого примера.
Kotlin также позволяет делегировать реализацию свойств. В следующей записи используется стандартный делегат lazy, инициализирующий переменную при первом обращении к ней:
val orm by lazy { KotlinORM("main.db") }Еще более интересно работает делегат map, позволяющий магическим образом взять значения из хешмапа.
class User(val map: Map<String, Any?>) {
val name: String by map
val age: Int by map
}
val user = User(mapOf(
"name" to "John Doe",
"age" to 25
))
println(user.name) // "John Doe"
println(user.age) // 25Кроме lazy и map, стандартная библиотека Kotlin включает в себя еще три стандартных делегата:
- nutNull — аналог ключевого слова
lateinitс более широкими возможностями; - observeble — позволяет выполнить код в момент чтения или записи переменной;
- vetoable — похож на observeble, но срабатывает перед записью нового значения и может запретить изменение.
Ну и конечно же, любой разработчик может создать собственный делегат. Это всего лишь класс c реализацией операторов getValue() и setValue():
class Delegate {
operator fun getValue(thisRef: Any?, property: KProperty<*>): String {
return "$thisRef, thank you for delegating '${property.name}' to me!"
}
operator fun setValue(thisRef: Any?, property: KProperty<*>, value: String) {
println("$value has been assigned to '${property.name}' in $thisRef.")
}
}INFO
Ключевой программист Kotlin Андрей Бреслав неоднократно заявлял, что не стал бы реализовывать делегирование классов, если бы у него была возможность вернуться в прошлое. Эта функция оказалась полезной, но слишком сложной для реализации и противоречит новым функциям Java.
Коллекции
Kotlin — это независимый язык, поэтому он поставляется с чрезвычайно компактной стандартной библиотекой. Практически все API, примитивы и реализации коллекций пришли из Java. Однако благодаря функциям расширения коллекции Kotlin намного более продвинуты, поддерживают гораздо больше различных операций и имеют неизменяемые эквиваленты, такие как MutableList и List.
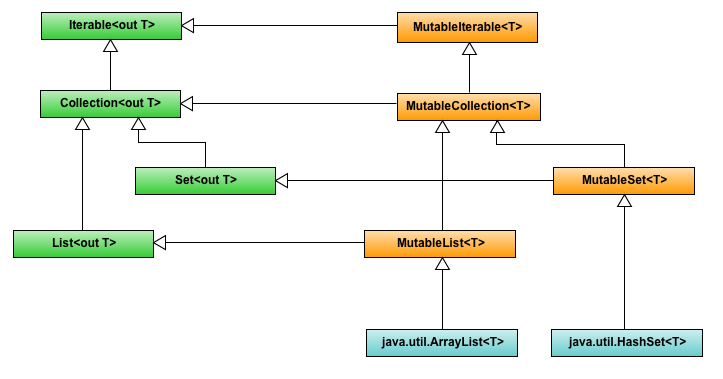
Одна из самых мощных особенностей коллекций Kotlin — встроенные средства функционального программирования. В Kotlin можно сделать, например, так:
val allowed = getPeople()
.filter { it.age >= 21 }
.map { it.name }
.take(5)Этот код возьмет список объектов People, возвращенный getPeople(), выбросит из него все объекты, значение поля age которых меньше 21, затем преобразует этот список в список строк, содержащий имена, и вернет первые пять строк.
Особая прелесть этого кода в том, что он не требует использования каких-либо новых конструкций, таких как потоки Java 8, и выполняет всю обработку с использованием стандартных итераторов. И в этом его проблема: каждая функция возвращает новый список, что может быть очень затратным с точки зрения производительности.
Поэтому в Kotlin также существует Sequence — ленивый аналог Iterable:
val allowed = getPeople().asSequence()
.filter { it.age >= 21 }
.map { it.name }
.take(5)
.toList()В отличие от предыдущего, этот код будет обрабатывать каждый элемент в списке отдельно, пока не будет пять элементов. Теоретически это должно серьезно улучшить производительность коллекции, и IDEA / AndroidStudio даже предлагает преобразовать коллекцию в Sequence.
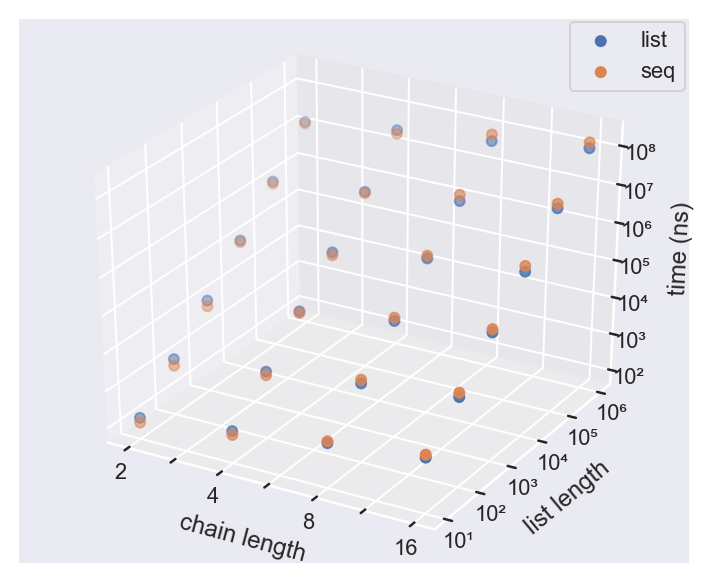
В реальности же все несколько сложнее. Разработчик AJ Alt провел собственные тесты прозводительности, используя следующий код:
list.filter { true }.map { it }.filter { true }.map { it }И код, использующий Sequence:
list.asSequence()
.filter { true }.map { it }.filter { true }.map { it }
.toList()Результаты были почти такими же. Кроме того, последовательности дают очень незначительный прирост производительности в коротких списках и проигрывают в очень длинных списках. Что еще интереснее, если добавить в код небольшую задержку, имитирующую реальные вычисления, разница полностью исчезнет.
Есть, однако, два случая, в которых последовательности выигрывают с очень большим отрывом: методы find и first. Происходит так потому, что поиск для последовательностей останавливается после того, как нужный элемент найден, но продолжается для списков.
Бесполезные оптимизации
За время существования Kotlin в интернете появилось большое количество утверждений о производительности языка и советов по оптимизации. Автор статьи Kotlin’s hidden costs — Benchmarks проверил многие из них и получил следующий результаты:
- Лямбды Kotlin быстрее своего аналога в Java 8 на 30% (вне зависимости от использования ключевого слова inline).
- Объекты-компаньоны (companion object) не создают никакого оверхеда, а доступ к ним даже быстрее, чем к статическим полям и методам в Java.
- Вложенные функции не создают оверхеда, они даже немного быстрее обычных.
- Повсеместные проверки на null не создают оверхеда, код получается более быстрый, чем код на Java.
- Передача массива как аргумента функции, ожидающей неопределенное число аргументов (vararg), действительно замедляет исполнение кода в два раза.
- Делегаты работают на 10% медленней своей наиболее эффективной эмуляции на языке Java.
- Скорость прохода по диапазону (range) не зависит от того, вынесен он в отдельную переменную или нет.
- Вынесенный в константу range всего на 3% быстрее аналога в коде.
- Конструкция
for (it in 1..10) { ... }в три раза быстрее конструкции(1..10).forEach { ... }.
Библиотека Andtroid-ktx
Вскоре после того, как Kotlin был объявлен стандартным языком платформы Android, Google выпустила библиотеку Android-ktx с множеством полезных функций, расширяющих стандартный Android SDK. Автор статьи Exploring KTX for Android подготовил справку по этим функциям. Я представлю некоторые из них здесь.
// Модификация настроек
sharedPreferences.edit {
putBoolean(key, value)
}
// Работа с временем и датами
val day = DayOfWeek.FRIDAY.asInt()
val (seconds, nanoseconds) = Instant.now()
val (hour, minute, second, nanosecond) = LocalTime.now()
val (years, month, days) = Period.ofDays(2)
// Создание бандлов
val bundle = bundleOf("some_key" to 12, "another_key" to 15)
// Создание Content Values
val contentValues = contentValuesOf("KEY_INT" to 1, "KEY_BOOLEAN" to true)
// Работа с AtomicFile
val fileBytes = atomicFile.readBytes()
val text = atomicFile.readText(charset = Charset.defaultCharset())
atomicFile.writeBytes(byteArrayOf())
atomicFile.writeText("some string", charset = Charset.defaultCharset())
// SpannableString
val builder = SpannableStringBuilder(urlString)
.bold { italic { underline { append("hi there") } } }
// Трансформация строки в URI
val uri = urlString.toUri()
// Работа с Drawable и Bitmap
val bitmap = drawable.toBitmap(width = someWidth, height = someHeight, config = bitMapConfig)
val bitmap = someBitmap.scale(width, height, filter = true)
// Операции над объектом View
view.postDelayed(delayInMillis = 200) { ... }
view.postOnAnimationDelayed(delayInMillis = 200) { ... }
view.setPadding(16)
val bitmap = view.toBitmap(config = bitmapConfig)
// ViewGroup
viewGroup.forEach { doSomethingWithChild(it) }
val view = viewGroup[0]
// Отступы
view.updatePadding(left = newPadding)
view.updatePadding(top = newPadding)
view.updatePadding(right = newPadding)
view.updatePadding(bottom = newPadding)Выводы
В этой статье описаны лишь некоторые из интересных и неочевидных возможностей Kotlin. Это своего рода сборник быстрых советов, которые я упустил при изучении языка Kotlin. Надеюсь, они хорошо вам послужат.